



Lepton Motion Pro II B860iをレビュー
Core Ultra 7 270K Plus&RTX 5060 Ti 16GBで映像編集にローカルLLM、ゲームも快適なPC!まるっこいずんぐりボディーもカワイイ
2026年05月19日 10時00分更新
LM StudioでローカルLLMを動かしてみる
動画編集向けというだけあって、高性能なCPUとビデオカードを搭載しているが、そうなると試してみたくなる作業が生成AIのLLM(大規模言語モデル)だ。これだけの性能があれば、ローカルで動作するものも実用的な速度で動いてくれる。
とはいえ、実際どのくらいの性能があるかは気になるところ。そこで、手軽に試せる「LM Studio」を使い、モデルに「Gemma 4 E4B」を選んだ場合の性能を見てみよう。
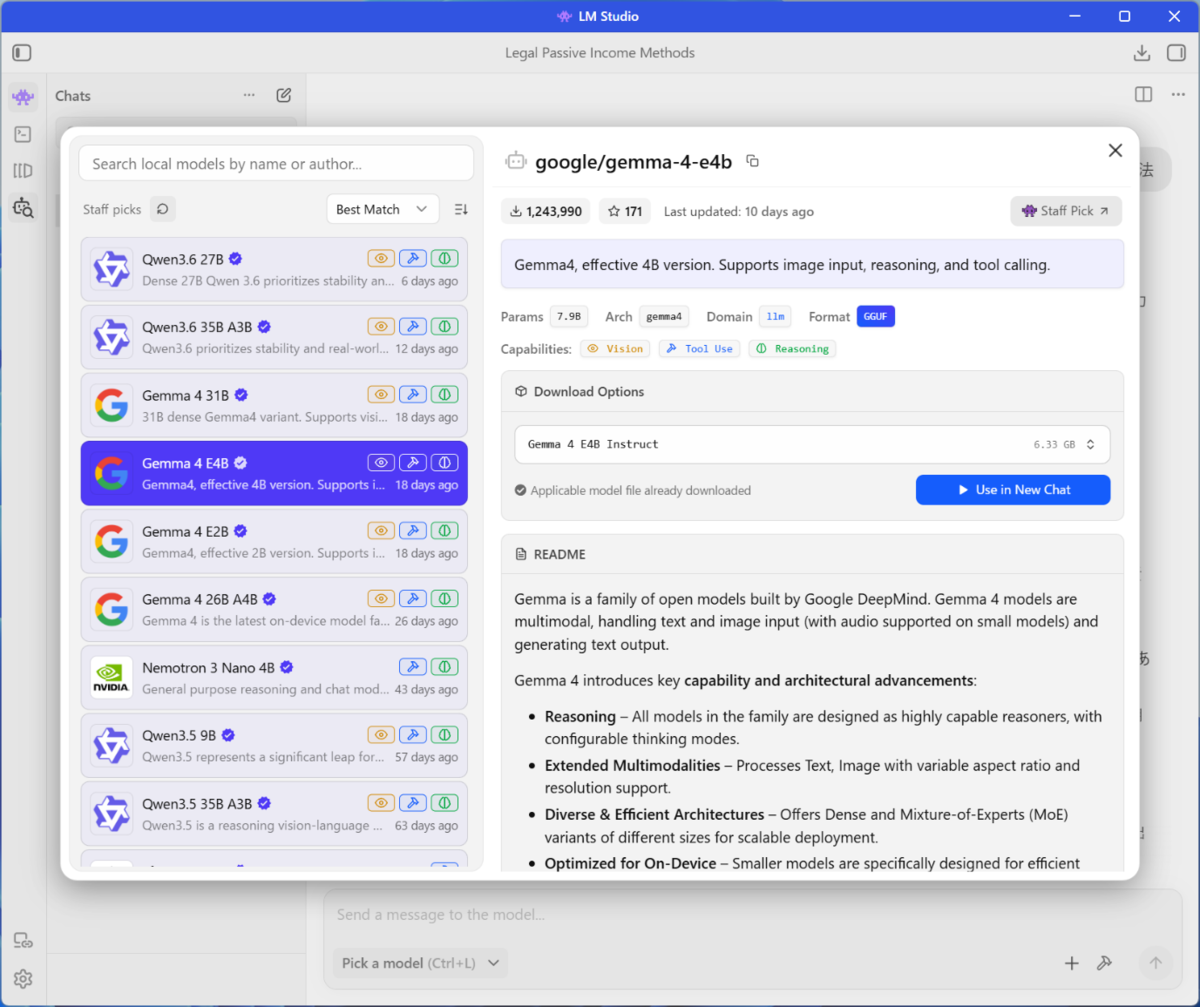
まずはモデルに「Gemma 4 E4B」を選択してみた
検証では適当な質問をして、どのくらいの速度で返答してくれるのかをチェックした。今回は「合法的な不労所得を得る方法は?」という質問をしてみた。
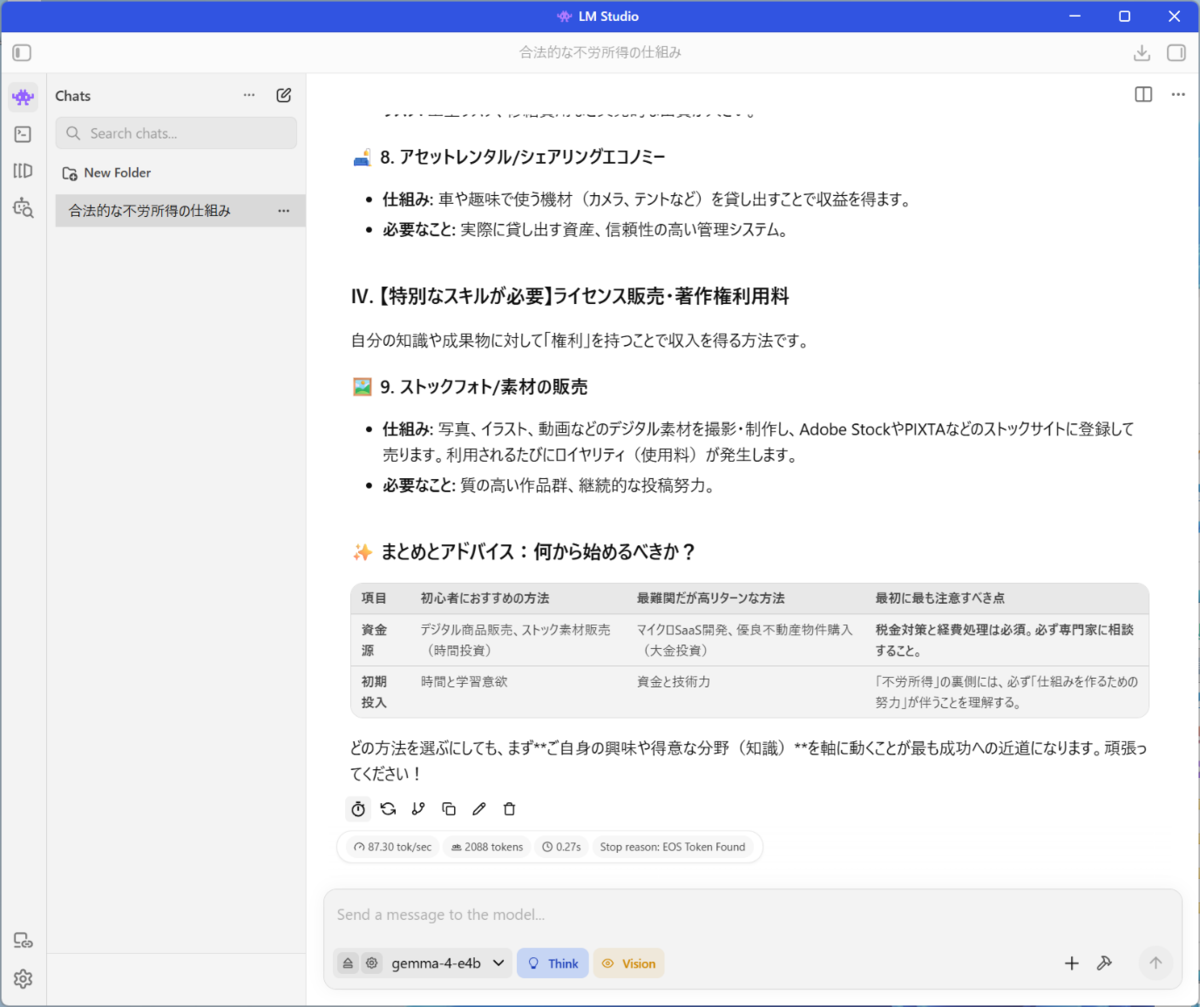
最後に表示される時計のアイコンにカーソルを重ねると、1秒あたりのトークン数(tok/sec)が見られる
いくつか異なる質問もしてみたが、いずれも大体87~88tok/secといったところ。実際の体感だと、質問をしてから5~6秒ほど考え、そのあとは読む速度の数倍のペースで回答が作成されている、という感じだ。このくらいの速度であれば、ストレスなく使えるだろう。
より精度を高めたければ、よりパラメーターサイズの大きなモデルを使うといい。試しにモデルとして「Gemma 4 31B」を使い、同じ質問をしてみたところ、最初の待ち時間が約1分半にまで伸び、そのあとの回答ペースも読む速度より若干遅いくらいにまで落ちてしまった。この速度だと、気軽に質問するという用途で使うのはさすがに苦しいと感じた。
ちなみに、GPUメモリーの使用量をタスクマネージャーで確認してみたところ、Gemma 4 E4Bの場合は5.6GBだが、Gemma 4 31Bでは15.6GBにまで上昇していた。これがGeForce RTX 5060 Ti(VRAM 16GB)の限界だろう。
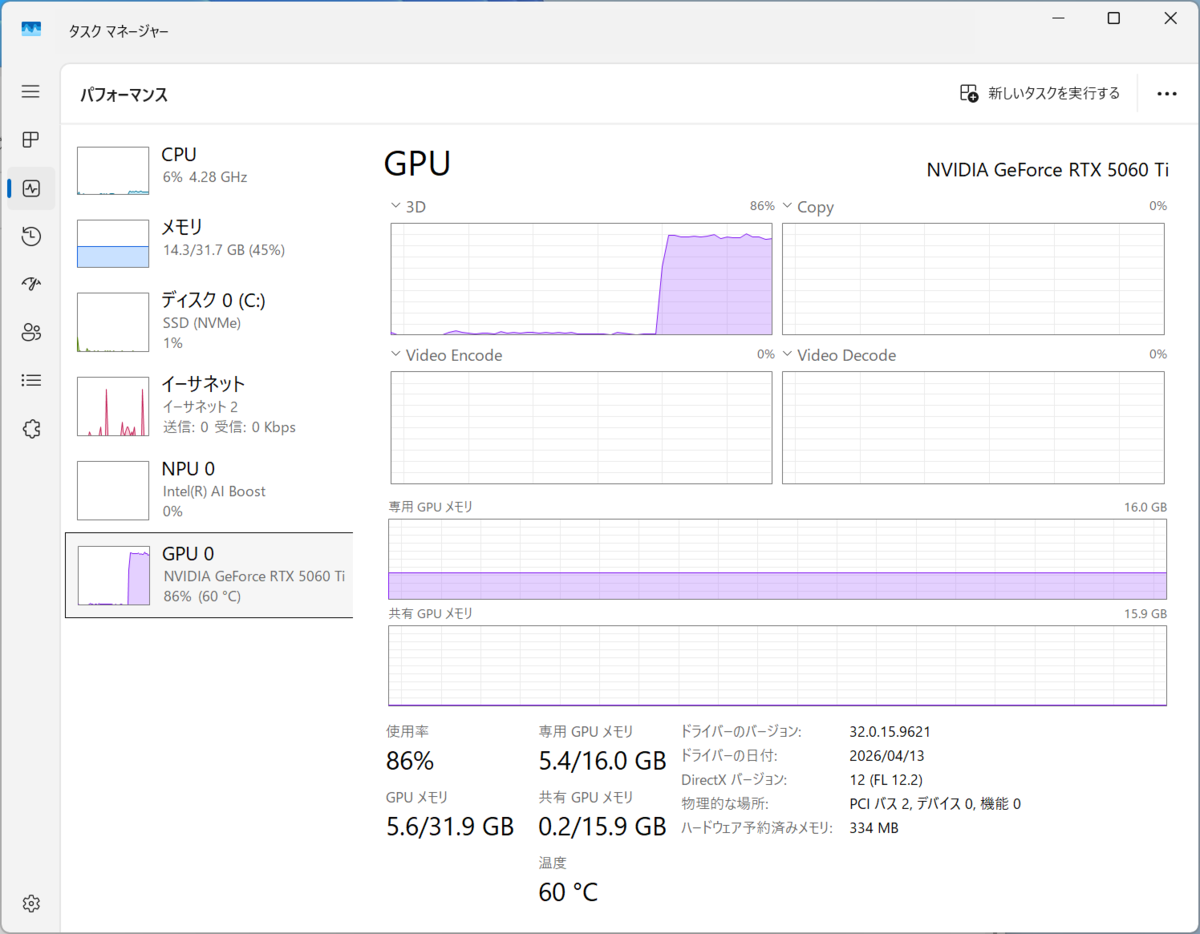
Gemma 4 E4Bを使用した場合のGPUの様子
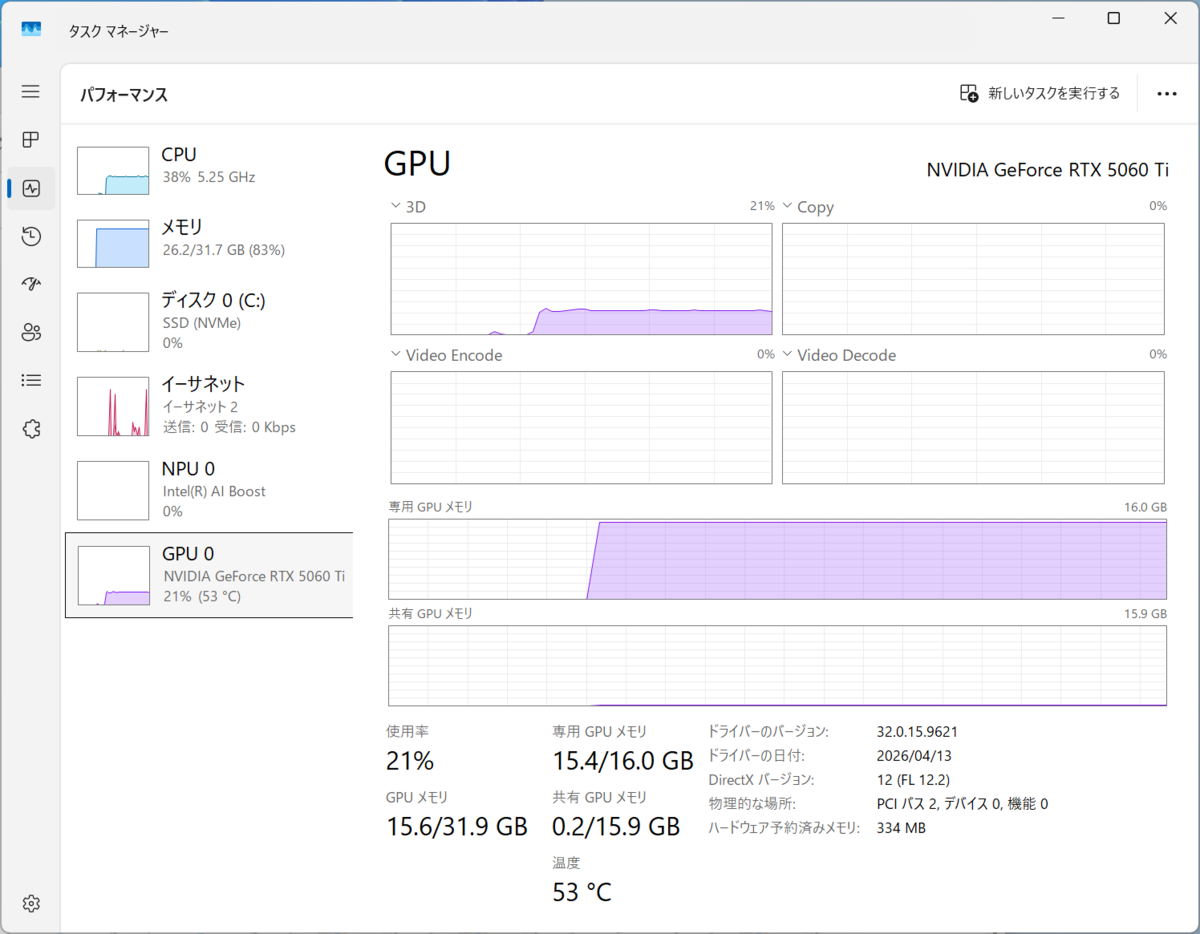
Gemma 4 31Bを使用した場合のGPUの様子
また、Gemma 4 E4BだとGPUでほぼ処理が行われているのに対し、Gemma 4 31BだとCPUの負荷が大きく上昇しているという違いもあった。ローカルLLMはなかなかに興味深い。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります