



グーグル DeepMind、ロボット向けAI「RT-2」開発
2023年08月01日 18時15分更新

グーグル傘下のGoogle DeepMindは7月28日(現地時間)、視覚と言語を行動に変換できる世界初の視覚言語行動(VLA:vision-language-action)モデル「RT-2(Robotics Transformer 2)」を発表した。
ロボット学習の課題
現在、様々な分野でロボットは活用されているが、基本的にはあらかじめプログラムされた動作しかできない。
ものすごいスピードで自動車を組み立てる能力を持つ高性能ロボットでも、「目の前に置かれた3つの物体の中からリンゴを選び、それを青い箱に移動させろ」といった一見単純な命令を実行させることはできない。
なぜならそのロボットは、たとえセンサーでリンゴが見えていたとしても、リンゴについての知識も、それを掴んで動かす方法についての知識も持っていないうえ、そもそも自然言語で書かれた命令を理解することができないからだ。
それを可能にするためには、ロボットがリンゴを文脈の中で認識し、赤いボールと区別し、リンゴがどのように見えるかを理解し、リンゴを拾い上げる方法を知る必要がある。
そのためにはこれまで、物理世界のあらゆる物体、環境、タスク、状況において、何十億ものデータポイントを直接ロボットに学習させる必要があった。
ロボットにウェブからの知識を伝授

RT-2は、オフィスのキッチンで働く13台のロボットが17ヵ月かけて収集したデータで訓練された前身モデル「RT-1」をベースに開発された。
ChatGPTを動かしている「GPT-4」などの大規模言語モデル(LLM)と同様に、ウェブ上のテキストと画像でトレーニングされたTransformerベースのモデルで、ロボットの行動を直接制御できるよう設計されている。
一般的な言語モデルが言語や概念をウェブから学習するように、RT-2はロボットが行動を起こす時に参考になる知識をウェブから学習しており、RT-1が持つ訓練データと組み合わせることでロボットの汎化能力を向上させ、初歩的な推論能力を持つようになったという。
そのため、たとえロボットがそのタスクをこなすように特別に訓練されていなくても、ウェブからの知識を利用してパターンを認識し、アクションを実行できるのだ。
例えば、従来のロボットにゴミを捨てさせたい場合、ゴミを識別し、拾い上げ、所定の場所に捨てるよう明示的に訓練する必要があったが、RT-2はウェブデータからの学習でゴミが何であるかをすでに理解しているため、明示的な訓練なしにゴミを識別し、捨てることができる。
さらにRT-2は、バナナは食物だが、食べた後の皮はゴミになるといったゴミの抽象的な性質も理解しているという。
初見タスクの成功率をを32%から62%に向上

研究チームははRT-2モデルに対し「イチゴを正しい容器に移して」「テーブルから落ちそうなバッグを拾って」といった6,000回を超える一連の定性的・定量的実験を行った。
これらは見たことのない物体やシナリオに対してロボットに操作タスクを実行させるものであり、ウェブベースのデータから変換された知識が必要なものばかりだ。
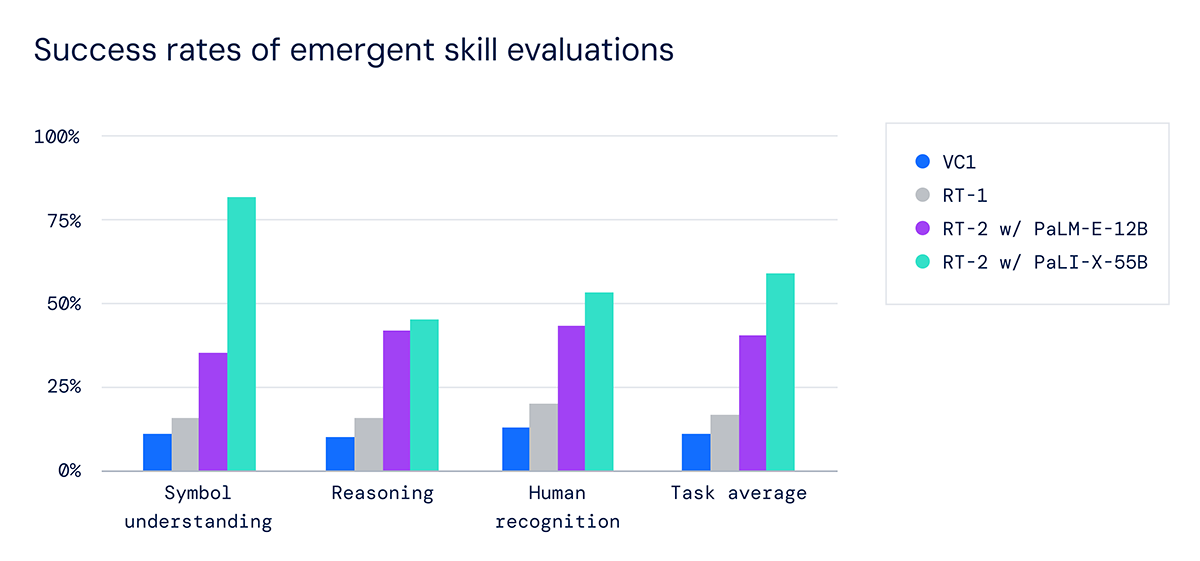
その結果、以前のRT-1モデルや、Visual Cortex(VC-1)のような大規模な視覚データセットで事前に訓練されたモデルなどと比較して、汎化性能が3倍以上向上した。
また、RT-2はベースとなるRT-1のパフォーマンスを維持しつつ、完全に見たことのないタスクの成功率ををRT-1の32%から62%に向上させた。言ってみればロボットが人間のように学習できるようになったのだ。
RT-2は、AIの進歩がロボット工学に急速に接近していることを示すだけでなく、より汎用的なロボットの開発にも大きな可能性を示している。人間中心の環境で役に立つロボットを実現するためには、まだまだ多くの作業を行う必要があるが、RT-2は、ロボット工学のエキサイティングな未来がすぐそこまで来ていることを示している。
Google ResearchのBrainチームとDeepMindの統合により今年4月に新たなスタートを切ったGoogle DeepMindの最終目標は、SF作品に登場するロボットのように、人間の環境をナビゲートできる汎用ロボットを作ることなのだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります