



第479回
Radeon RX 9070 GREレビュー! VRAM 12GBでRTX 5060 Ti 16GBに圧勝しRTX 5070に迫る
2026年06月02日 09時00分更新
AI関連ではトークン出力スピードがかなり改善
あまり凝ったテストをする時間がなかったので、今回はAI(LLM)のパフォーマンスに注目したい。まずは「UL Procyon」に実装されている「AI Text Generation Benchmark」を試す。スコアーも算出されるが、ここではあえてトークン出力スピードと最初のトークンまでの時間の比較を直接比較した。
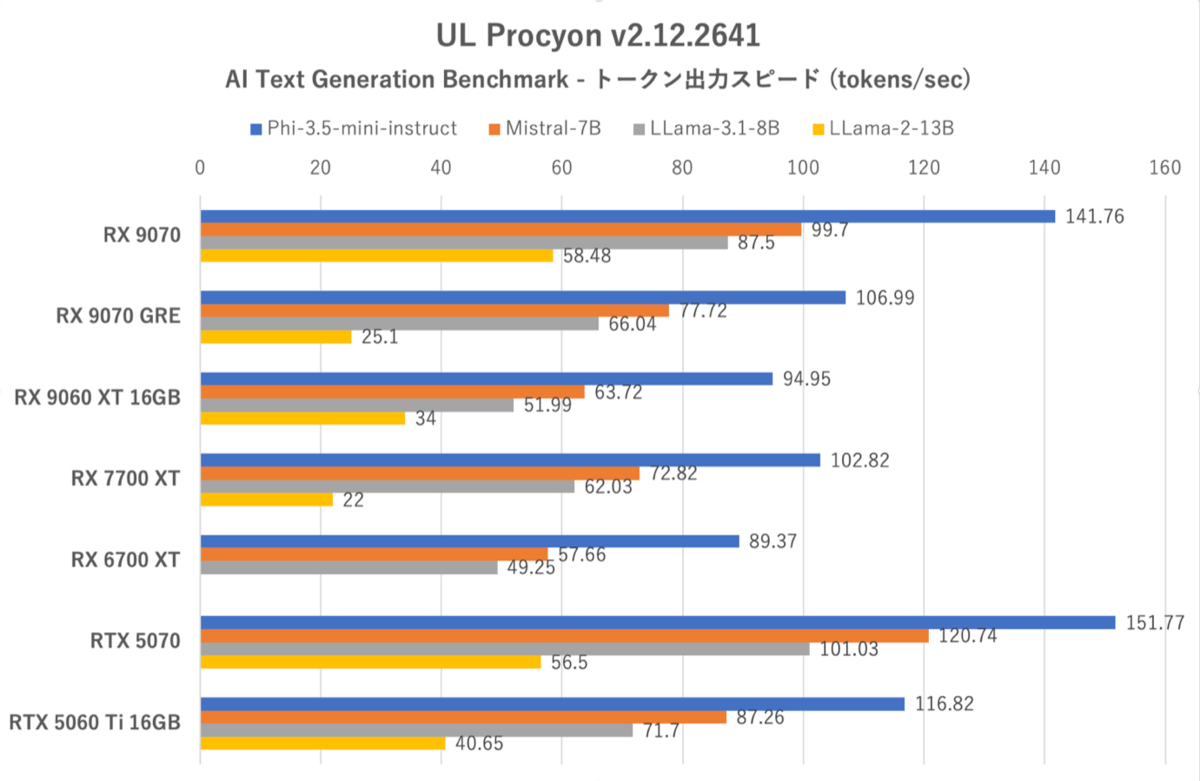
UL Procyon:AI Text Generation Benchmarkにおけるトークン出力スピード
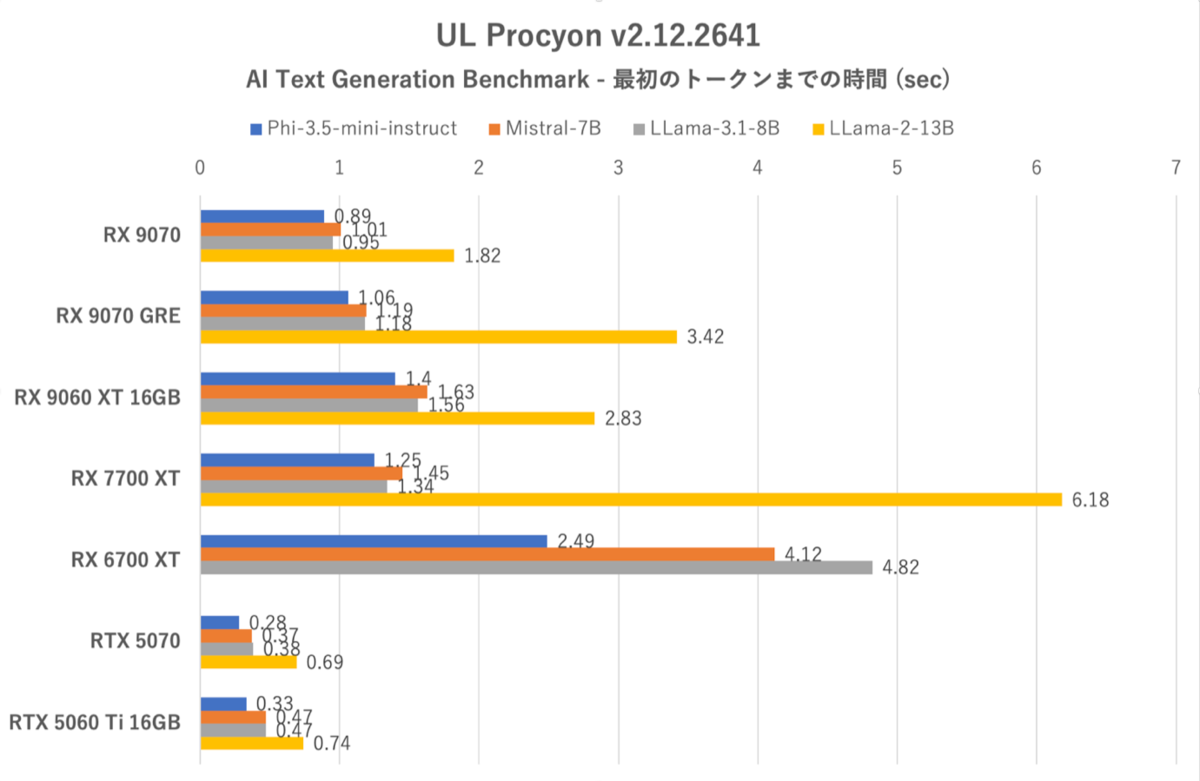
UL Procyon:AI Text Generation Benchmarkにおける最初のトークンまでの時間
グラフから分かる通り、このテストで使用される学習モデルはやや古いがVRAM使用量が少ないものが多い。ここで注目したいのは唯一13Bパラメーターを使用しVRAM使用量の多いllama2-13Bの結果だ。
llama2-13B以外のパターンではRX 9070 GREはRX 9060 XT 16GBより安定して強いのだが、llama2-13Bに限りRX 9060 XT 16GBに負ける。VRAM 12GBという仕様が効いていると考えられる。
ただ同じVRAM 12GBのRTX 5070はllama2-13BでもRTX 5060 Ti 16GBに勝っているではないか……と思うかもしれないが、いまさらllama2の性能でLLM性能全体を語るのは少々厳しい。そこで、もっとVRAMに厳しいテストをやってみよう。
と言うわけで「LM Studio」でさらに重い「GPT-OSS 20B」を使ってテストする。GPUオフロードは最大、コンテキスト長は8192、シード値は共通、Reasoning設定はMedium設定とした。プロンプトは以下の通りだ。
2026年におけるパーソナルコンピューターにおけるローカルAIの現状について包括的なレポートを作成してください。セクションごとに内容を整理し、簡潔な要約を示してください。実績を引用する際は、出典元も明記してください。前提として、私はこの分野に詳しく、PC関連の技術にも精通しています。現状のエコシステムを理解したいと考えています。
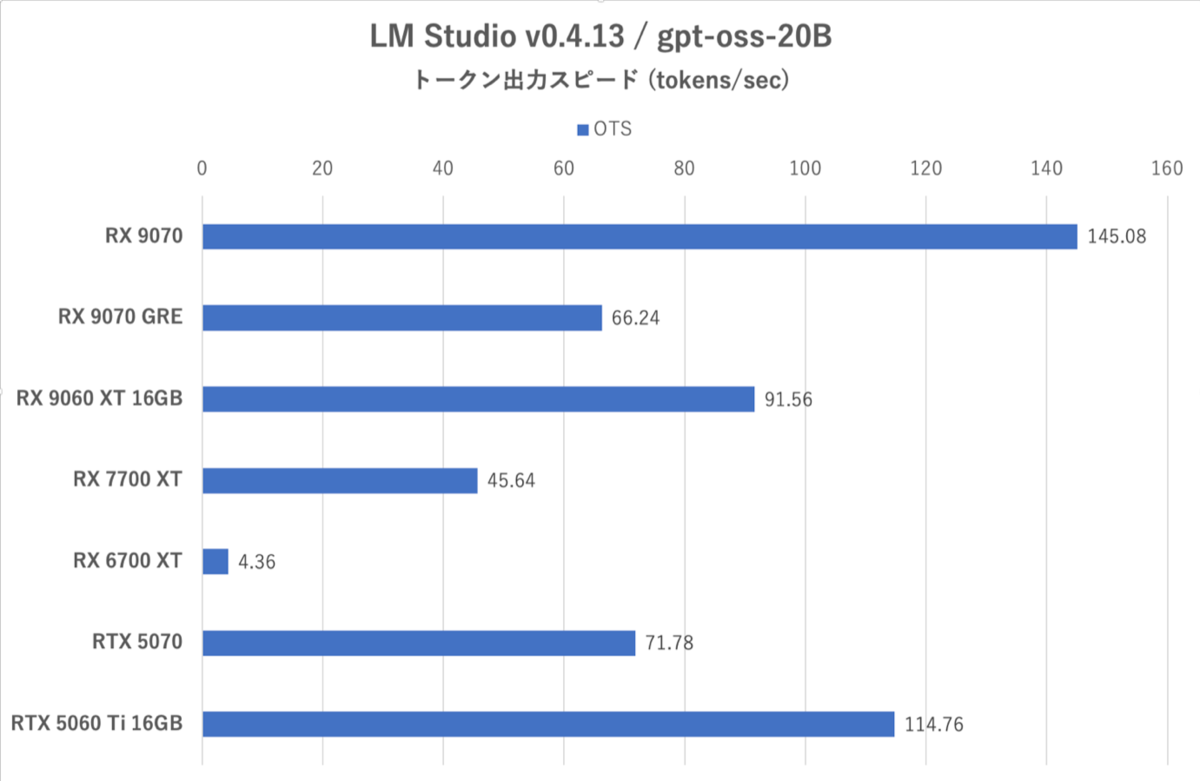
LM Studio:トークン出力スピード
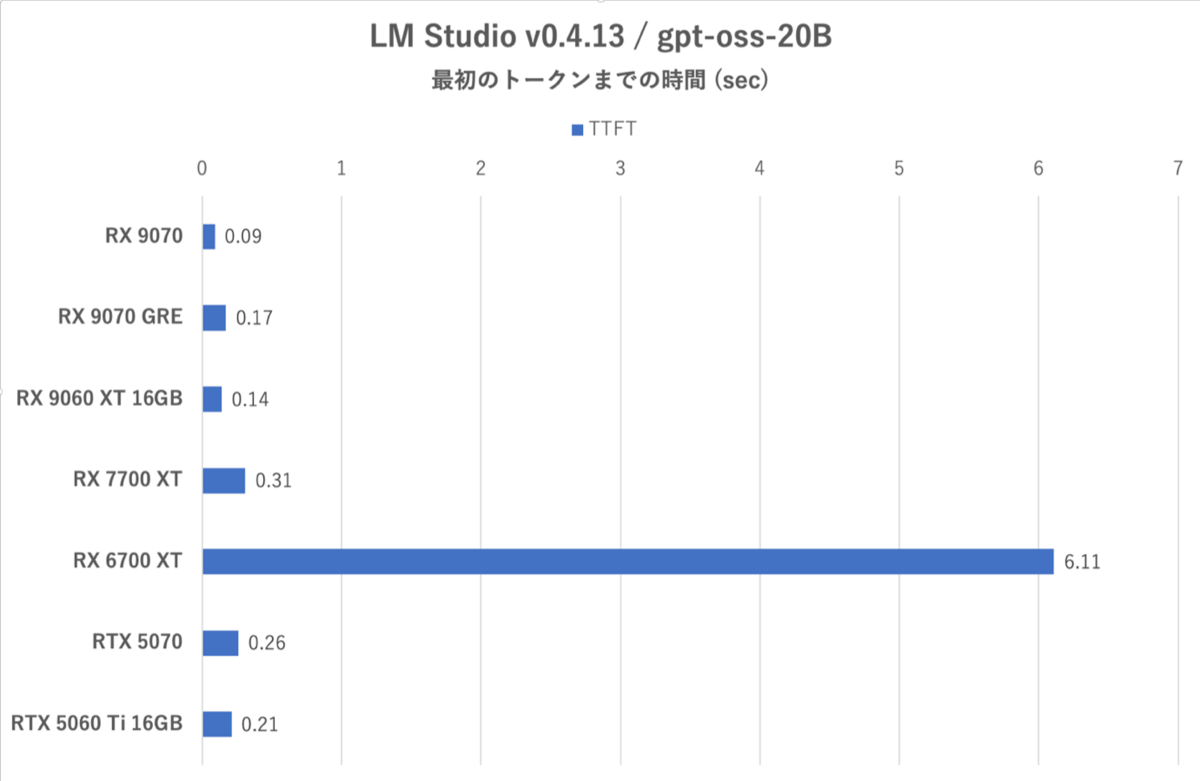
LM Studio:最初のトークンまでの時間
ここではVRAM 12GBのRX 9070 GREとRTX 5070が格下のRX 9060 XT 16GBやRTX 5060 Ti 16GBにトークン出力スピードで負けている点に注目。今どきのパラメーター数の多い学習モデルでは、VRAM 12GBはハンデになり得る。ただ旧世代のVRAM 12GB世代と比較すると、RX 9070 GREはトークン出力スピードにおいてRX 7700 XTの1.45倍、RX 6700 XTに至っては15倍と格段に強い。
さらに言うならUL Procyonではトークン出力スピードにおいてRadeon勢はGeForceより確実に遅かったのだが、ここではむしろGeForce勢よりも速いまである。RDNA 4のAIエコシステムは確実に改善しているのだ。
ゲーム11本で検証
ここからが本稿の本番、ゲームによる検証結果をお届けする。まずは共通する計測ルールを確認しておこう。
| 検証環境 | ||||||
|---|---|---|---|---|---|---|
| 解像度 | 1920×1080/ 2560×1440/ 3840×2160ドットの3パターン | |||||
| 画質 | 最高画質設定、もしくはそれに準ずるもの | |||||
| FSR 4 | ドライバー上で有効化(対応GPUのみ) | |||||
| FSR MLフレーム生成 | ドライバー上で有効化(対応GPUのみ) | |||||
| DLSS | NVIDIA AppでプリセットMにオーバーライド フレーム生成のプリセットは「推奨」設定 |
|||||
| アップスケーラー | DLSS「クオリティー」設定、もしくはFSR「クオリティー」設定 (DLSS | FSR Qと表記) |
|||||
| フレーム生成 | 不使用/ 2x/ 4xまたは6xの大きい方の3パターンで計測 フレーム生成使用時はFG 2x/ FG 4x/ FG 6xと表記 AFMF(AMD Fluid Motion Frames)やSM(NVIDIA Smooth Motion)は使用しない |
|||||
| 計測ツール | 「CapFrameX」でmsBetweenDisplayChange基準により フレームレートを算出 |
|||||
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります