



メタ、文字と音声に対応 新AI翻訳モデル「SeamlessM4T」を公開
2023年08月23日 17時55分更新

メタは8月22日(現地時間)、音声とテキストをシームレスに認識・翻訳・出力する多言語・マルチタスクのAIモデル「SeamlessM4T」を発表した。
音声・文字はおよそ100言語を認識、音声の出力は36言語
同モデルはおよそ100言語の自動音声認識(ASR)、音声からのテキスト翻訳(S2TT)、テキストからのテキスト翻訳(T2TT)、さらに英語を含む36言語(注1)の出力をサポートする音声からの音声翻訳(S2ST)、テキストからの音声翻訳(T2ST)をひとつのモデルでサポートするオールインワン型モデル。
これまでも多くの翻訳AIや音声認識AIが登場してきたが、ほとんどが「テキスト翻訳」「音声認識」といった単機能のものだ。本モデルはマルチモーダルな入出力が可能なため、単一のモデルで複数の操作を実行できるのが大きな特徴。
メタはこのモデルを「世界共通の翻訳機を作る探求」に向けた大きな一歩と位置付け、「CC-BY-NC 4.0(出典明記・非営利目的)」ライセンスで一般公開している。
注1:音声出力に対応するのは以下の36言語
Bengali(ベンガル語)、Catalan(カタロニア語)、Chinese(Simplified)(簡体中国語)、Czech(チェコ語)、Danish(デンマーク語)、Dutch(オランダ語)、English(英語)、Estonian(エストニア語)、Finnish(フィンランド語)、French(フランス語)、German(ドイツ語)、Hindi(ヒンディー語)、Indonesian(インドネシア語)、Italian(イタリア語)、Japanese(日本語)、Korean(韓国語)、Maltese(マルタ語)、Modern Standard Arabic(現代アラビア語)、Northern Uzbek(北ウズベク語)、Polish(ポーランド語)、Portuguese(ポルトガル語)、Romanian(ルーマニア語)、Russian(ロシア語)、Slovak(スロバキア語)、Spanish(スペイン語)、Swahili(スワヒリ語)、Swedish(スウェーデン語)、Tagalog(タガログ語)、Telugu(テルグ語)、Thai(タイ語)、Turkish(トルコ語)、Ukrainian(ウクライナ語)、Urdu(ウルドゥー語)、Vietnamese(ベトナム語)、Welsh(ウェールズ語)、Western Persian(西ペルシア語)
各種テストでも過去最高記録を達成
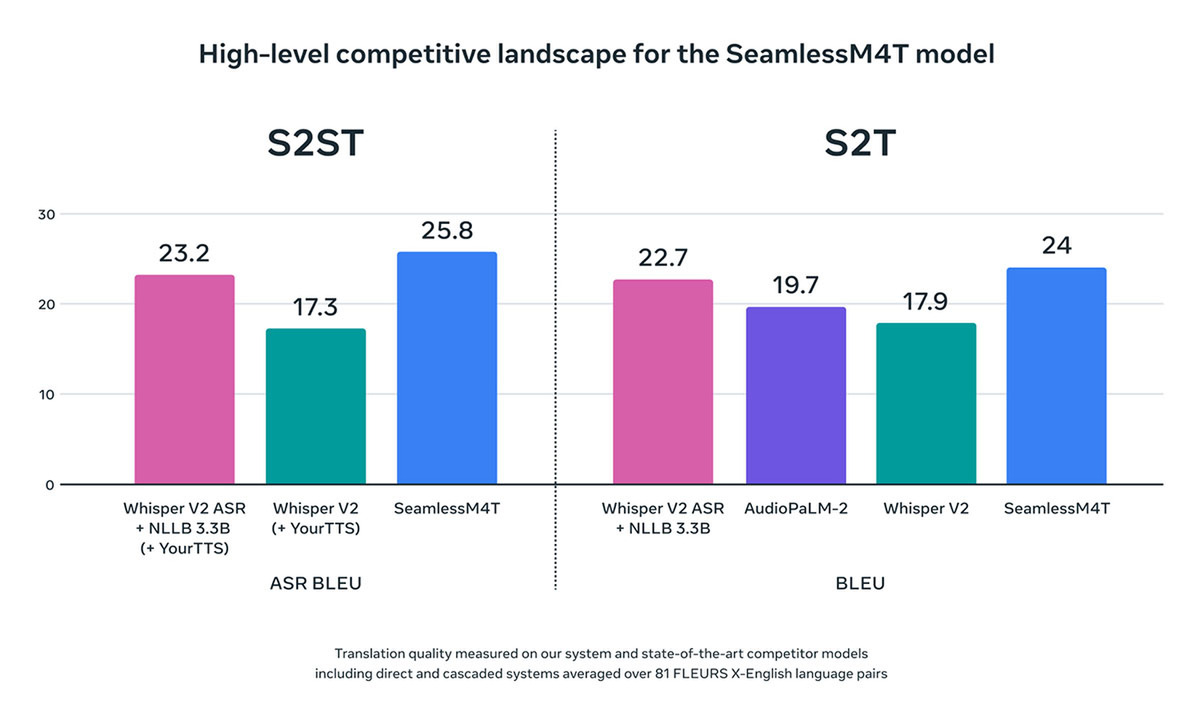
SeamlessM4Tを競合モデルと比較したところ、音声からの音声翻訳(S2ST)で過去最高の「Whisper V2 ASR(OpenAI)」から2.6 ASR-BLEUポイント、音声からのテキスト(S2T)では同じく「Whisper V2 ASR」から1.3 BLEUポイント向上し、最高性能を更新している。
デモサイトで試用可能
メタが用意した特設デモサイトでSeamlessM4Tを試してみよう。

ページの冒頭には「これはデモです。不正確な翻訳を生成したり、単語の意味を間違えたりする可能性があります」と、AI系おなじみの制限事項が書かれている。「START DEMO」ボタンを押すことで録音が始まる。
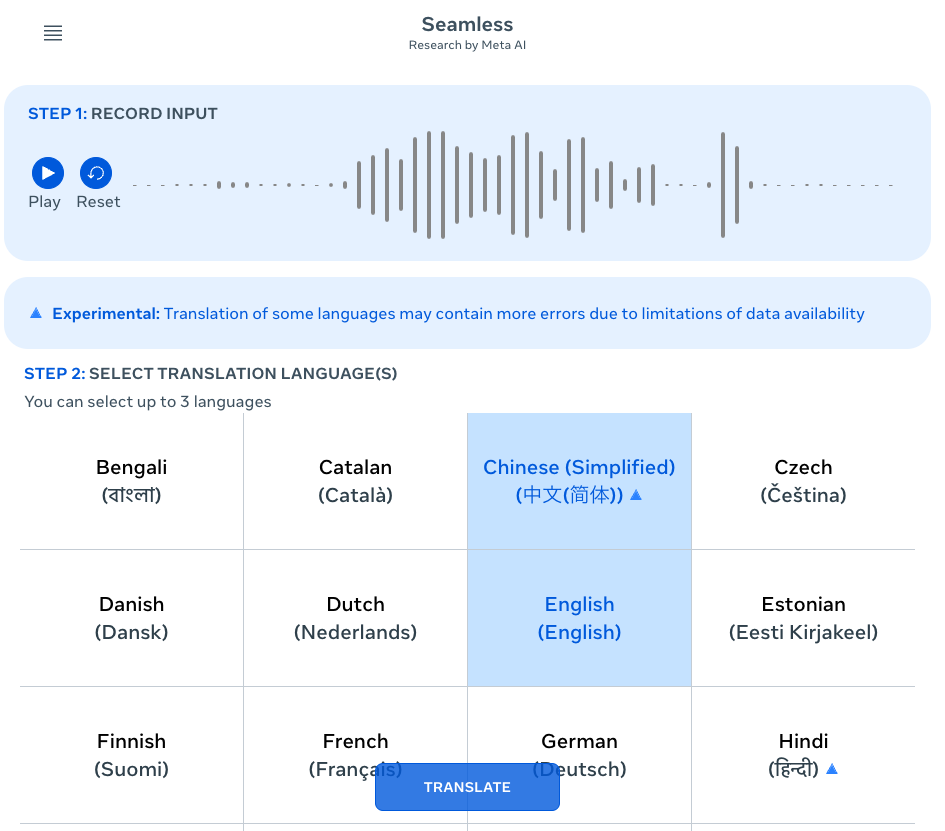
録音が終わると、翻訳したい言語を3つ選ぶことができる。選び終わったら「TRANSLATE」をクリック。
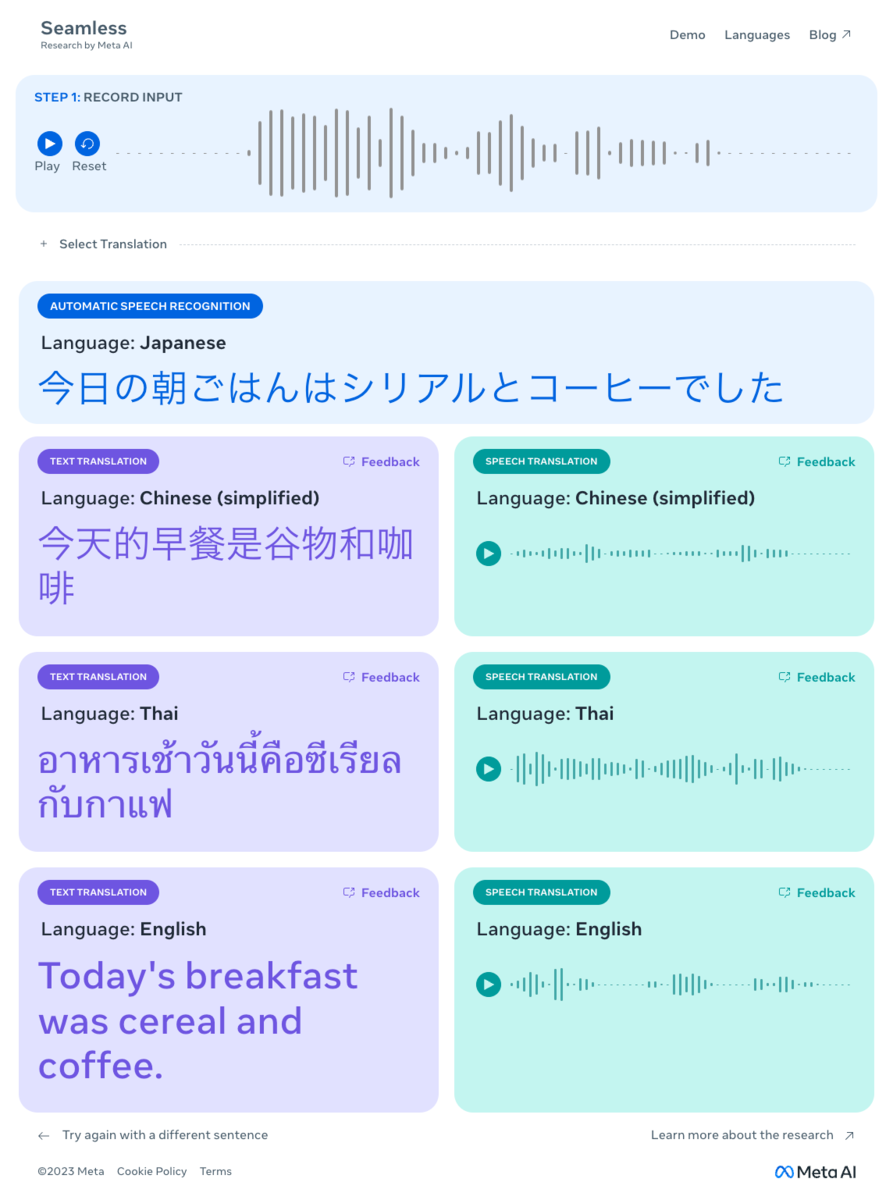
しばらく待つと、日本語での音声認識を皮切りに、中国語、英語、タイ語の3言語でテキストと音声による翻訳が表示された。簡単な例文ということもあり翻訳もすべて正解だった。
メタが開発する翻訳ツールの集大成
メタはこれまでにも、200の言語をサポートするテキストからテキストへの機械翻訳モデル「NLLB(No Language Left Behind)」、音声合成翻訳システム「Universal Speech Translator」、1100以上の言語に対応する自動音声認識、言語識別、音声合成を提供する「Massively Multilingual Speech」といったAIを利用した翻訳システムを発表している。
SeamlessM4Tは、これらすべてのプロジェクトで得られた知見を活用し、幅広い音声データソースと最先端の結果に基づいて構築された単一のモデルから生まれる多言語・マルチモーダル翻訳ソリューションということになる。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります