



第872回
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界
2026年04月20日 12時00分更新
NVL576の真実
キャッシュ・コヒーレンシーの壁とNVL288×2の推定
さて話を戻す。最初のページの最後の画像で示したCompute Bladeであるが、実際には下の画像のようにRubin Ultraが実装されると考えた場合、NVSwitchを搭載したSwitch Bladeとの組み合わせは、その下の図になるのではないかと想定される。

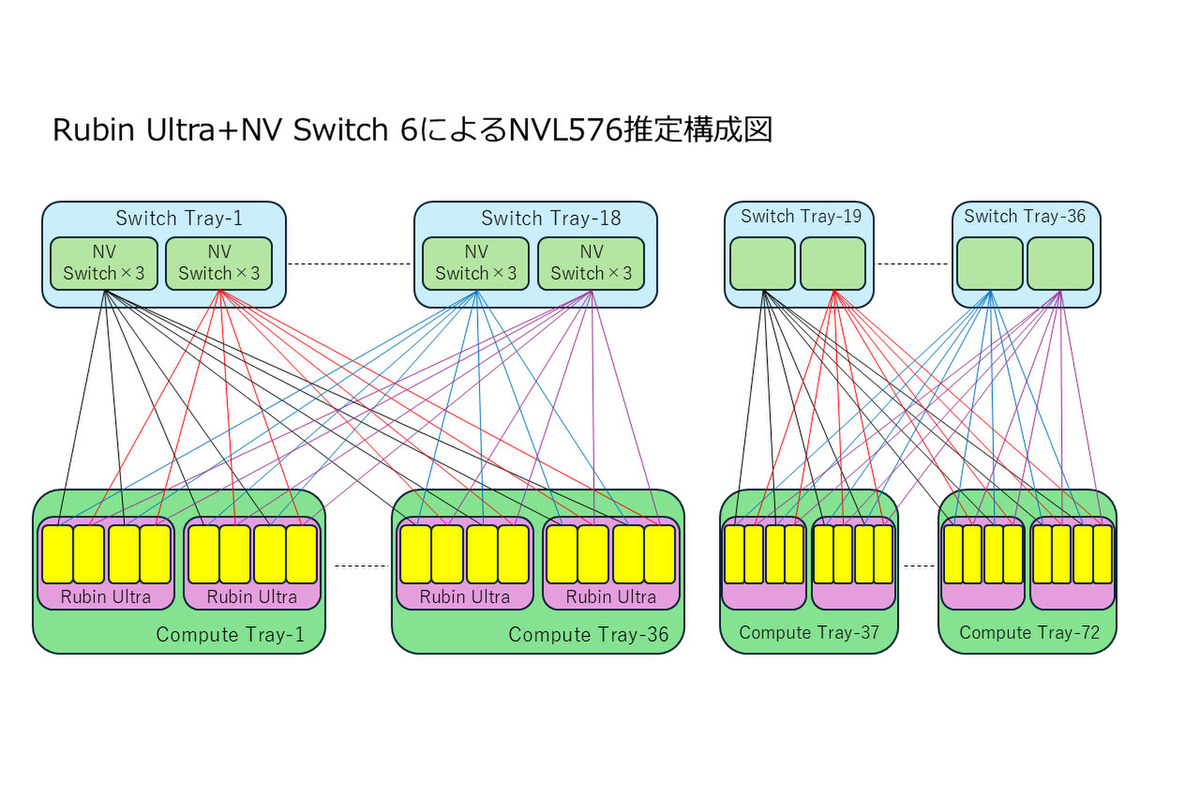
前述したとおり、Kyber Rackでは18枚のCompute Bladeを一塊にして、これが4つ縦方向に並んでいる。間をつなぐのはSwitch Bladeだが、この長さはどう見ても2塊分しかカバーしていない。したがって、4塊全体で相互接続しようと考えた場合、Switch Blade同士の相互接続を考える必要があるのだが、改めて下のSwitch Bladeを見ていただくとわかるように、そういったポートは特に見当たらないからだ。

Rubin UltraのSwitch Blade
上の画像で言えば、上側はMidplaneに接続される部分なので、ここはGPUとの接続用である。すなわち、もしSwitch Blade同士を接続しようと思ったら、Switch Blade下側にポートが山のように並んでいないといけないのだが、どう見てもそういうポートはない。
左端にあるのは管理用かなにかのイーサネットの口であり、NVLink同士の接続に使えるようには見えない。なので実際にはNVL576(GPUダイが576個)と言いつつ、NVLinkでキャッシュ・コヒーレンシーを保つ形で利用できるのは半分の288個まで、つまり実質NVL288×2構成になっていると筆者は推定する。
理由はなんとなく想像できる。パッケージとしてはダイで1チップなので「144パッケージ」ではあるのだが、144という数字ですらキャッシュ・コヒーレントを取るのには十分に大きい。そして576はさらに厳しいからだ。そもそもNVLink、当初はPCI Expressに代わる高速なインターコネクトで、そこに付随してキャッシュ・コヒーレンシーが追加されていた。この目的はCPUとGPUのメモリー共有である。
連載340回で紹介したが、IBMがオークリッジ国立研究所とローレンスリバモア国立研究所に納入したSummitおよびSierraというスーパーコンピューターはPOWER9とVoltaを組み合わせたハイブリッド構造であるが、この接続にIBMはCAPIを導入。NVLinkはこのCAPIに準拠する形で実装された。要するにPOWER9とV100の間でキャッシュ・コヒーレントを取れる構造だ。
ただV100同士のキャッシュ・コヒーレントが取れたか? というとこれはまた別の話だったわけだが、Hopper世代からはこれが可能になっている。つまりあるSM(Streaming Multiprocessor)が別のSMの共有メモリーを直接アクセスできるようになった。Ampereの時代にもGlobal-to-Shared Asynchronous Transferと呼ばれる仕組みがあったが、Hopperの世代では完全にキャッシュ・コヒーレンシーをサポートするようになっている。
一般論になるが、キャッシュ・コヒーレントを実現する場合には、それを維持するためにSnoopingと呼ばれる処理が必要になる。Snoopingに必要なトラフィックは、ノードの数のほぼ2乗に比例する形で増加する。例えば2つのノードでキャッシュ・コヒーレントを維持するために必要なSnoopのトラフィック量を1とすると、3ノードでは3、4ノードでは6、5ノードで10という具合に増えていく。
もちろん、これはどんなアクセスの仕方をするか次第であって、例えばLLMの巨大なパラメーターを複数のGPUに分散させて格納し、それを随時読み出しながら処理するようなケースでは、そもそも書き換えが発生しないためSnoopのトラフィックは最小である。
逆に前回説明した、TransformerのPrefillにおけるKVキャッシュの構築などはハンパない頻度で書き換えが発生するので、これをキャッシュ・コヒーレントの対象にするとSnoopのトラフィックがすさまじくなる。そこで、こういう領域はキャッシュ・コヒーレントの対象外とし、外部のGPUには共有しないといった工夫が必要になるわけだが、ノードの数が増えるとどうしてもSnoopのトラフィックは増える。
NVL72のトラフィック量を基準にすると、NVL144はNVL72の4倍、NVL288では16.2倍、NVL576なら64.8倍まで増えることになる。したがって、全体を1つのノードとするのではなく、NVL288×2という構成にすると、トラフィックは32.4倍になり、ほぼNVL576の半分に減ることになる。Snoopのトラフィックは性能向上にまったく関係ない部分なので、これを減らすことで効率を少しでも上げたかったというあたりが一番ありそうな話である。
さて、そうなるとSwitch Blade内部(Switch Bladeの写真でカバーが隠れている部分)はどうなっているのか? だが、3つのNVSwitchを組み合わせて144ポートのスイッチを構築するという下図のような構成になっているものと考えられる。2つの基板の間をさらに大量の配線で相互接続することは不可能ではないと思うが、そこまでやる必要もなさそうだからだ。
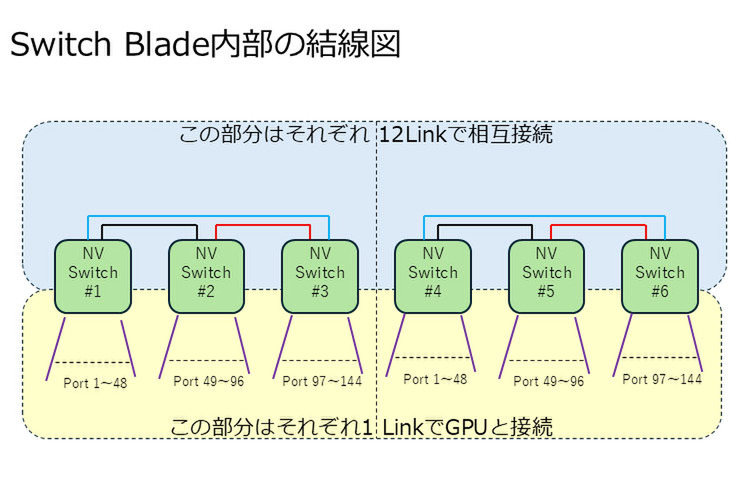
ちなみにこれはRubin Ultra世代の話であるが、次のFeynman世代も最初の製品はKyber Rackを利用することが今回明らかになっており、ここでは電気配線に加えて光配線への言及もあった。このあたりの話はFeynmanの話そのものと併せて次回解説したい。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります