



レイトレーシングにDLSS、RTコアやTensorコアの役割、自動OCテスト機能まで!
Turingコアの構造も謎の指標「RTX-OPS」の計算方法も明らかに!徐々に見えてきたGeForce RTX 20シリーズの全貌
2018年09月14日 22時00分更新
レイの衝突判定処理が専門の回路「RTコア」
RTX 20シリーズの最強武器であるリアルタイムレイトレーシングは、計算量が余りにも多いため従来設計のGPUでは実装することが難しい。事実、NVIDIAがGTC 2018でリアルタイムレイトレーシング技術(RTX)を発表した際は、Tesla V100を4枚搭載したモンスターPC「DGX Station」を準備し、力押しでようやく24fpsの映像を作り出していた。この処理を1GPUで実施するには、専用のハードウェアアクセラレーターが必要になる。つまり、RTコアという訳だ。
RTコアの仕事は2つある。レイトレーシングでは、描画したい3D画像の視点(カメラ)から画面の各ドットを通過するように仮想的な光線、すなわち“レイ”を放つ。レイが何かポリゴンに当たれば、これに影響する光源の情報などを用いて色の計算ができる。また、反射や屈折を起こすような素材が設定されていれば、その場所からレイを投げて次に当たるポリゴンを求めていく。つまり、カメラに届く光が届く道のりをレイを飛ばして調べることで映像を作っていくのだ。
レイトレーシングでは放ったレイが「どのポリゴンに衝突したか」を調べる処理が無数に発生する。レイの反射や屈折などを完全に無視しても、フルHD/60fpsの映像をレンダリングするには最低でも1億2441万6000回(1920×1080×60)のレイの処理。つまり、毎秒約124Mega Rays(メガレイ)ぶんの「レイの衝突判定」が発生するわけだ。もちろん、レイの反射・屈折などがあればそこから新たなレイが放たれるため、1秒間に必要なレイの計算は加速度的に増えていく。
RTX 20シリーズに搭載されたRTコアは、レイの衝突判定処理を専門に処理する回路だ。しかし、単純に全ポリゴンの頂点情報を衝突判定にかけるという処理では間に合わないので、「レイに衝突しそうなポリゴンをすばやく絞り込む」テクニックが必要になる。
そこで、RTコアではシーンに配置されたポリゴンを「BV(Bounding Volume)」という大きなブロックの塊で包んでおく。レイが発射されると、どのBVを通過するかチェックする。BVの中にはさらに小さなBVが詰め込まれているので、レイが中のBVのどれに当たるかをチェック。このBVの階層構造の終着点に達すると、レイが衝突したポリゴンの座標データを得られる。階層化されたBV、すなわち「BVH(Bounding Volume Hierarchy)」の中から、レイが衝突するポリゴンのデータを超高速で取り出すのが、RTコアの役目なのである。
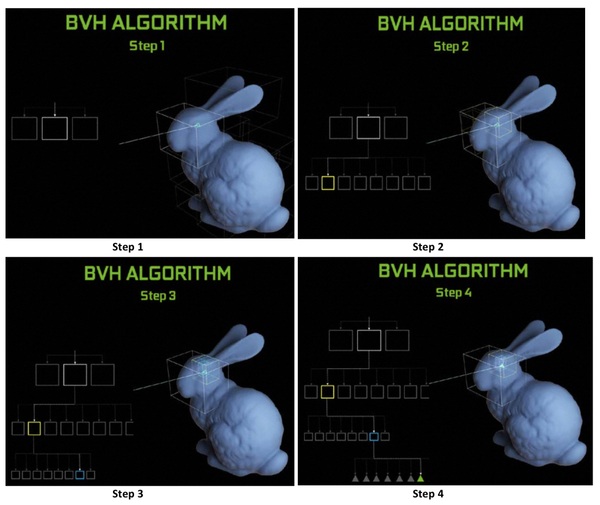
BVHを用いたレイの衝突判定の仕組み。ウサギのオブジェクト内のどのポリゴンにレイが衝突するかを判定する場合は、まず最外殻にあるBVのどれを通過するのか調べる(Step1)。最初のBVの外にあるデータはこの時点で処理の対象から消え去る。続いてStep2→Step3で最初のBVの中にある小さなBVのどれをレイが通過するのか……と繰り返していくと、最終的にレイが衝突するポリゴンが見つかる(Step4)。
RTコアは大きく2つのユニットで構成されている。1つはレイがどのBVを通過するのかを検出するユニット。そしてもう1つは、レイとポリゴンの交差を検出するユニットである。視点Aから画面上のドットBに向かってレイの発射を行なうのはCUDAコアだが、一度そのデータがRTコアに渡ると、一瞬でRTコアがレイに衝突するポリゴンをサーチ。その結果をCUDAコアに返すという流れになる。
もちろん、この処理をCUDAコアだけで処理することは可能だが、BVの絞り込みもレイとポリゴンの衝突判定にも1レイあたり凄まじい命令を消費することになる。Pascal(GTX 1080 Ti)のCUDAコアでは1Giga Raysあたり10TFLOPSの計算パワーが必要になる。そして、GTX 1080TiのFP32性能は11.3TFLOPSなので、毎秒1.13Giga Raysの処理“しか”できない。
しかし、Turing(RTX 2080 Ti)では、68基のRTコアで毎秒10Giga Rays以上の処理ができる。NVIDIAがケルンの特別イベントで「(RTX 2080Tiが)GTX 1080Tiの10倍の性能」と謳っていたのは、この計算が下地になっているのだ。
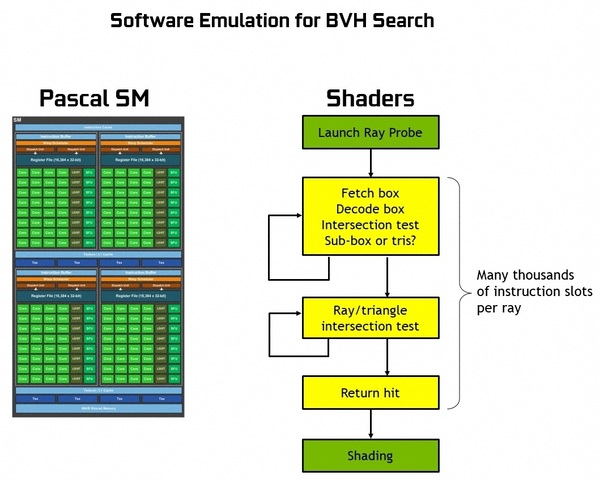
Pascal世代のGPUでRTコアの仕事をさせようとする場合、レイの衝突判定処理(黄色の部分)だけで数千命令を消費してしまうため、とてもリアルタイムの描画にはならない。ソフトウェア・エミュレーションの限界なのだ。
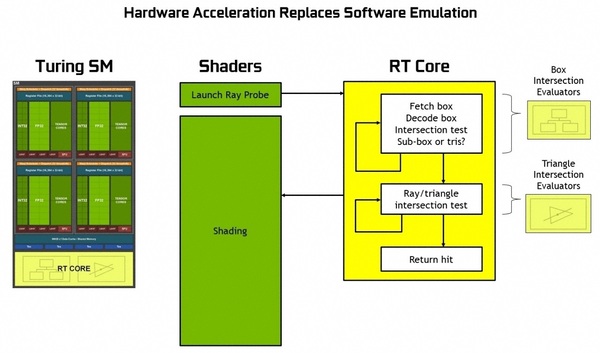
Turingではレイの発射データをCUDAコアからRTコアに渡すと、まずレイがどのBVを通過するのかを調べ、さらに内部のBVへと通過判定を進める(Box Insertion Evaluators)。BVの最深部にあるポリゴンに到達すると、今度はレイが実際にポリゴンに衝突しているのかを判定する。黄色の部分が専用ハードウェアで高速処理できるのがTuringの大きな強み。
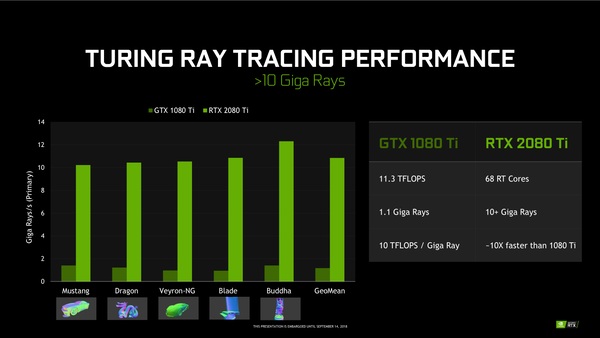
Pascal(グラフでは濃い緑)とTuring(明るい緑)では、1秒あたりに処理できるレイの数に大きな隔たりがある。レンダリングする対象が複雑になればなるほど処理するレイの数は増えていくが、レイトレーシングにおいてTuringはPascalの10倍のパフォーマンスを発揮できる、としている。
レイを飛ばして衝突するポリゴンを見つけ、必要とあらばさらにレイを飛ばす……という技法にも当然限界はある。1つは現実世界と同じ光源の計算をしようとすると、パワーが足りなくなる問題。
下はレンダリング処理時間を計測するベンチマークソフト「LuxMark」でレイトレーシングを実行した時の画面の変化。最初の頃は画面全体にノイズが乗ったような結果にしかならないが、時間をかけて何回も処理することで次第にノイズの少ない画像に集束してゆく。
ただし、リアルタイムレイトレーシングではここまで手間をかけられない。ではこれをどうするのか? 少数のレイの処理でできたノイジーな画像からノイズを除去する処理(デノイズ:Denoise)を加えることで、レイの処理を最小限に切り上げつつ高クオリティーな映像を生成するのである。


「LuxMark」によるCGレンダリングの例。処理を始めた当初は砂嵐がかかったような映像しか得られないが、時間をかけ繰り返し処理するとだんだん普通の映像に近づいていく。だがこれと同じことをPCゲームでやるわけにはいかない。
このデノイズ処理はAIベースなものと、非AIベースなものがあり、プログラム側で選択できるようになっている。だが本命は前者、つまりTensorコアを利用したデノイズ処理といったところだ。RTXにおいてAIとレイトレーシングは表裏一体と言うべき存在なのである。
ただ現時点では、AIベースと非AIベースでデノイズ処理にどのような性能差が出るかは示されていない。今後の情報を待ちたいところだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります