



第879回
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略
2026年06月08日 12時00分更新
ミリ秒の遅延も許されない学習・推論
ボトルネックとなるFEC(誤り訂正)の壁
ではなぜ複数枚/ラックの規模ではスケールアップ・ネットワークが必要なのか? というのがここからの説明。まずトレーニングの場合では、複数のGPUに分散させる形で学習に必要となる計算をさせるわけだが、層ごとに結果の集計(All Reduce)の処理が入る。

正確に言えば集計ではないのだが、雰囲気としては伝わるだろう
ということは複数のGPUを同期させて結果を集める必要があるわけだが、この同期をどうやって取るかといえば当然ネットワーク経由である。したがって、ここのレイテンシーが大きいと同期をとり終わるまでの待ち時間が長くなる。
このAll Reduceの頻度が少なければそれほど問題はないのだが、実際はかなりの回数が実施されるわけで、塵も積もれば山となる。一方推論は? というのが下の画像だ。
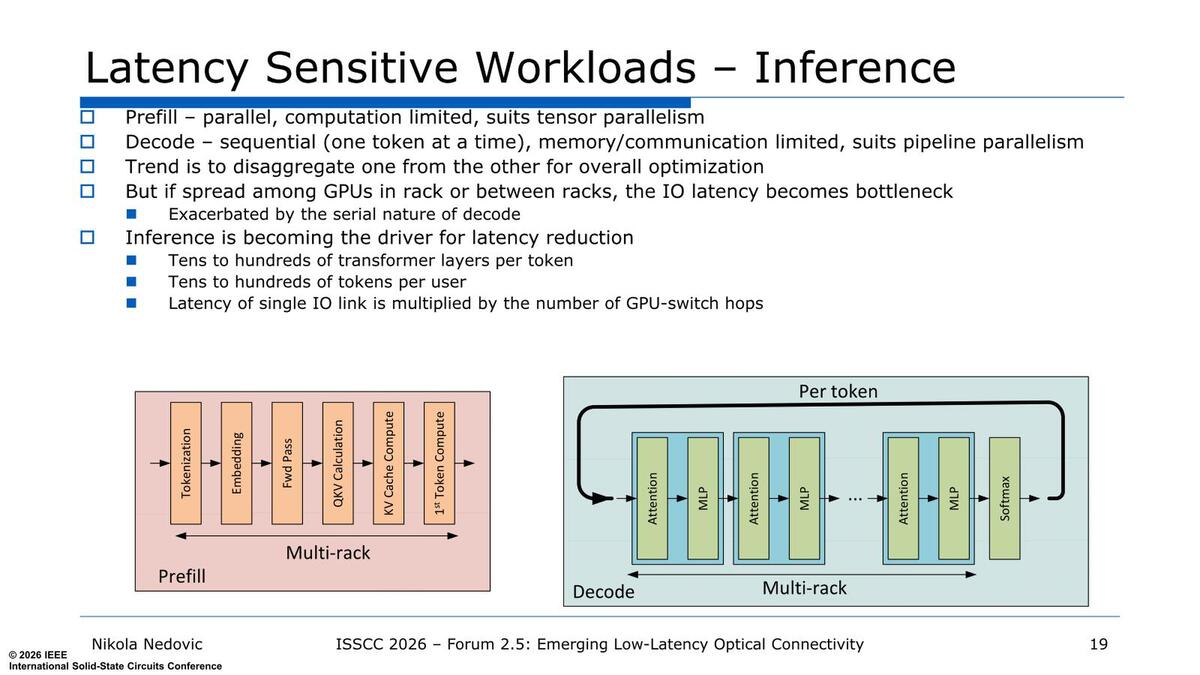
ここにもあるが、トークンあたり数千層の処理があり、そのトークンがユーザーごとに数千個生成されると、合計で数百万~数千万層の処理が行なわれる計算になる。当然レイテンシーはこの数との乗算になるため性能に直結するわけだ
連載871回のスライドに話が戻るのだが、プリフィルに関しては1回通るだけである。ところがデコードに関してはトークンが来るたびにこれが何度でもぐるぐる回ることになる。
連載871回のスライド
1枚のGPUの中でこれが回っているのなら別に問題はないが、問題は処理ごとに、場合によっては異なるラックに設置された異なるGPUに処理結果を送って次の処理が行なわれる、というケースもあり得るわけで、こうなるとレイテンシーが猛烈に性能に効いてくることになる。これが従来のネットワークのままでは厳しいということでスケールアップ・ネットワークとして新たに注目を集めている理由である。
さてではどうやってスケールアップ・ネットワークを構築するか? 下の画像は「現在の」光イーサネットをベースにした場合のレイテンシーを細かく分析したものである。

"Scale upのBreakdown"とは書かれているが、実質的にはScale outのBreakdownである。で、赤字が問題になる部分である
この中でどうにもならないのが、媒体(つまり光ファイバー)を信号が通る時間で、ラフに言って5ns/mほどになる。これも最近はHCF(Hollow core fiber:中空コアファイバー)が出てきて、従来より3割ほど高速(ガラスやプラスチックより空気の方が伝達速度が速い)になるという話なので、これを使うと3.5ns/mほどになるが、それは媒体の話なので置いておく。
まずPHY層で言うとSerDes(信号の変換)+DSPによる処理+AFE(Analog Front End:電気的な信号の増幅)で50ns、FEC(Forward Error Correction)で50~100ns、データリンク層での暗号化を施すとそこで0~50ns、そしてスイッチ内部で100~200nsのレイテンシーがそれぞれ必要になる。
つまりそのほかの要因を一切考えず、ケーブルが2mだとしても320~620nsのレイテンシーが発生する。これはGPU同士の同期をとるためのレイテンシーとしてはかなり厳しい数値である。
ではこれをどうするか? まず簡単にできる案としては、Fat-TreeにしてもLeaf-Spineにしても、複数のスイッチをネストさせる形で接続するため、Fat-Treeにおけるエッジ、あるいはLeaf-Spineにおけるリーフレベルで通信ができればいい。
しかし、コアだのスパインだのまでパケットが迂回すると、それだけでレイテンシーが爆増する(1段増えるだけで2回スイッチを経由するため、それだけで200~400nsのレイテンシー増になる)。そこでスイッチは1段だけで済むようにスイッチのポートを増やす必要がある。
またNVIDIAで言えば従来は1本のラックに72枚のGPUカードだったので、これに向けて構成を最適化する(より大規模な構成は考えない)などがアーキテクチャーや構成レベルで可能なことである。そしてその下のレイヤーでいえば、もうとにかくPHYとMACの最適化でしかない。
ここで槍玉に挙がるのがFECである。例えばイーサネットの場合、50Gbps以上のもので広く利用されているのがRS FEC(544,514)である。これはReed-Solomon Forward Error Correctionと呼ばれるもので、514bitの送信データを544bitのシンボルに変換して伝送する仕組みで、1つのシンボルに対して最大15のエラーを訂正可能な強力なものである。
実際100Gイーサネットや200Gイーサネットでは、このFECがないとBERが10-6オーダーなのに、FECを併用することで10-12オーダーまでエラーを減らせる。ただし副作用もあり、これを利用するためにはDSPをブン回して計算する必要があり、これだけで100ns程度のレイテンシーが追加される。
DSPはこれ以外にもいろいろな処理をしている。例えばデジタルフィルターを使ったDFE:Decision Feedback EqualizationもDSPで処理されることが普通である。したがって、このDSPの消費電力の多さとレイテンシーの大きさはいかんともしがたい。
ただFECに関しては、FLIT(Flow Control Unit)という新しい再送メカニズムを併用することで負荷を減らせることはすでにPCI Express 6.0の世代で実証済である。これは軽量なFEC(例えば25GイーサネットのRS-FEC(528,514)のように、計算負荷が低いもの)を前提にしたものだ。軽量なFECでは、完全にはエラーを訂正しきれない。そこでエラーがあったときは再送することでカバーするという発想だ。
再送すると100ns程度のレイテンシーが追加されるので従来のFECと変わらないが、常時100nsのレイテンシーが必要な従来のFECと比べると、ほとんどは数十ns(RS-FECの選択次第では10ns台)のレイテンシーで済み、たまに100nsになるのと、トータルでどちらがレイテンシーが少ないかという選択である。

もうこのあたりから、イーサネットなどの既存の規格との互換性を捨てて、なりふり構わずレイテンシーを削減しないといけないという決意が読み取れる
また、そもそもFECやDFEがなぜ必要か? といえば信号速度が高くてSN比が悪化しているからで、信号速度を落とせば強力なFECやDFEがなくてもエラー訂正の必要性が下がるため軽量なFEC/DFEで済み、それだけレイテンシーが下がるメリットがある。
あとCPOに代表される構造は、電気信号の配線を最小化できるのでAFEの必要性を最小限にしてくれるし、そのCPOをASICとシリコン・インターポーザー経由での配線にできれば、この配線によるレイテンシーも最小化できることになる。
ただし、信号速度を落としたらそれだけスループットも減ってしまう。これをどう補うか? というのがWDM(Wavelength Division Multiplexing:波長分割多重)である。これは、1本の光ファイバーに多数の光信号を同時に通せば、信号あたりの速度が遅くてもトータルでのスループットが稼げるという話である。
WDMにはCWDM(Coarse WDM)とDWDM(Dense WDM)があり、要するにその光の波長をどのくらい変えるかという間隔である。CWDMの場合、1310nm帯の場合では1270nm~1610nm程度の範囲を20nm間隔で最大18波長ほど多重化する。
一方DWDMの場合、現時点では1530~1565nmあたりの波長を利用するが、その際に0.4nmあるいは0.8nmという非常に波長差の少ない光信号を利用する形になる。このあたりはどのくらいの距離をどんな光ファイバーを使うか、トータルとしてどの程度の帯域が必要なのかで利用する波長が決まってきた経緯があるのだが、Nedovic博士的には、もう互換性をどうせ考えないのなら帯域を引き上げやすい(=多重化する波長を増やしやすい)DWDMに魅力を感じているようだ。

波長を増やす(=信号速度を落とす)もう1つのメリットはPAM4などの複雑な変調を使う必要もないことである。また従来DWDMは長距離向けということで高出力のレーザーが必要だったが、スケールアップ・ネットワークではそれこそシリコン・フォトニクスベースのレーザーでも十分な出力が得られるから、コンポーネントの数を減らせる&小型化できるのもメリットとしている
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります