



TensorコアはRTコアとの同時実行が可能に
AmpereのTensorコアは第3世代のものが使われているが、主な強化点はスパースモデリングにも対応した、という点だ。ディープラーニングは多量の学習データが必要だが、十分な量のデータが用意できなければ役に立たない。スパースモデリングはSparse(まばらな)の意味から想像がつく通り、少ないデータから推論するための技法だ。スパースモデリングで処理をする場合、従来のデンスモデリングを使った処理よりも2倍のパフォーマンスが期待できる。ただし、このあたりで筆者の理解を超越してきたので、ここまでとしておきたい。
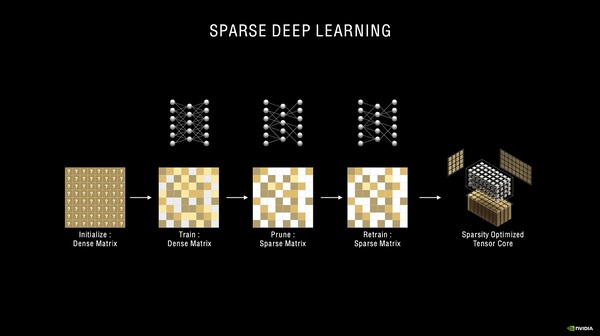
最初はデンスなデータでトレーニングし、枝刈り(Pruning)でスパースモデリングに移行。計算量が減るので処理が高速化できるというわけだ
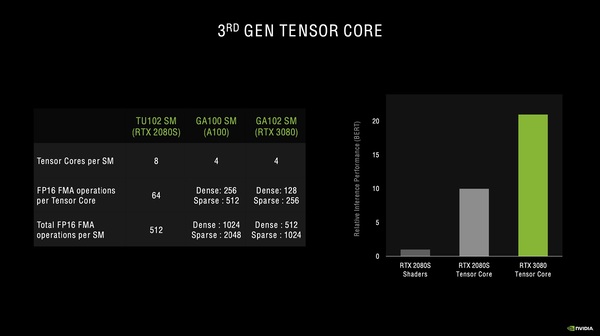
Ampere(RTX 3080)のTensorコアはTuring(RTX 2080 SUPER)よりもSMあたりのコア数は減っているが、FP16の積和算が実行できる数はTuringよりも大きい。Tensorコア1基あたりで見ると、Turingが64オペレーションだが、Ampere(RTX 3080)はデンスなら128、スパースなら256オペレーションが実行できるという
GeForce RTX 30シリーズを主にゲーミング用途で買う我々にとって、TensorコアはAIを使って低解像度のレンダリングから解像度の高いアウトプットを得る「DLSS」や、レイトレーシング時のAIデノイズ処理のためにあるコアだ。特にレイトレーシング処理をさせる場合は、RTコアとTensorコアを活用することで処理時間(フレームタイム)を短くできる、というのはTuring世代からもたらした概念だ。
しかし、TuringではRTコアとTensorコアを同時に動かすことができないという制約を抱えていた。RTコアで処理し、しかるべき処理をした後でTensorコアに引き渡す必要があった。それに対して、Ampereではハードウェア的な改良を加えることで、RTコアとTensorコアの同時処理ができるようになった。このRTコアとTensorコアの同時処理がうまく使える程度にゲームが作り込んであれば、レイトレーシング使用時における性能低下もかなり軽減されるはずだ。今後のゲーム側の対応を注視したい。
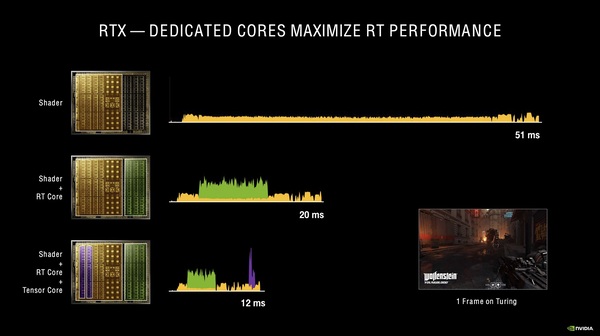
レイトレーシングを使った1フレームをレンダリングするのに、CUDAコアだけを使うと51ミリ秒(≒19fps)かかるが、RTコアを使えば20ミリ秒(≒50fps)、RTコアとTensorコアを併用すれば12ミリ秒(≒83fps)「くらいになる」という主張
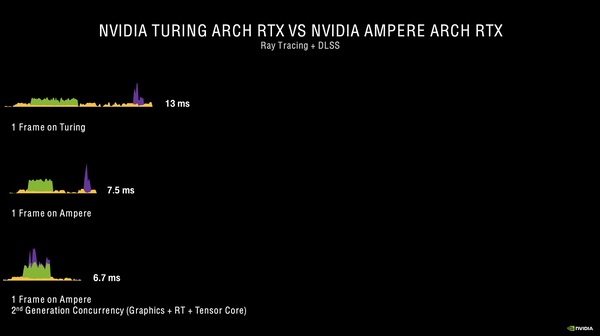
TuringではRTコアとTensorコアを使った時13ミリ秒かかるフレームが、Ampereで実行すれば7.5ミリ秒に短縮する。そして、RTコアとTensorコアの同時処理を使えば、6.7ミリ秒まで短縮するという
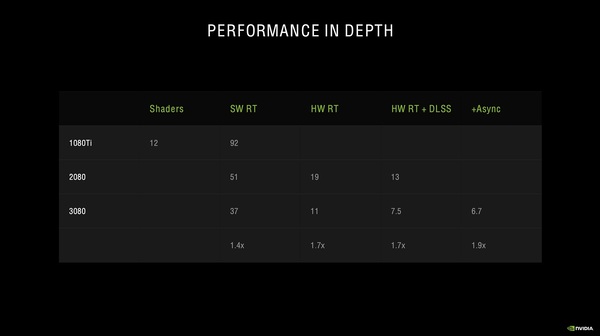
GeForce GTX 1080 Ti/RTX 2080/RTX 3080それぞれでレイトレーシングの処理をさせた時のフレームタイムをまとめたもの(数値の単位はミリ秒)。GeForce RTX 2080もRTX 3080もRTコアとTensorコアを使う(HW RT+DLSS)ことでフレームタイムを劇的に短縮できるが、Ampere世代のRTX 3080はRTコアとTensorコアを同時に動かせる(+Async)ので、Turingよりも最大1.9倍高速に処理ができる
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります