



第879回
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略
2026年06月08日 12時00分更新
多波長・低速化(DWDM)がもたらす
圧倒的な省電力と低遅延のメリット
この後、DWDMを構成するためのコンポーネントの分析など問題点などが論じられているがここでは割愛する。シミュレーションでは、同じ200Gbpsのリンクを構築するのに8波長×25Gbpsは3.4pJ/bitで済むのに2波長×100Gbpsでは4.7pJ/bitと大差がついたことが示されている。
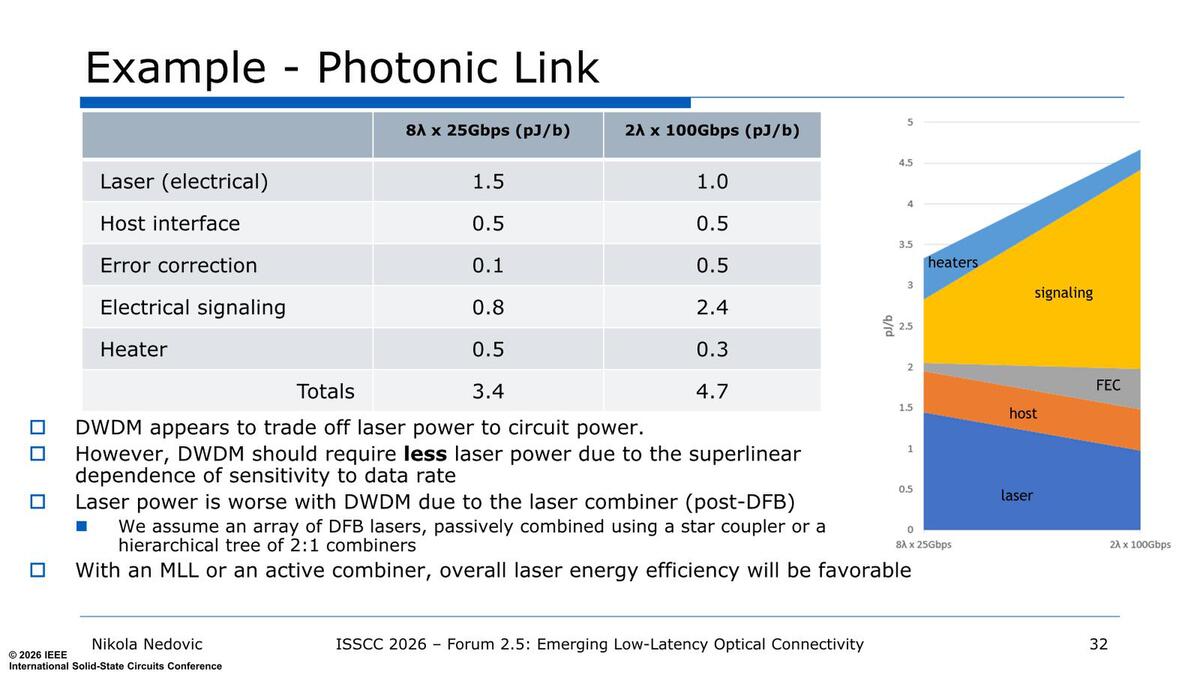
エラー訂正の消費電力が桁違いに小さくなっているのがわかる。レーザー出力だけでは8波長の方が多いが、これは4つのレーザー光を2つに分割して8本にする仕組みを入れている関係とのこと
同様にPHYに関しても、例えば224Gbps(112GT/secのPAM4)×1と32Gbps NRZ×9では、消費電力も少なくプロセスノードも古いもので良く、それでいてArea BW Density(単位面積あたりの転送速度)は大きく、レイテンシーも少ないとされている。
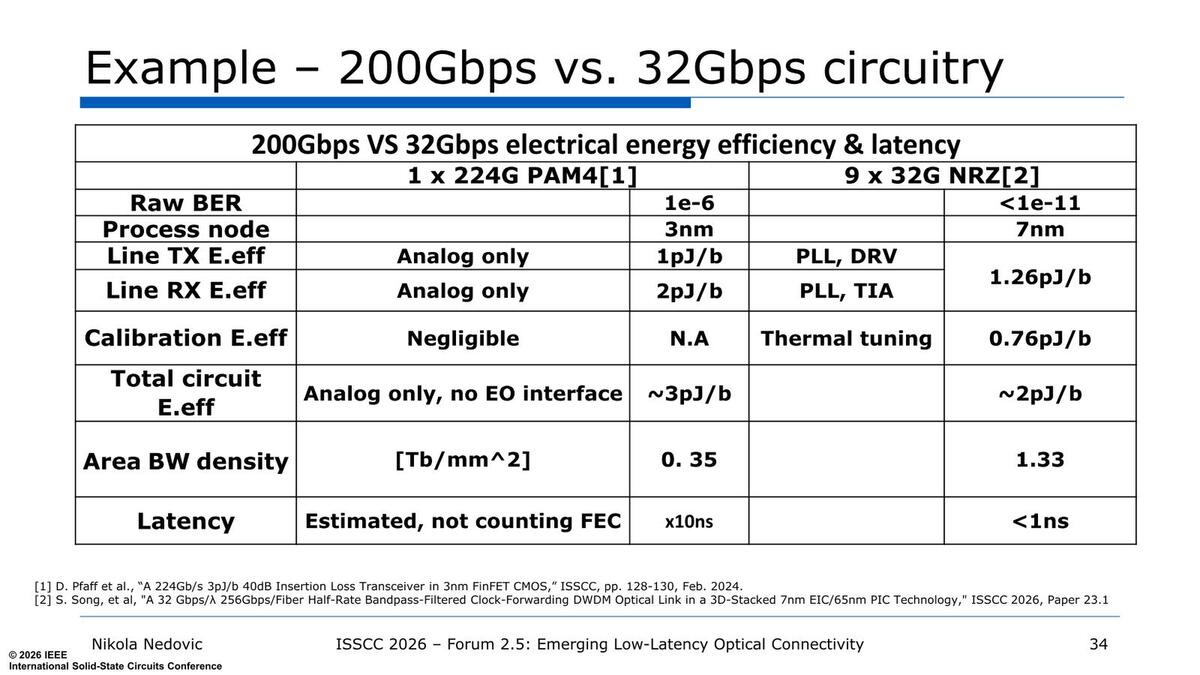
GPUの内部は数GHzの動作周波数で、メモリーI/Fでもせいぜい10GHz程度なので、224GHzもの信号になると1:20や1:30などの速度変換が必要になる。32GHzでは1:3~4程度の速度変換で済むあたりが楽だし、信号速度が低ければ消費電力も減るわけだ
これを利用する、「近未来の」スケールアップ・ネットワークの構成図が下の画像だ。左はやや先(LightMatterのPassageを連想する)な構成で、最初に出てくるのは右側の方だろう。
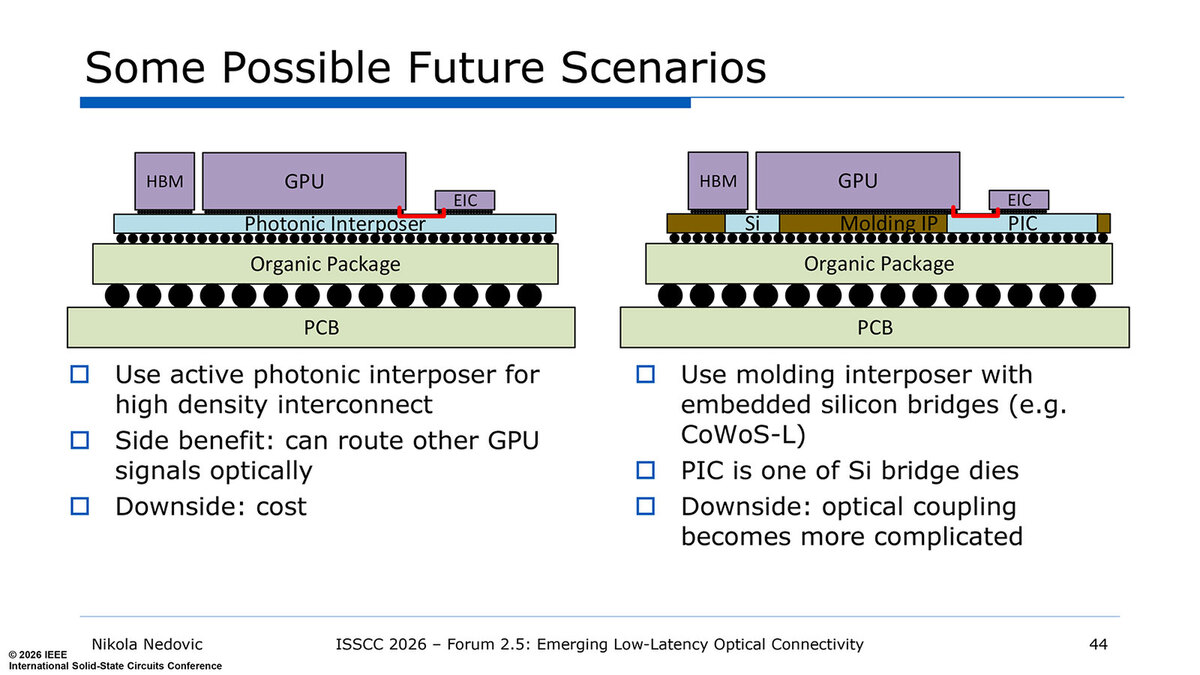
近未来のスケールアップ・ネットワークの構成図。LightmatterのPassageは連載839回で説明している
将来的にはシャーシ内の複数のGPUや、1つのパッケージ内の複数のGPUダイを直接光信号でつなぐ格好だろう。これが一番オーバーヘッドが少ないからだ。とはいえ、短期的にはシャーシ内は電気信号、シャーシ間を光信号という使い分けになる(おそらくNVLink 8はこうなるだろうと筆者は予想している)が、それは左側の構造に近いものになると思われる。
今回は2月の発表なので、3月のどんでん返しの話は反映されていないが、もう水面下でいろいろ仕込まれていたことが透けて見える内容であった。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります