



メタ傘下のメタAIは4月17日(現地時間)、「自己教師ありモデル」を採用し、微調整を必要としない高性能なコンピュータービジョンモデル「DINOv2」を発表、デモサイトとともにオープンソースで公開した。
自己教師ありモデルとは
Announced by Mark Zuckerberg this morning — today we're releasing DINOv2, the first method for training computer vision models that uses self-supervised learning to achieve results matching or exceeding industry standards.
— Meta AI (@MetaAI) April 17, 2023
More on this new work ➡️ https://t.co/h5exzLJsFtpic.twitter.com/2pdxdTyxC4
コンピュータービジョンモデルとは、コンピューターが画像や動画などの視覚情報を解析し、理解するための技術だ。
例えば、自動運転車が道路上の障害物や歩行者を認識したり、スマートフォンのカメラアプリが顔を検出して自動的にフォーカスを合わせたりする際に使用される。
現在コンピュータービジョンモデルをトレーニングする際は、大量に用意された画像と、その意味内容を記した手書きのラベルのペア(データセットと呼ばれる)を使って事前にトレーニングする「image-text pretraining(画像−テキスト事前学習)」と呼ばれる手法(教師あり学習の一手法)が標準的なアプローチとなっている。例えば、部屋に置かれた椅子の画像に対し「single oak chair」という正解データが書かれたラベルを付けたものを大量に用意して学習させる手法だ。
だが、教師あり学習(Supervised Learning)は、画像の理解がラベルに依存しているため、ラベル内で説明されていない重要な情報、この場合「椅子の色」、「椅子が空間内のどこに位置しているか」といったものを無視してしまうという欠点がある。また、大量のデータにラベルを付けるためには膨大なマンパワーが必要となるうえ、特殊な分野の画像(例えば医学分野で使用する細胞の画像)の場合、ラベルを付けることができる専門知識をもった人材がほとんどいないといった問題もある。
そこでDINOv2は教師あり学習ではなく、「GPT-4」や「PaLM」といった大規模言語モデルの作成に使用されている方法と同じく「自己教師あり学習(self-supervised learning)」と呼ばれる手法を採用した。
自己教師あり学習は、ラベルを人力ではなく入力データから直接生成、つまりデータ自体が正解を提供する仕組みのため、ラベルの有無に関わらず、あらゆる画像群から学習することができるのが特徴だ。
また、教師あり学習では、事前学習されたモデルを特定のタスクに適用する際に微調整(Fine-tuning)と呼ばれるプロセスが必要になるが、DINOv2は十分な汎用性を持っているため、微調整を必要としないのも大きな特徴だ。
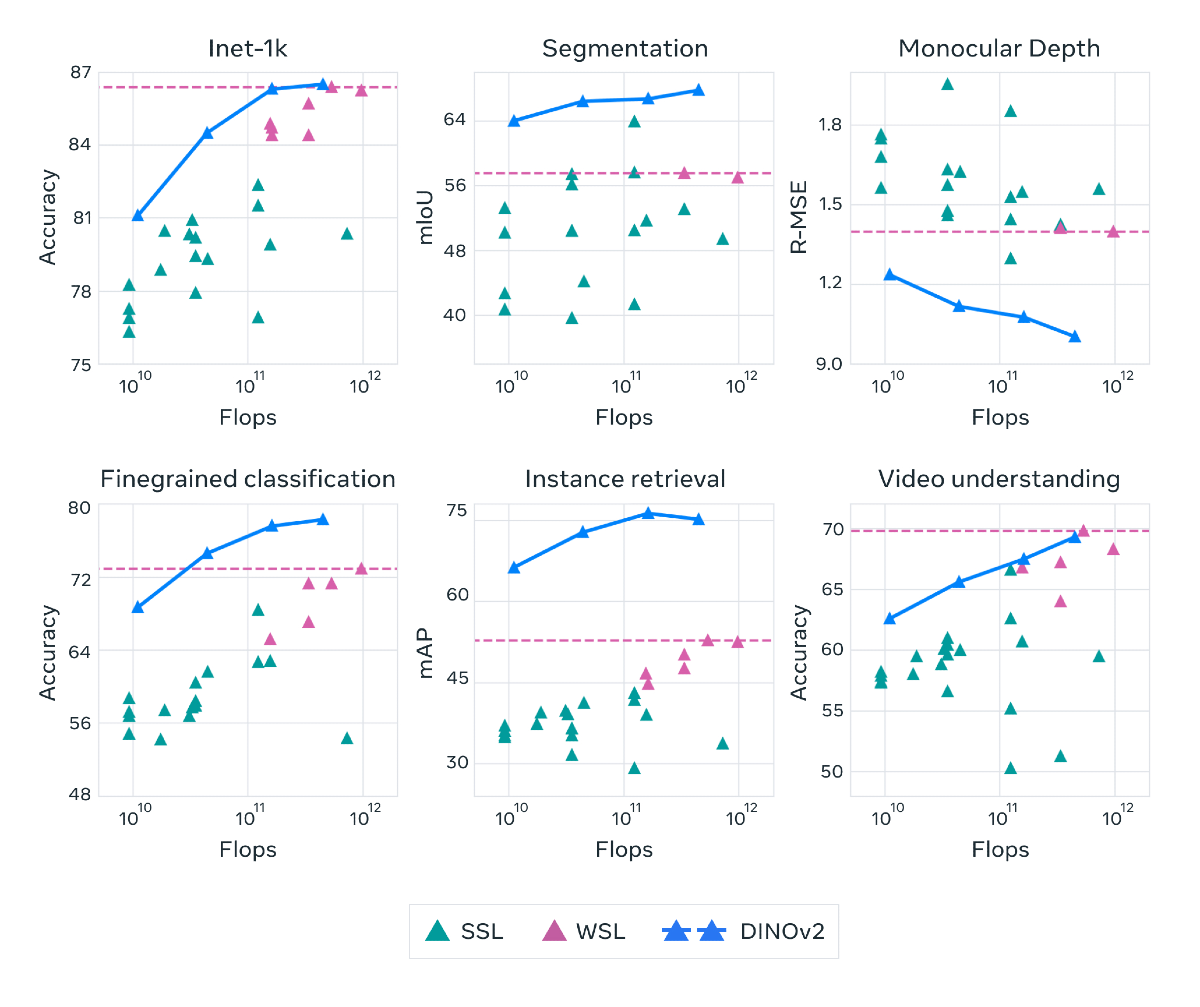
「SSL」は従来の自己教師あり学習、「WSL」は弱教師あり学習
ベンチマークによると、DINOv2は、従来の自己教師あり学習の技術水準を大幅に向上させ、弱教師あり学習(不完全、不正確な、あるいは部分的なラベルによる学習)と同等の性能に到達したという。
デモサイト
発表と同時に公開されたデモサイトには、3つの実際に動かすことのできるデモが用意されている。
深度推定(Depth Estimation)

深度推定とは画像からピクセルあたりの深度(距離情報)を予測するモデル。DINOv2は一枚の画像だけで高精度な深度推定が可能だ。デモサイトでは任意の画像をアップロードしてその精度を確認することができる。
意味的セグメンテーション(Semantic Segmentation)

意味的セグメンテーションとは画像内の各ピクセルを特定のクラスに割り当てるタスク。これにより画像中の物体や領域を正確に識別しすることができる。DINOv2は微調整なしでも初見の画像をセグメンテーションすることが可能だ。
インスタンス抽出(Instance Retrieval)
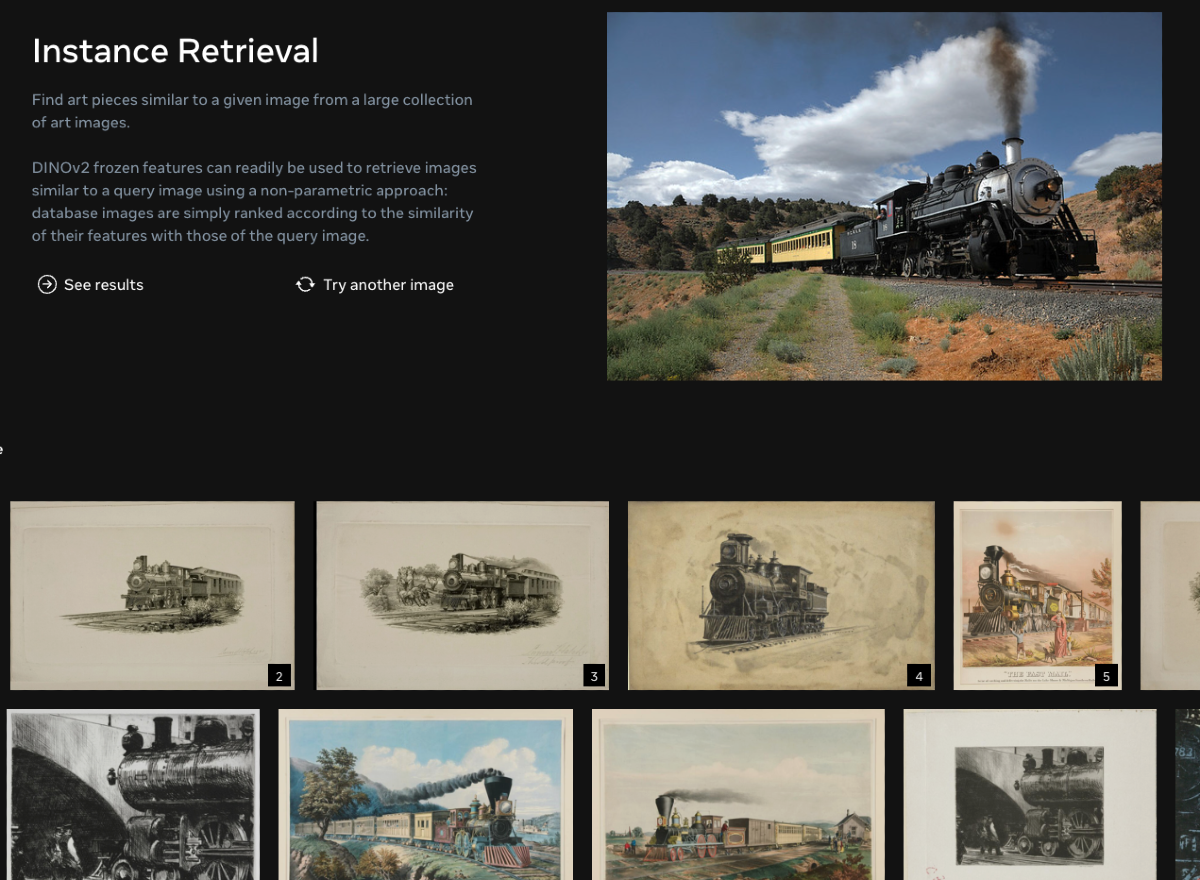
インスタンス抽出とは、多数の画像の中から特定の画像に似たものを抽出するタスク。DINOv2はすべての画像から特徴量を抽出し、類似性を計算してランク付けすることによってこのタスクを実現している。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります