



第867回
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする
2026年03月16日 12時00分更新
「魔法の25%」を生む電圧制御の妙
実効性能25%向上を実現するSpyreの知られざる内部処理
ところで先程内部が双方向のリングバスでつながっているという話をしたが、その構造が下の画像である。

リングバスの構造。冗長コアがある関係でこうにしかできなかったというのは、わからなくもない
横方向に1本あるだけでだいぶレイテンシーが減りそうな気もするのだが、それは本題ではない。Spyreの場合、周辺部は0.75Vで動作するが、AIコア部は全部0.55Vと結構低めの電圧で動作することになっている。
先にSpyreの動作周波数は2.2GHzくらいだろうと推定したが、同じSamsungのSF5を使うTelum IIが5.5GHz動作であることを考えるとかなり低めな理由の1つは、この低い駆動電圧であろう。
おそらく、300TOPSというターゲットの数値があり、これを実現する構成をダイサイズなどと勘案しながら最終的に32コアで行くという結論になり、これを2.2GHzで動かせるギリギリまで下げた結果が0.55Vというあたりだったのだろう。ここまで下げた理由は言うまでもなく75Wという枠に収めるためのものだ。
実際の消費電力は、どうしても使われ方によって変わってくるので、動的な電力管理が必要であるとした。
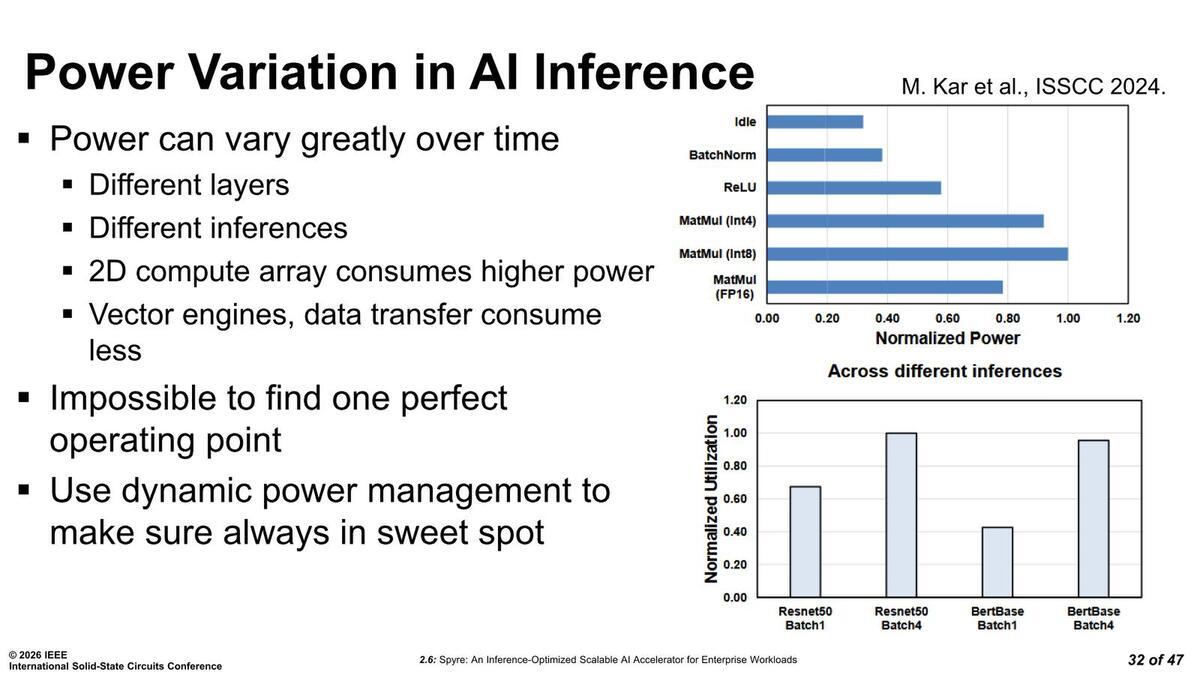
このデータは2024年に試作したチップでのデータと思われる
2024年の試作品では、AIコアの必要とする電力を測定して、それにあわせて電圧を調整するシングルループのフィードバック回路で電圧調整をしていた。
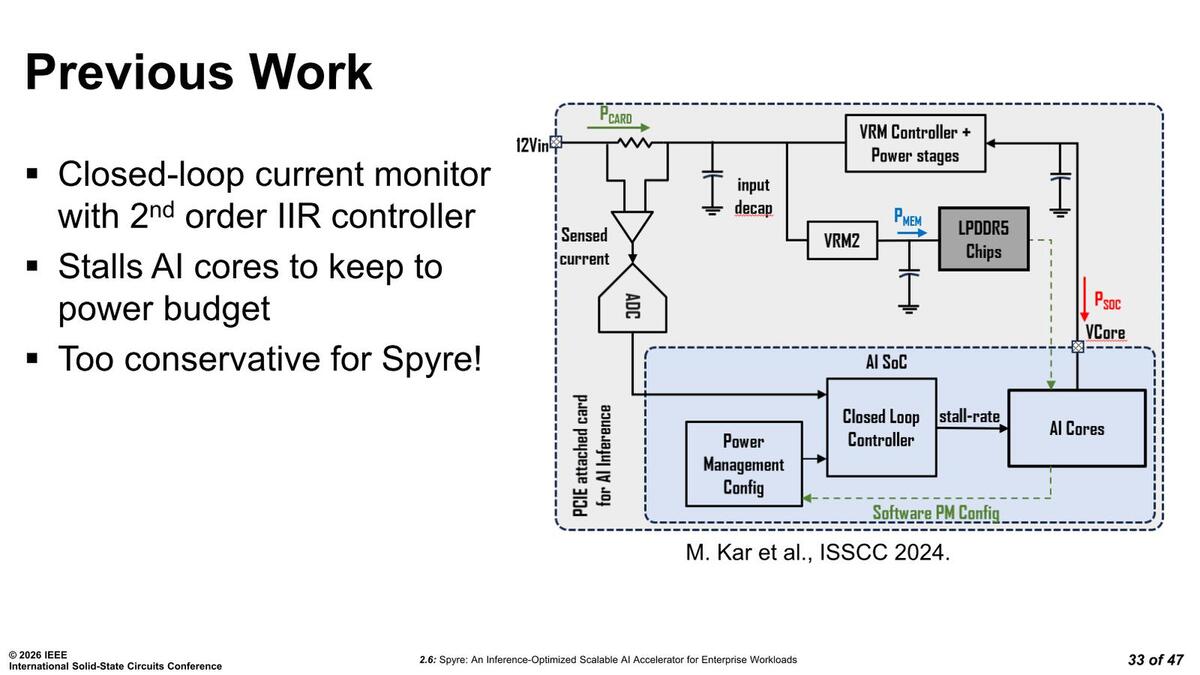
前ページ最初の画像で、カード左下に"Current sense"というチップがあるのがわかるが、これがチップに流れる電流を測定するもの(こちらの図で言えば左上、PCARDと書かれている部分)である
要するに流れる電流を測定し、基準より多くなったら電圧を微妙に下げて電流を減らし、逆に基準より少なかったら少し電圧を上げるという仕組みだ。ところがSpyreはここにデュアルループの仕組みを導入した。
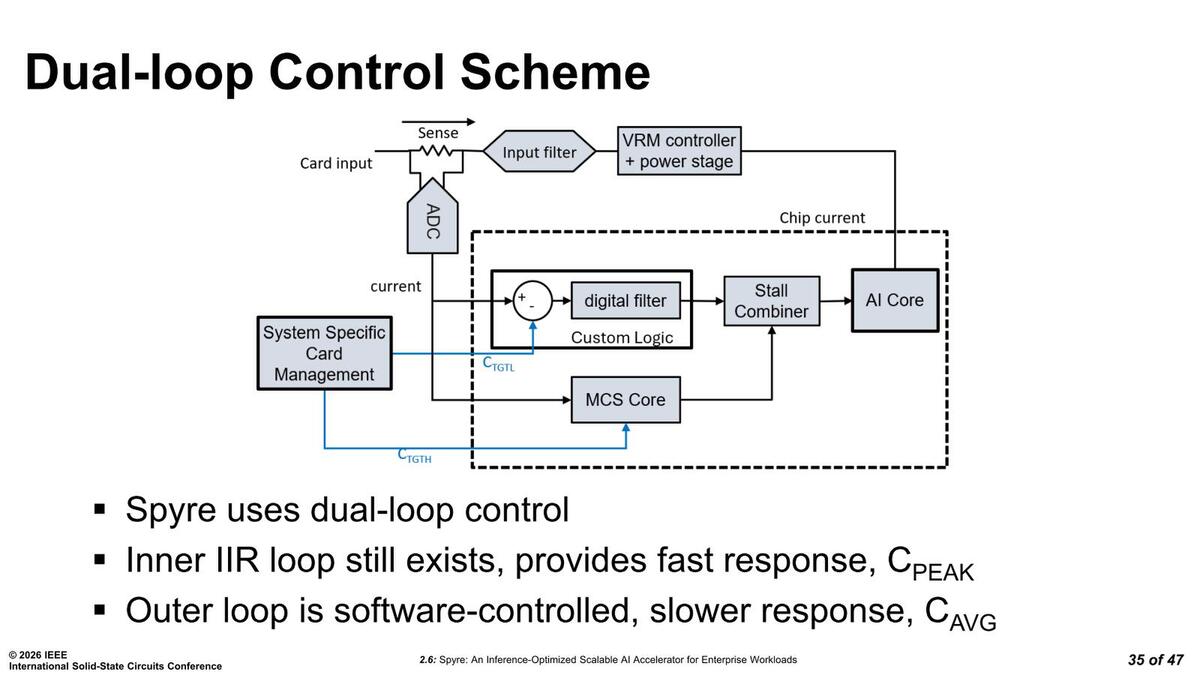
インナーループはハードウェアベースで迅速に対応するもので、アウターループはソフトウェア制御でゆっくりと制御するのがそれぞれの目的である。要するにシングルループでソフトウェア制御をすると、制御速度が十分に上がらないことへの対応というわけだ
ループ1、つまりハードウェアによるインナーループが赤い点線のループである。消費電流を測定し、その結果だけに応じてVRMが電圧の上げ下げすることで、消費電流値を一定に保てるようにするものだ。
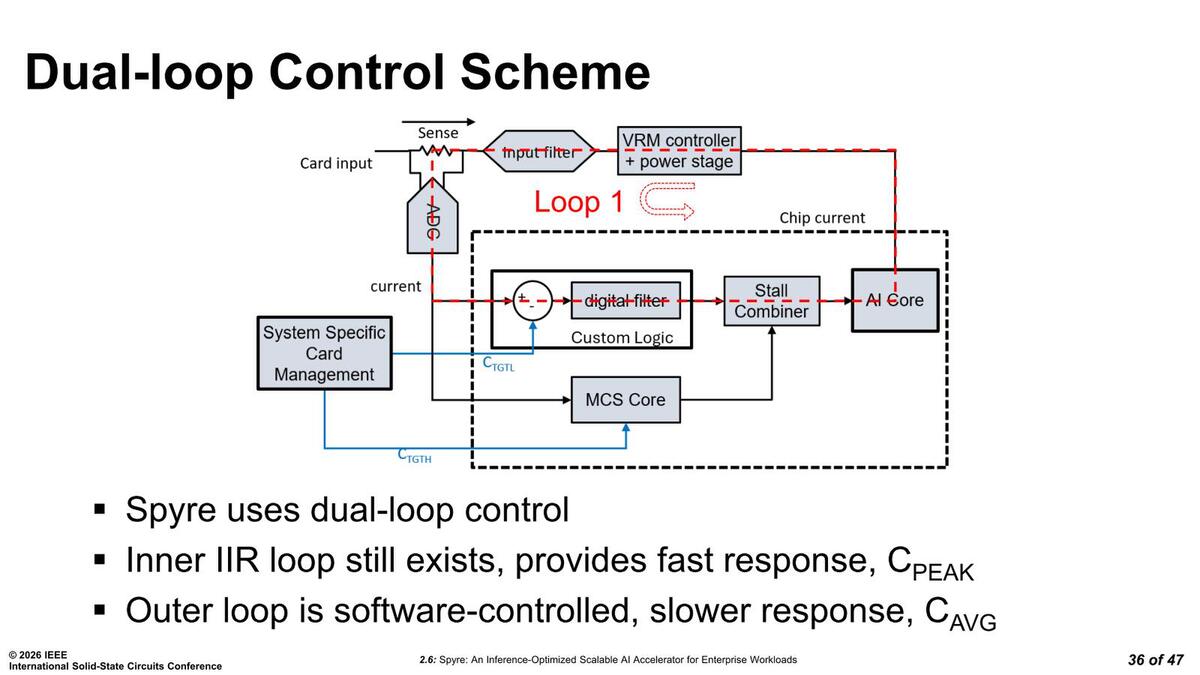
ここではパラメーターは電流だけなので、AIコアそのものの動作は一切関与しない。したがって調整できる幅はそれほど大きくない
一方ループ2、つまりソフトウェアの介在するアウターループが下の画像である。ここでは外部からSystem Specific Card Management→MCSコア経由でStall Combierと呼ばれるユニット経由で直接コアの動作を制御できる。例えば32コアのうち1つを休止させる、ということもこちらのアウターループでは可能になるわけだ。
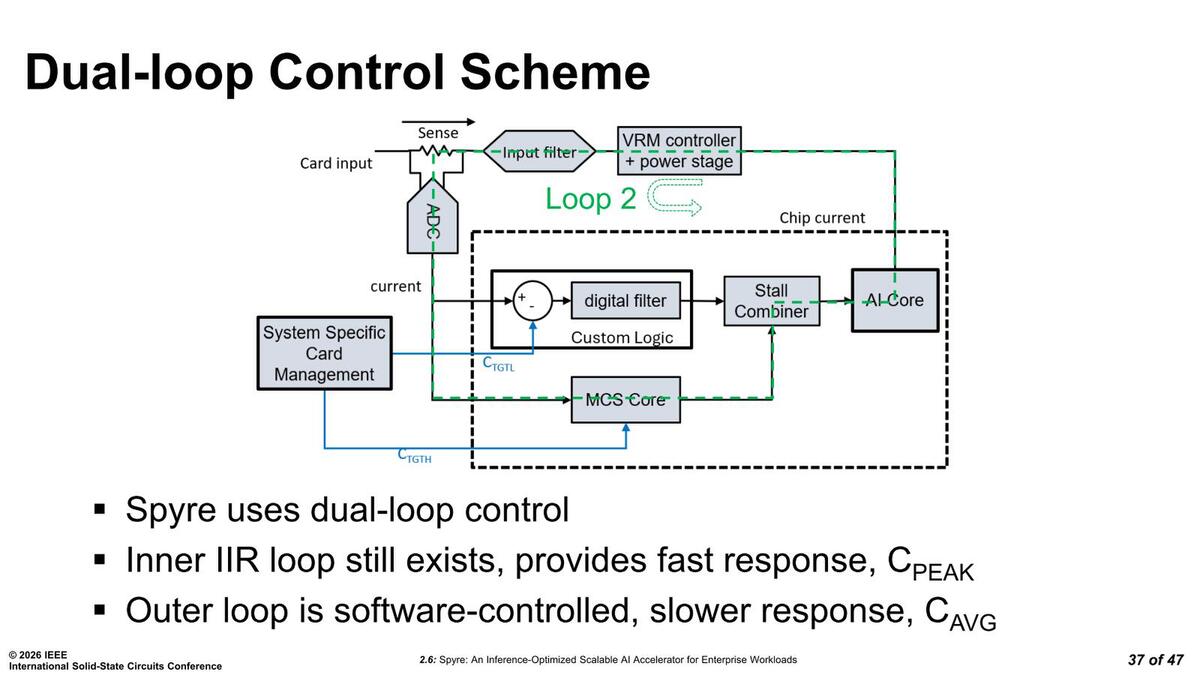
このStall CombinerはCMUに含まれているものと思われる
このシングルループをダブルループに変更したことによる性能改善効果が下の画像だ。最大で25%、という話の詳細は次に出てくるが、とりあえず動作周波数を変えなくてもここまで性能が上がる、というのは実効性能を考えると大きなメリットと言える。
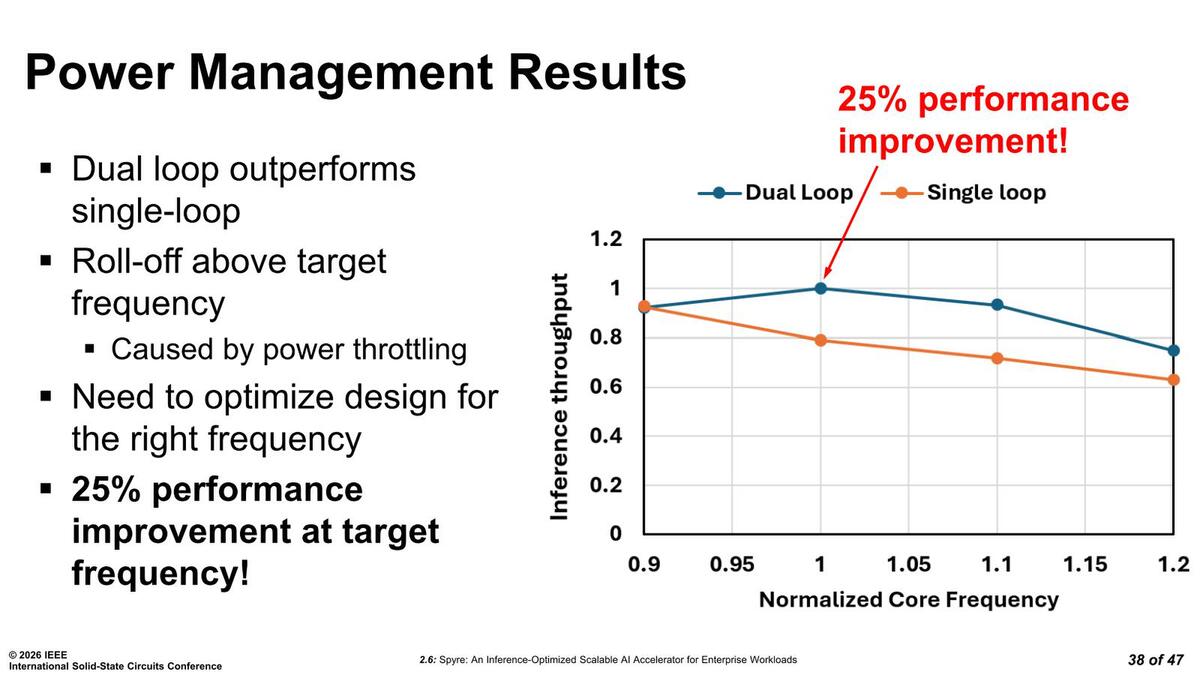
ダブルループに変更したことによる性能改善効果。逆に不思議なのは、動作周波数が0.9倍の時の効果がほとんどないことだろうか?
その内訳が下の画像。要するにAIコアが稼働中、より効果的に電流を限界まで供給可能であり、結果推論処理が早い時間に完了するので、結果として単位時間当たりの推論処理が25%高速(これまで4回処理されていた時間で5回可能になった)というのが先程の25%というわけだ。
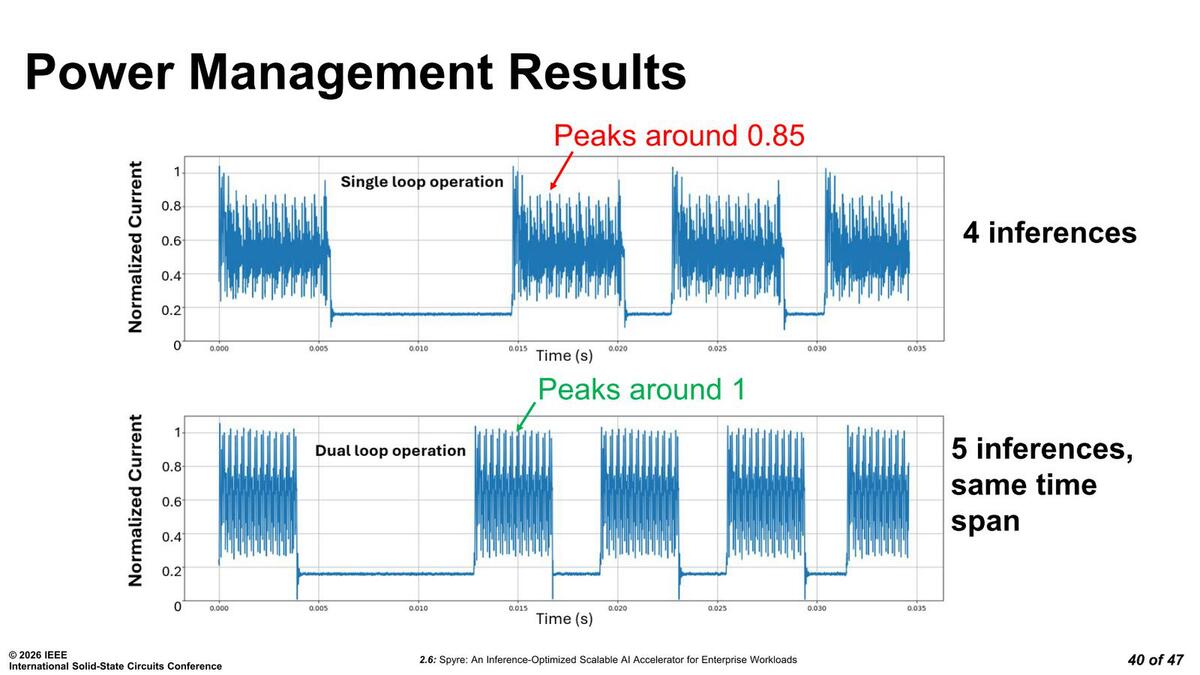
ただ逆に言えば実効消費電力は確実に増えているということもである
最後に拡張性。先程も少し触れたが、Spyre同士はPCIeに対してRDMAを実施できる。これを利用することで最大64GB/秒の帯域で接続できるので、間にPCIeファブリックを挟めば複数枚の相互接続ができる。といってもRDMAなので、Broadcastには対応しておらず、何枚同時に接続されていても基本的には1:1の通信になるはずだ。
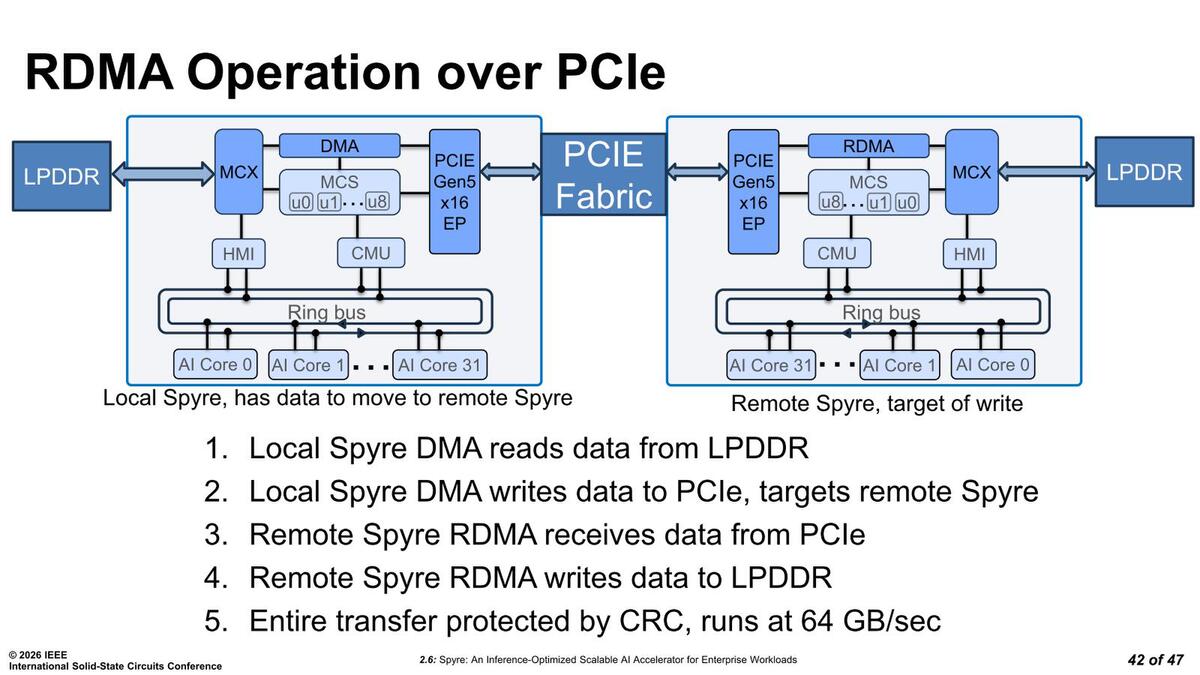
これは左から右にデータを送る手順となる。左側はDMAが動き、右側はRDMAが動く形になる
実際に大規模のLLMを動かした場合の性能で言うと、8枚程度まではそこそこにスケールする結果になったとしている。
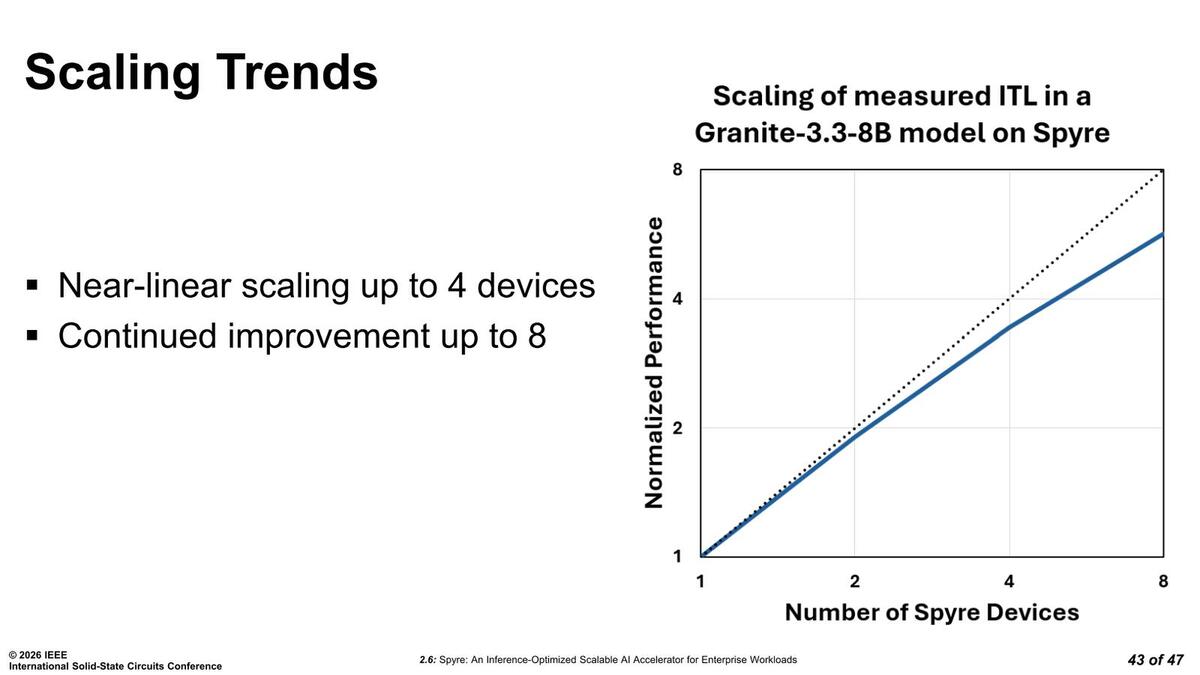
それでも8枚では実質5倍くらいの性能向上にしかならない。やはりPCIe Gen5 x16では帯域が足りないのかもしれない
実際に1/2/4枚でのTTFT(Time To First Token:最初にトークンが出力されるまでの時間)やIFT(Inter-Token Latency:続くトークンの処理時間。これの逆数がスループット)は明らかに減っていることが示された、としている。
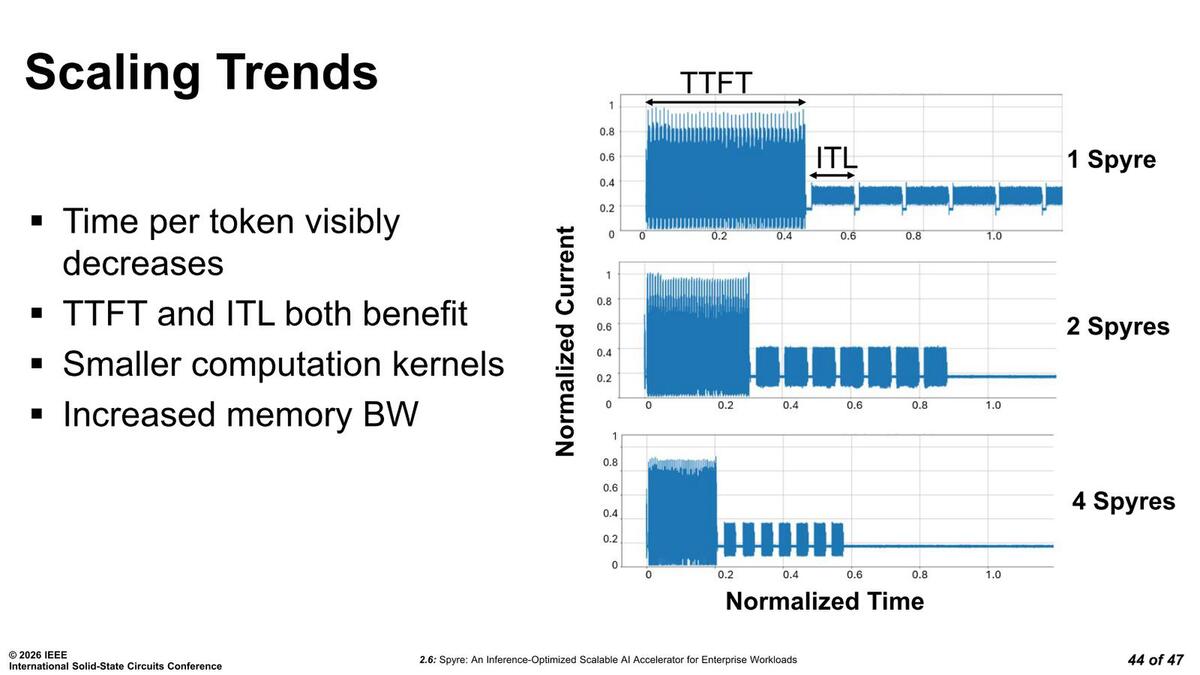
いくら処理時間が減るとはいえ、それでも半分や4分の1にはならない
全体としてはいかにもIBMらしい実装という感じであり、カードを単体で外販するというよりは同社のサーバーに合わせて提供するような形であることを考えれば、スケールアウトがPCIe経由のみというのもそれほど否定的にはならないだろう。少なくとも同社のZなりPowerなりと言ったソリューションを利用しているユーザーには、ありがたいカードであるはずだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります