



メタ、コードの生成に特化したAIモデル「Code Llama」を研究・商用利用可で公開
2023年08月25日 12時10分更新
メタは8月24日(現地時間)、大規模言語モデル「Llama 2」をベースにプログラムコードを生成、評価、検討できるよう微調整されたAIモデル「Code Llama」を発表。研究および商用利用共に無料で利用できる。
10万トークンを安定して処理
Code LlamaはLlama 2をコードに特化したデータセット(5000億トークン※注)でさらに訓練し、コード生成および評価・検討に特化したモデル。
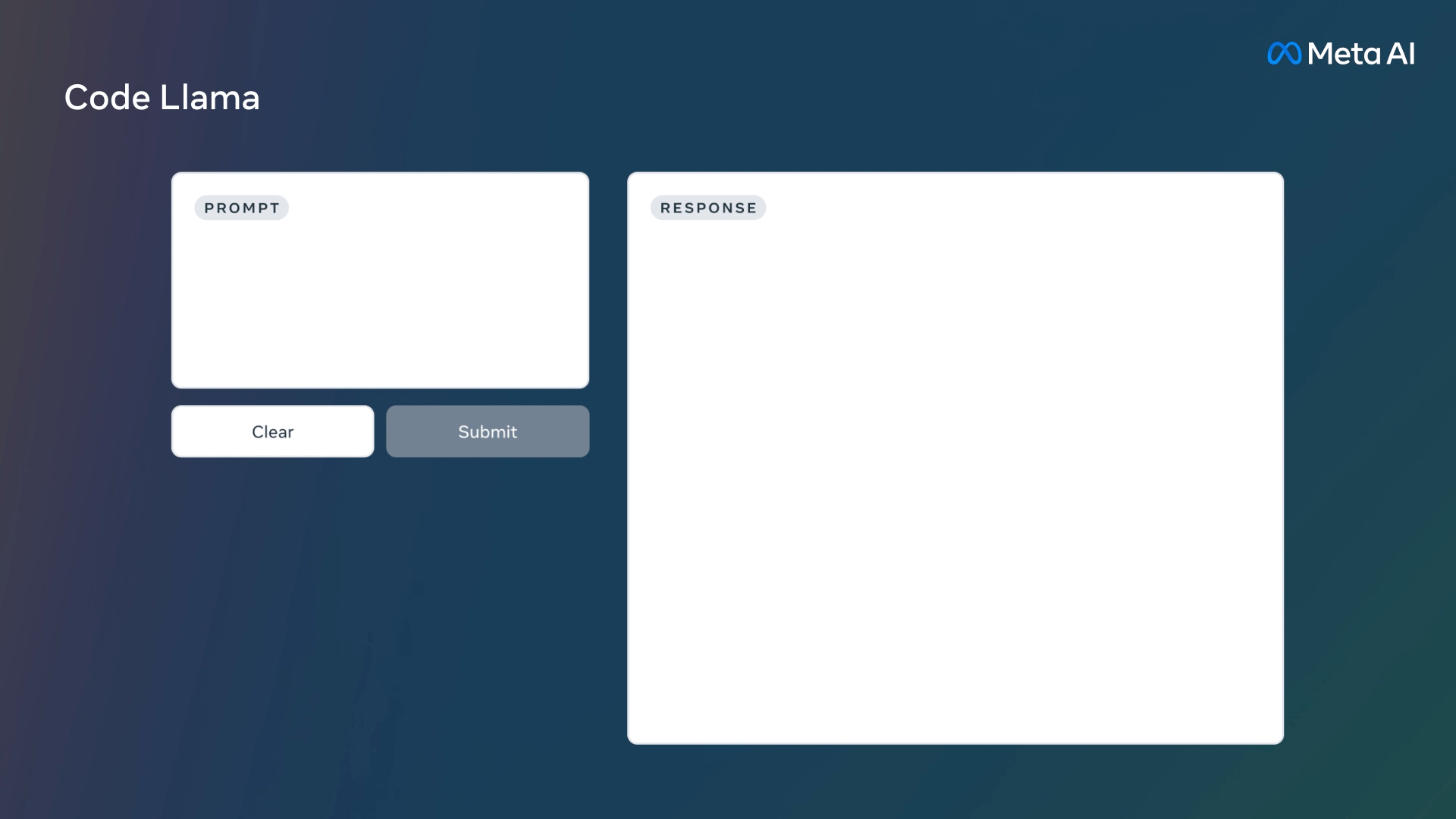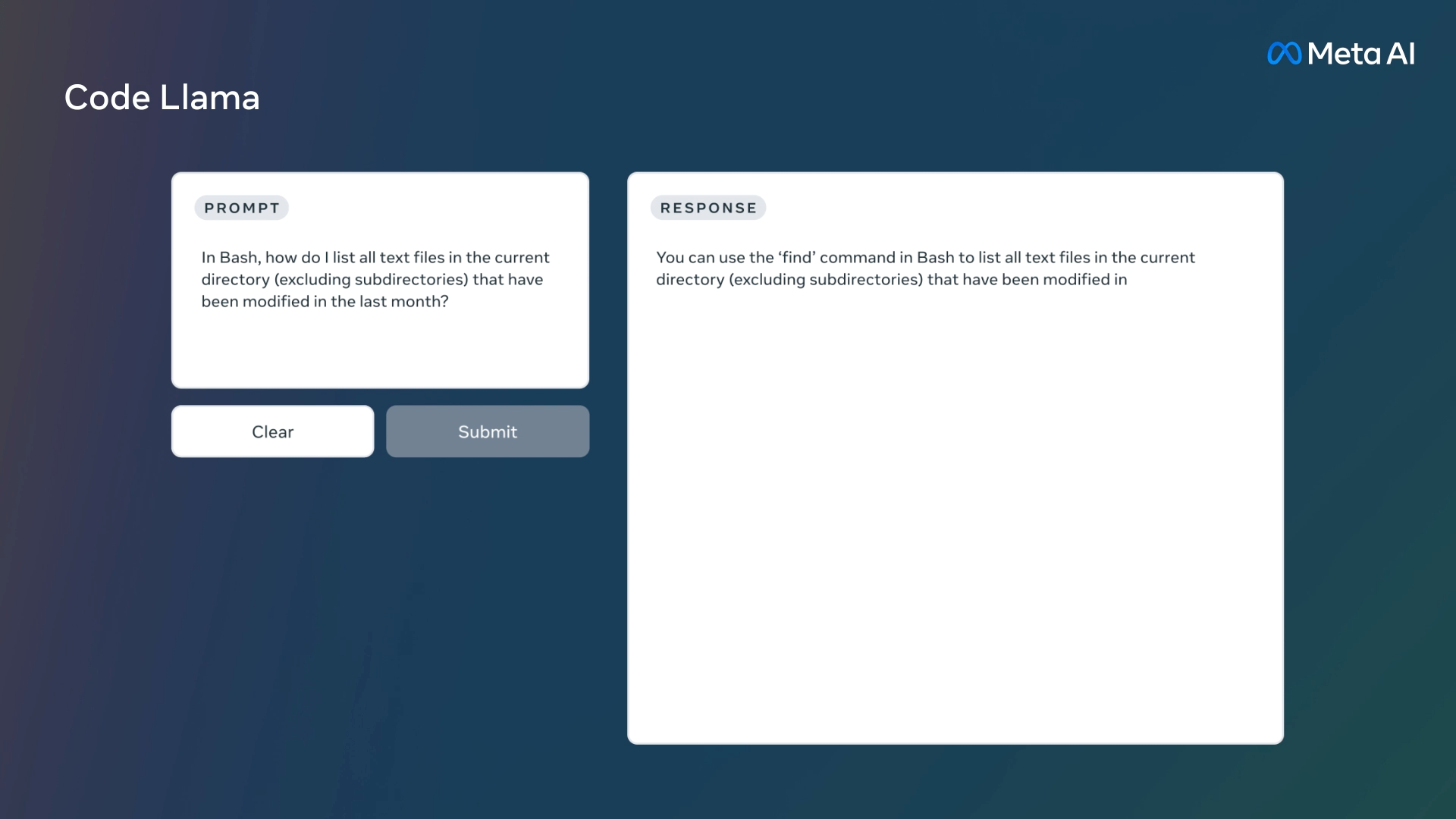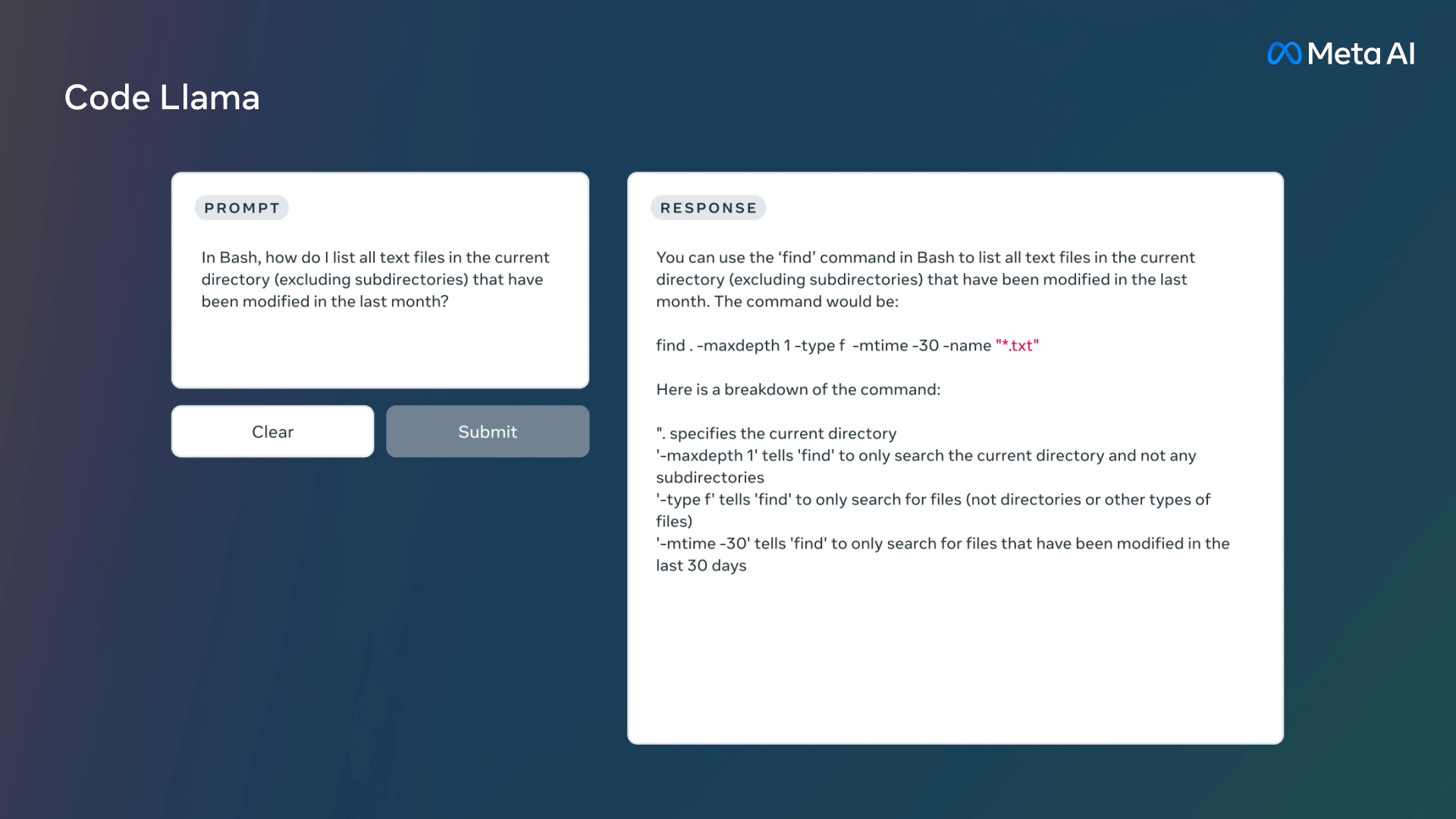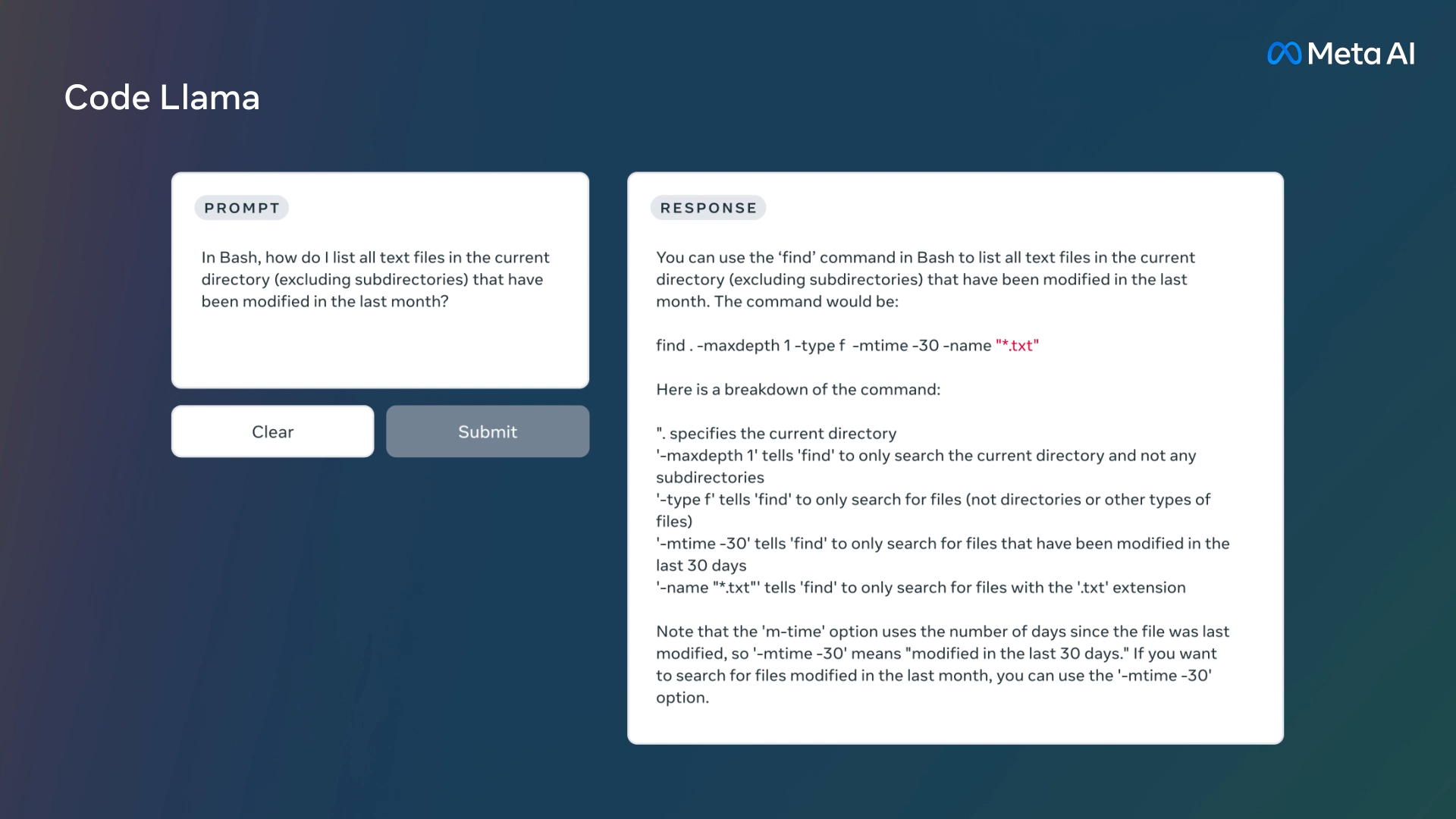
「フィボナッチ数列を出力する関数を書いてください」といった自然言語プロンプトから、コードおよびコードを説明する自然言語を生成。コード補完やデバッグといったタスクが可能になっている。
対応言語はPython、C++、Java、PHP、Typescript(Javascript)、C#、Bashなど、現在使用されている一般的なプログラミング言語の多くをサポート。
パラメーターのサイズごとに、7B(70億)、13B(130億)、34B(340億)のモデルに分かれている。7Bモデルは1つのGPUでリアルタイム処理できるほど軽量で低レイテンシーになっている一方、34Bモデルは最高の結果を返し、よりよいコーディング支援を可能にするので、ユースケースごとに使い分けることが可能だ。
※注 トークンはテキストデータをAIモデルが理解できる形式に分割した最小単位
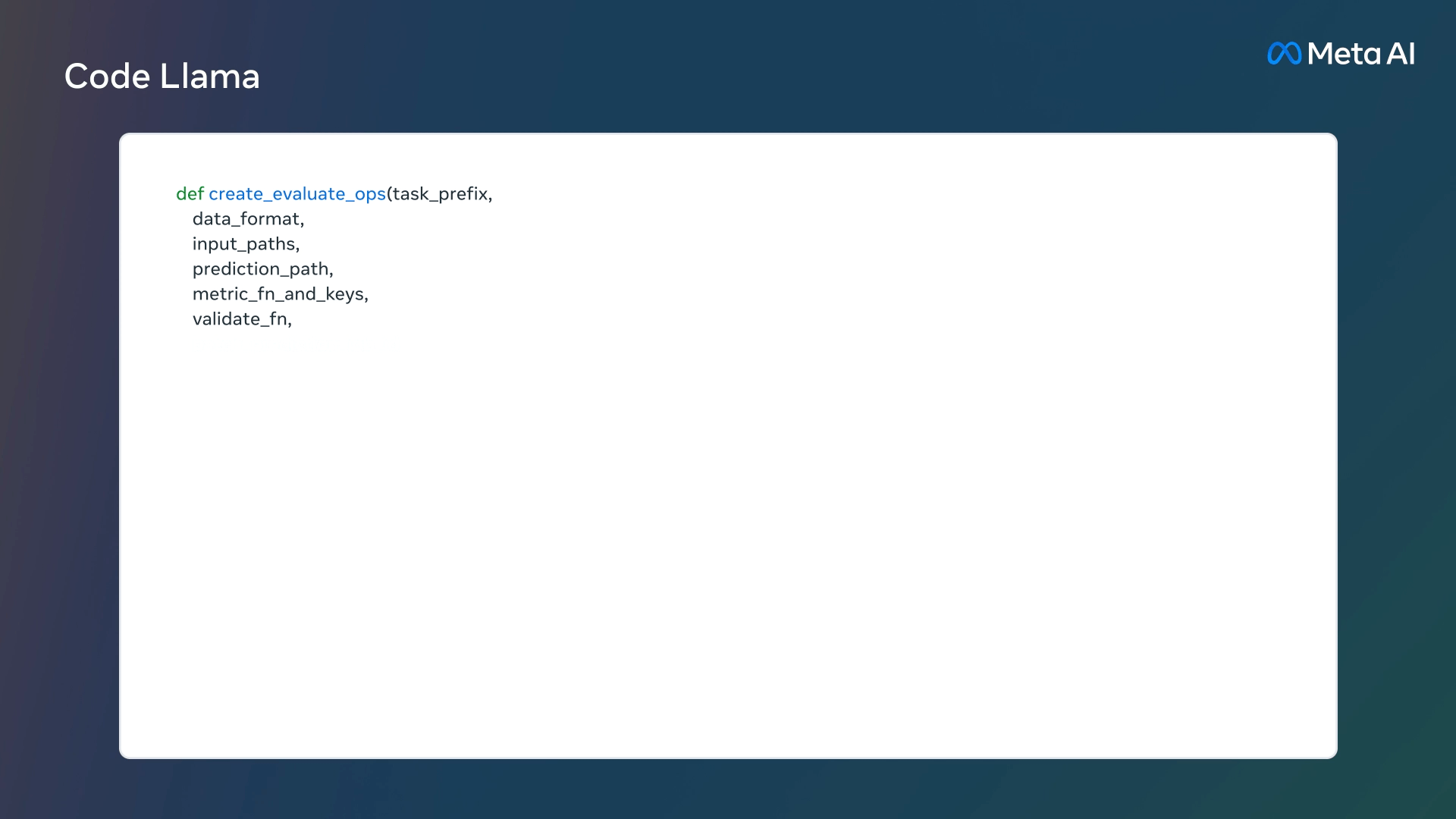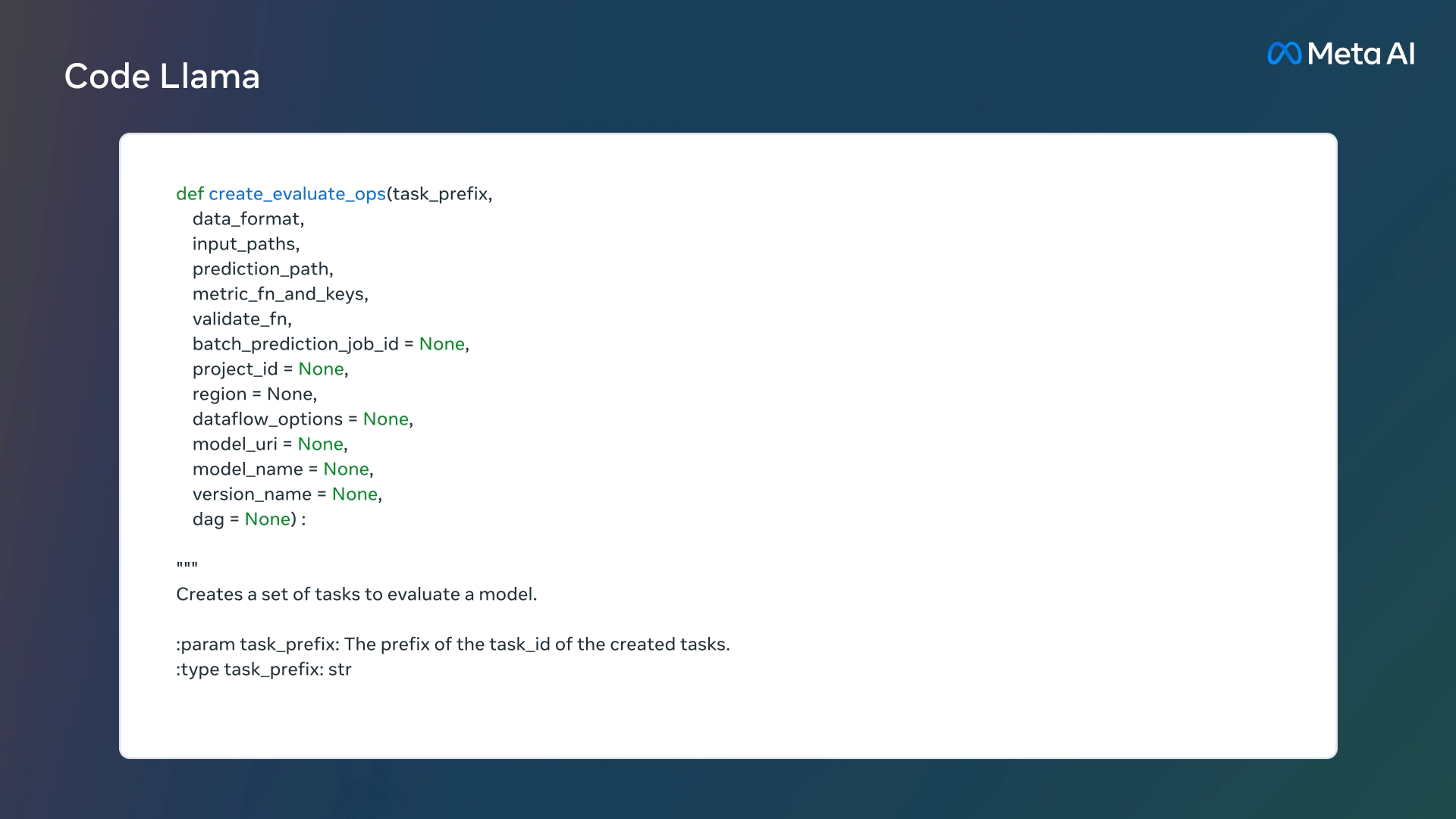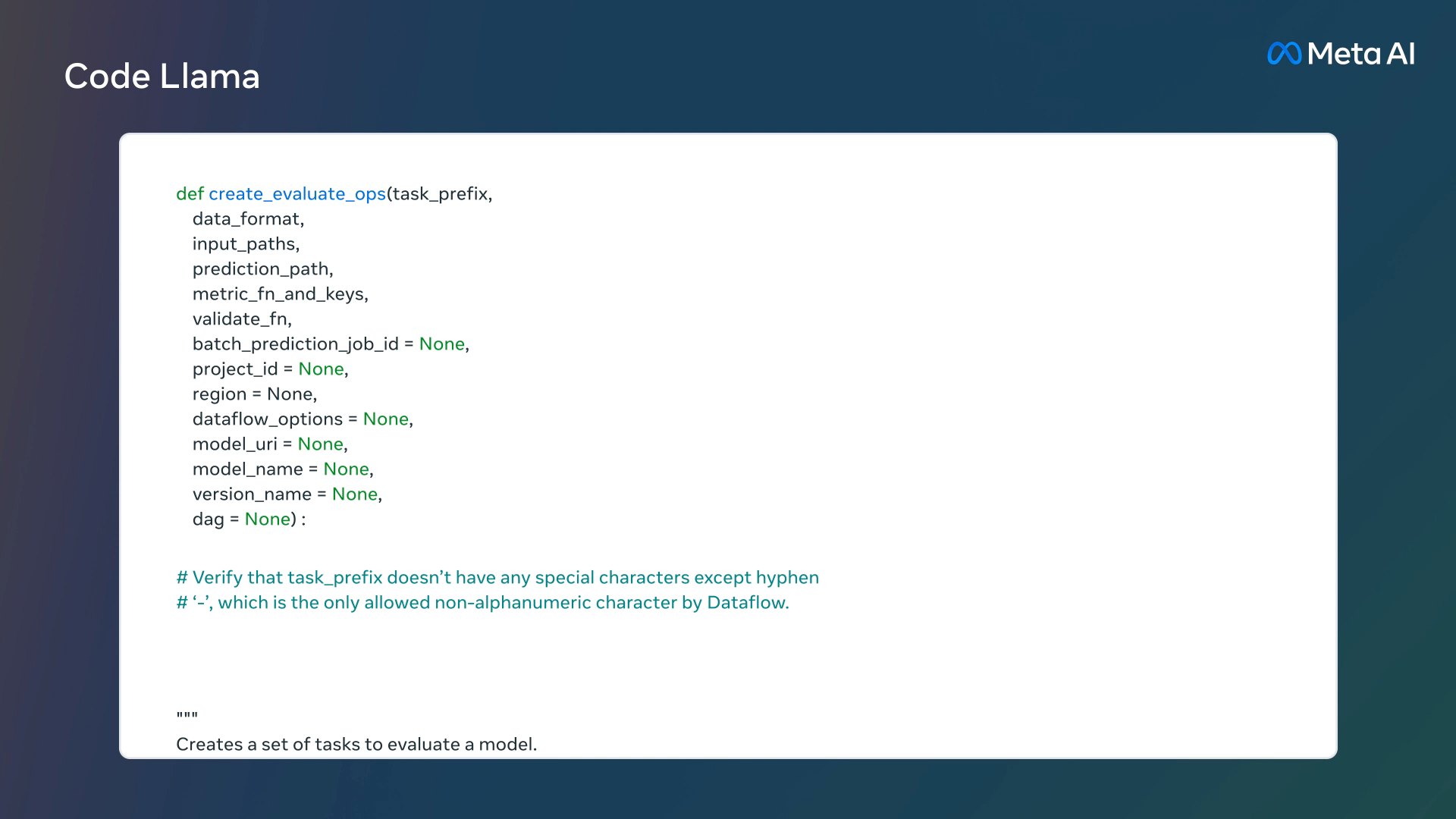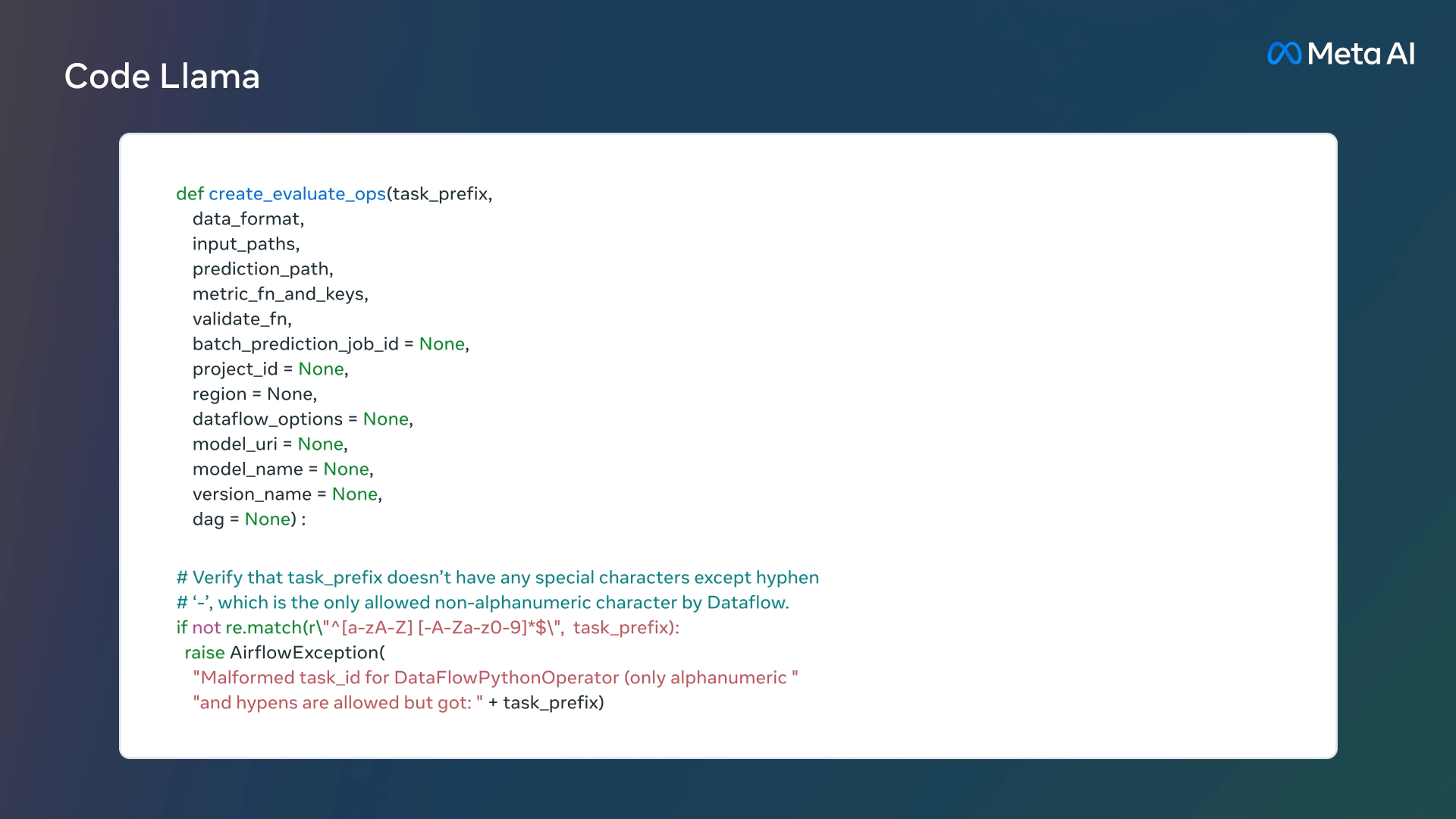
Code Llamaは最大10万トークンと非常に長い文脈で安定した生成をを提供するため、ユーザーはモデルに対して自分のコードベースからより多くの文脈を提供することが可能になる。
また、大規模なコードもまとめて入力できるので、より大きなプロジェクトのデバッグ作業にも対応可能だ。
Pythonに特化した「Code Llama - Python」
Pyton
さらに、Code Llamaを100B(1000億)トークンのPythonコードでさらにファインチューンした「Code Llama - Python」も用意されている。
メタは「Pythonはコード生成のための最もベンチマークされた言語であり、PythonとPyTorch(ディープラーニング関連ライブラリー)はAIコミュニティで重要な役割を果たしているため、特化したモデルはさらなる有用性を提供する」としている。

各モデルのトレーニング方法
また、ベースモデルに自然言語で入出力可能になるよう微調整された「Code Llama - Instruct」も用意されている。実際に自然言語でコード生成したい場合はこのモデルが推奨されている。
ベンチマークでも好成績を達成

HumanEvalおよびMostly Basic Python Programming(MBPP)による一般的なコーディングベンチマークの結果、Code Llamaはいくつかの項目で最先端の性能を達成。ベースとなったLlama 2やOpenAIの「Codex」といったコードに特化したLLMよりも優れた性能を発揮した。
メタは本モデルを使い「開発者がワークフローをより効率的にすることで、反復的な作業ではなく人間中心の仕事に集中できるようにすること」を目標としている。
また、Code Llamaの無料提供は初心者や学生にとって大きなメリットとなり、コーディング学習のアクセスを容易にする一方、OpenAIのGPTを使用した「GitHub Copilot」のような有料サービスも各種IDEと統合するなど利便性が高まっている。技術の進化と共に、コーディングの風景も変わりつつある。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります