




GeForce RTX 40シリーズのフラッグシップとなる「GeForce RTX 4090 Founders Edition」を掲げるNVIDIAのジェンスン・ファンCEO。製品に刻印されたRTX 4090のフォントが前世代から変化し、やや垢抜けた印象になった
2022年9月21日0時(日本時間)、NVIDIAは「GTC 2022」の基調講演において、“第3世代RTX”となる新GPU「GeForce RTX 40シリーズ」を発表した。最上位の「GeForce RTX 4090」は29万8000円より(北米価格:1599ドル)で10月12日発売、RTX 4080はVRAMの違いにより2種類あり、16GBは21万9800円より(北米価格:1199ドル)、12GBは16万4800円より(北米価格:899ドル)で11月から発売となることが明らかにされた。
このNVIDIAの基調講演ではGTCという舞台の性質上、AIやシミュレーションといったインダストリー寄りの発表が大半を占めていたが、今回は“GeForce Beyond”と名付けた特別なセッションを冒頭に持ってくるなど、RTX 40シリーズのスタートを強く意識させる発表となった。今回はこのGeForceの内容のみにフォーカスし、筆者が気になったポイントをまとめてみたい。

RTX 4090は10月12日発売。VRAMはRTX 3090と同じGDDR6Xで24GBが搭載される

RTX 4080はVRAMは12GB版と16GB版があるが、どちらもGDDR6Xとなる。こちらは11月発売


日本語公式サイトでは、日本向けの価格がアナウンスされている
RTコアとTensorコアを発展させたAda Lovelace
RTX 40シリーズでは新アーキテクチャー「Ada Lovelace」が採用される。TSMCの5nm(NVIDIA曰く“4N”プロセス)となり、最大で18000基以上のCUDAコアを収容できる(Ampere世代の1.7倍)。CUDAコアの内容については触れられていないが、CUDAコアクラスターであるSM(Streaming Multiprocessor)のパフォーマンスも2倍以上(90TFLOPs)としている。

Ada Lovelaceの概要
Ada Lovelaceでは、RTコアとTensorコアが新世代に刷新された。まずRTコアは、レイトレーシングにおけるレイの交叉判定等を行うRTXテクノロジーのキーとなる部分だが、Ada Lovelaceでは第3世代のRTコアへ進化している。
今回新たに「シェーダー実行リオーダリング(SER:Shader Execution Reordering)」が搭載されており、処理の順番をリアルタイムで並びかえ、下段に控えるSMが効率良く処理できるようになっている。
レイトレーシングではレイがあらゆる方向に反射され、様々な質感のオブジェクトと交叉する処理を経て描画される。内部的には多数のスレッドが個別にシェーダー処理やメモリーへアクセスするのだが、これは非効率的であり、かつ並列化するのが難しい。だがSERを導入すれば、より効率良くシェーダーが処理できるように処理の順番を変更できるというのだ。CPUのアウトオブオーダー実行をGPU(RTコアだけだが)に持ち込んだわけだ。
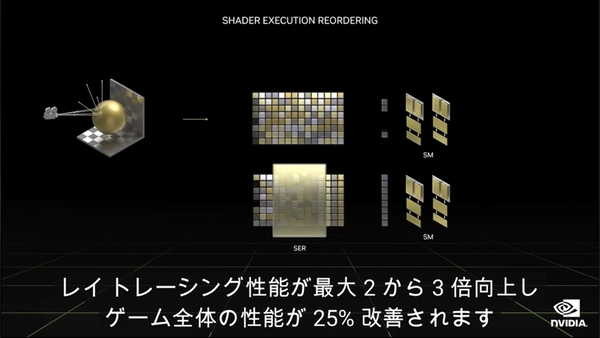
レイトレーシングの処理において、従来(中段上)ではレイの跳ね返る順番のまま逐次処理していたため、状況により下流のCUDAコアが使い切れない状況もあった。しかし第3世代RTコア(中段下)では下流のCUDAコアを効率良く動かせるようSERを用いて命令を並び替え、結果としてパフォーマンスが向上する
このSERにより、レイトレーシングの処理は2〜3倍向上、ゲーム全体の処理は25%向上するとNVIDIAは謳っている。
また、Tensorコアは第4世代に進化している。こちらはHPC向けのアーキテクチャー「Hopper」の“FP8 Transformer”エンジンを搭載している。Tensorコアのパフォーマンスは初代Turingで130 Tensor TFLOPsだったものがAmpereでは320 Tensor TFLOPs、そしてAda Lovelaceでは1400 Tensor TFLOPs(1.4 Tensor PFLOPs!)へと大幅に向上している。
RTX 4090や4080のスペックの詳細についてはほとんど触れることはなかったが、エネルギー効率(ワットパフォーマンス)においても忘れていないというメッセージは発していた。前世代のAmpereと同じ電力なら2倍以上のパフォーマンスを発揮できると謳っているが、これはレイトレーシング+DLSS込みの性能であり、それがなければ相応にワットパフォーマンスは下がることは十分に考えられる。
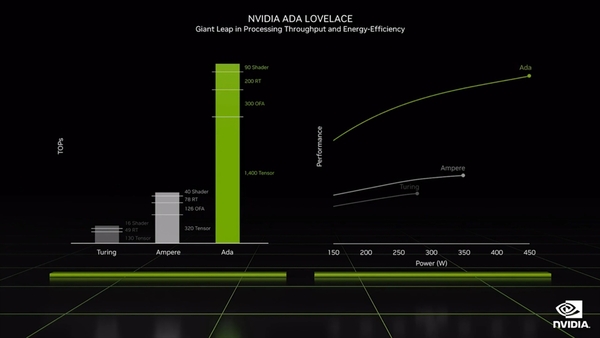
図中左はTuring/Ampere/Ada Lovelaceにおける性能を数値化したものだが、Ada Lovelaceで最も伸びているのはTensorコアの部分であることに注目。図中右ではAda LovelaceのワットパフォーマンスはAmpereの2倍の効率であると謳っているが、おそらくこれはRTコアやTensorコアを含んだ比較である。そしてAda Lovelaceの消費電力が450Wであることもこのグラフから読み取れる
DLSSも“DLSS 3”へ進化
ゲームグラフィックは画面上の各ピクセルに対してコツコツと様々な処理を重ねることで成立しているが、すべてのピクセルに対し愚直に処理していたらいくらパワーがあっても足らないという状況になってきた。特に、レイトレーシングが加わってからその傾向は急激に加速している。
そこで注目されたのがアップスケーラーであり、その先駆けといえるのがNVIDIAの“Deep Learning Super Sampling”こと「DLSS」だ。映像を本来よりも低解像度でレンダリングし、それをTensorコア(AI)を利用してアップスケール処理するというのがDLSSの仕組みだが、AMDがTensorコアが不要な汎用技術「FSR 2.0(AMD FidelityFX Super Resolution 2.0)」、インテルがArc Aシリーズ専用の「XeSS(Xe Super Sampling)」といった類似技術を投入したことで、陳腐化してきたことは否定できない。
だが今回、NVIDIAは新たに「DLSS 3」を発表。DLSS 3では前フレームと新フレームの情報から、フレーム間のピクセルの方向と速度を抽出し、それをゲーム側のピクセル等の情報と合わせることで、新しいフレームを生み出すことができる。
今までのDLSSはレンダリングしたピクセルの集合から新たなピクセルの集合を生成していたが、DLSS 3ではもう1次元上、フレームから別のフレームを生成できるようになる。物理演算やワールド規模の大きいゲームにおいて、CPUバウンドな状況に陥った場合、GPUにレンダリングさせるべき情報をCPUが用意するのも遅れてしまう。だがDLSS 3でGPU側が中間フレームを用意すれば、CPU側のフレームレートが足りなくても、GPUだけでフレームを補完することが可能になる。
今のCPUはコア数が10基以上あるのは当たり前になりつつあるが、全コアを効率良く使えるゲームはまだ少数派で、特定のコアに処理が集中してボトルネックになることも多い。DLSS 3はゲームにおけるCPU利用の非効率性を補うものと考えられる。
さらにDLSS 3には、レンダリング遅延を最小化する「Reflex超低遅延パイプライン」も組み込まれており、eスポーツ性の高いゲームでも利用しやすいように工夫されている。
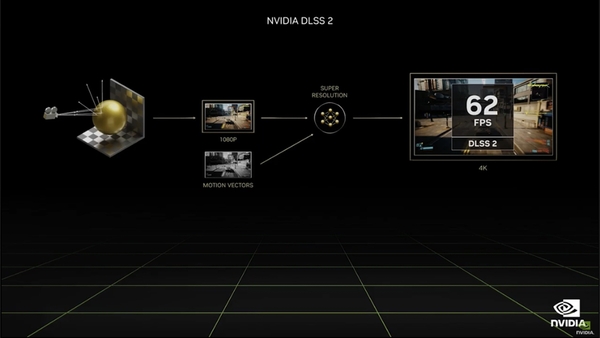
既存のDLSSでは、低解像度のレンダリングイメージとモーションベクターをニューラルネットワークに放り込むことで、より高解像度のイメージを出力していた。言い換えれば一群のピクセルから別のピクセル群を生成していたわけだ
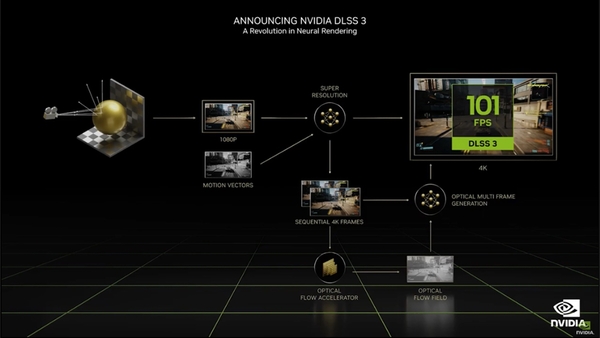
DLSS 3ではニューラルネットワークで生成されたフレーム群をオプティカルフローアクセラレーターを通しピクセルの動きの情報を抽出(DLSSのモーションベクターに相当するもの)、これをフレーム群と合わせてニューラルネットワークに放り込むことで、GPUだけで次のフレームを予測してレンダリングできる
DLSS 3に対応するゲームは「Cyberpunk 2077」や「Microsoft Flight Simulator」が挙げられている。デモでは、Cyberpunk 2077がDLSS非利用時よりも5倍近く、Microsoft Flight Simulatorが2倍程度、DLSS 3でフレームレートが向上している。
ただ、DLSS 3がRTX 40シリーズのみ対応するのか、既存のDLSSゲームはアップデートだけでDLSS 3対応になるのか、それともゲーム側で別途DLSS 3対応が必要になるのかという情報までは明らかにされていない。今後の発表が待たれるところだ。

DLSS 3に対応するMicrosoft Flight Simulatorにおけるフレームレート比較。DLSS 3を利用することでほぼ2倍のフレームレートが得られる
RTX 30シリーズは併売される
冒頭で述べた通り、RTX 40シリーズは4090と4080が発表され、それより下のモデルに関しては言及がなかった。RTX 4080が11月(筆者の推測では感謝祭〜ホリデーシーズン狙い)なのだから、RTX 4070以下は2023年以降の発表になることは想像に難くない。
ただ今回の発表では、RTX 4090と4080をメインで解説しつつも、最後の最後でRTX 3060〜3080の存在もアピールしていた。つまり、コストの高いRTX 4080/4090はエンスージアスト向けとして、最近値下がりニュースが飛び交うRTX 30シリーズは併売し、こちらをゲーマー向けのメインストリームにしようというNVIDIAの思惑が見てとれる。年末に向けRTX 30シリーズにももう1段階テコ入れがありそうだが、まだ筆者の想像の域を出ない。

RTX 4070より下は存在が明らかにされておらず、代わりにゲーマー向けのメインストリームはRTX 30シリーズであるというメッセージも見られた
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります