



第796回
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月04日 12時00分更新
スクラッチパッドを384KBに増強
補助電源コネクターが必須に
問題はその性能だ。1.35GHz動作で、PEは64個のままで変わらない。これでGEMM(General Matrix-Matrix Multiplication:汎用行列乗算)が354TOPSとなっているから、1サイクルあたり4096Opsとなる。要するに行列乗算のエンジンの性能が2倍に強化され、それと動作周波数の向上(800MHz→1.35MHzで68.75%の向上)で3.375倍にピーク性能を高めた、という仕組みだ。
その中核である行列演算エンジンの性能は、FP16で2.77TFlops/秒なので、INT 8なら5.54TOps/秒となり、4096 Ops/サイクルでつじつまが合っている。ちなみにPE内部のスクラッチパッドも384KBに増強された。
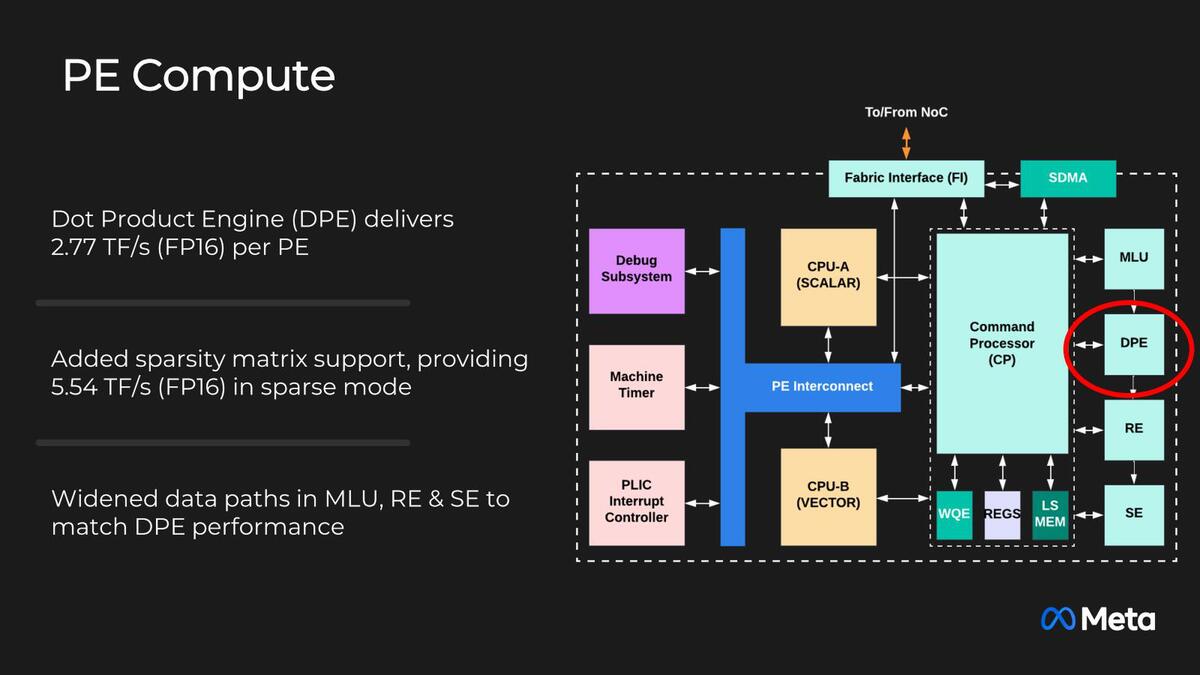
行列演算エンジンの性能。ではCPU-BのVectorはなんのためにあるのか? DPEは本当に行列演算しかできないので、その他の処理が必要になった時はVectorを使う格好になる
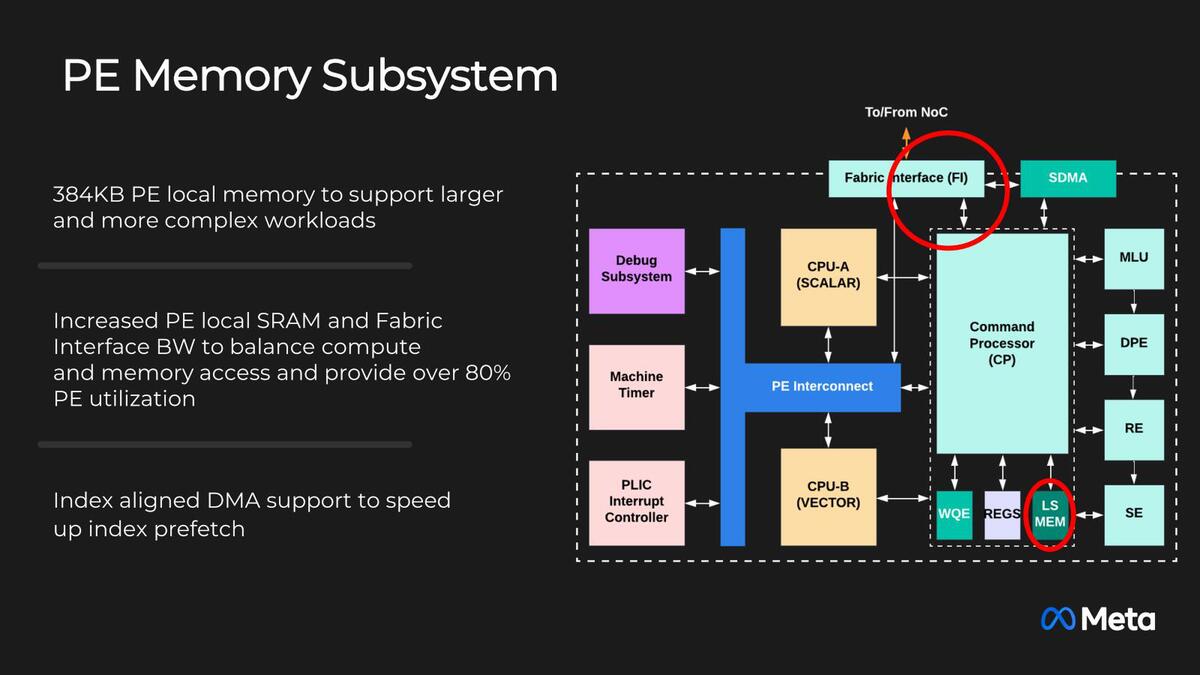
MTIA v1に比べて1サイクルで処理できる能力が2倍になったから、最低でもスクラッチパッドの容量を2倍にしないとつじつまが合わない。実際にはさらにモデルが複雑になっていることを考慮して3倍にしたのだろう
消費電力がチップあたり90Wまで上がると、さすがにデュアルM.2では収まりきらないようで、アクセラレーターカードはPCIeのフルハイト/フルレングスのものになった。ここに2つのMTIA v2チップを搭載する格好になる。220WではPCIe x16コネクターだけでは電源を供給しきれないので、補助電源コネクターは必須となっている。

なぜ片方のMTIA v2チップだけ90度回転させて搭載しているのかは不明。昨今のGPUを考えれば、1枚のボードに4つくらい載せられそうだが、Meta(というか、物理設計を請け負っているという噂のMarvell)にはそこまでの設計能力がなかったと思われる。無理して4つ載せてもHost I/Fに困るという話もあるので、妥当な設計だとは思う
当然ここまで大きいと、MTIA v1の時のようにYosemite V3のシャーシには入らない。説明では、2 CPUのシャーシに、片側6枚づつ合計12枚のMTIA v2のカードを装着。このシャーシをラックに3つ搭載する、としている。
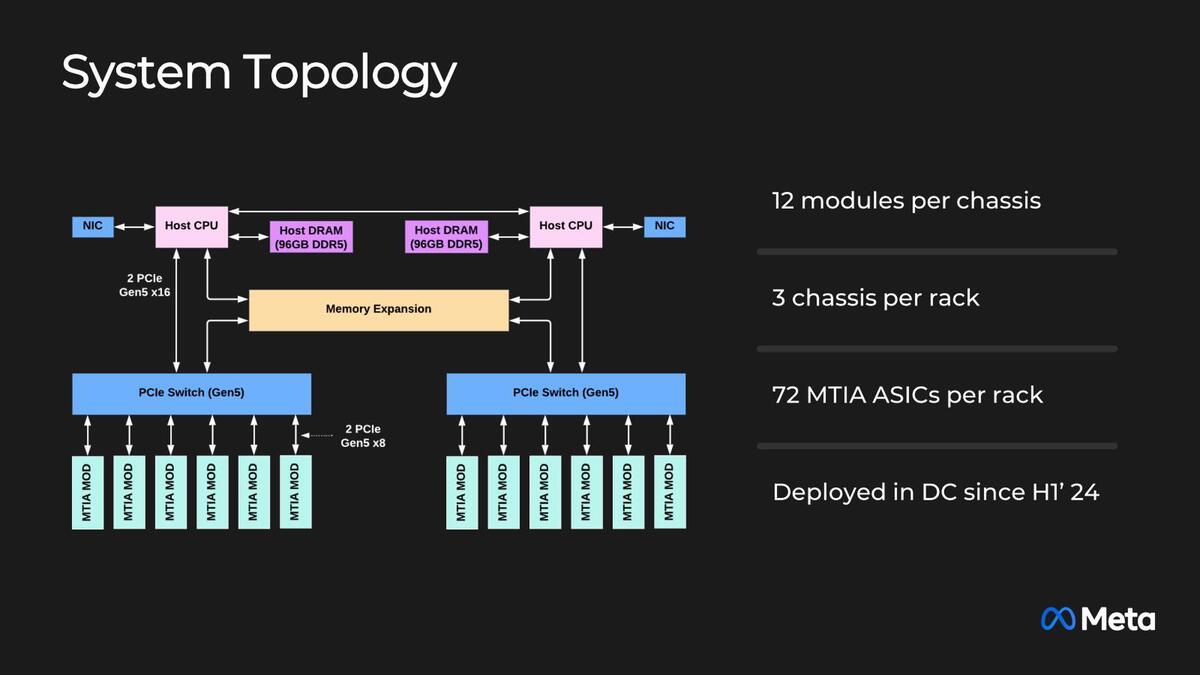
Host CPUがなにかは不明だが、例えばGen 4/5 EPYCならPCIe Gen5レーンを48本出すのは容易なので、間にPCIe Switchを挟む理由は不明である。単に配線が大変だから、というあたりが理由かもしれないし、あるいは直接MTIA v2カード同士で通信するケースもあってレイテンシーを下げたかったのかもしれない

この写真だけ見るとシャーシは6Uくらいの高さに見えるのだが、ラックあたり3つというのは実装密度ではなく消費電力やそのほかの問題が理由なのかもしれない
2024年前半からこのMTIA v2の展開をスタートしたそうだが、現状はまだMTIA v1とv2が混在している環境の模様だ。それもあって、まだソフトウェアの最適化をしている段階との話だが、7ヵ月目でやっとベースラインに達したレベルでまだ最適化は十分でないようで、性能のベンチマーク結果などは示されていない。
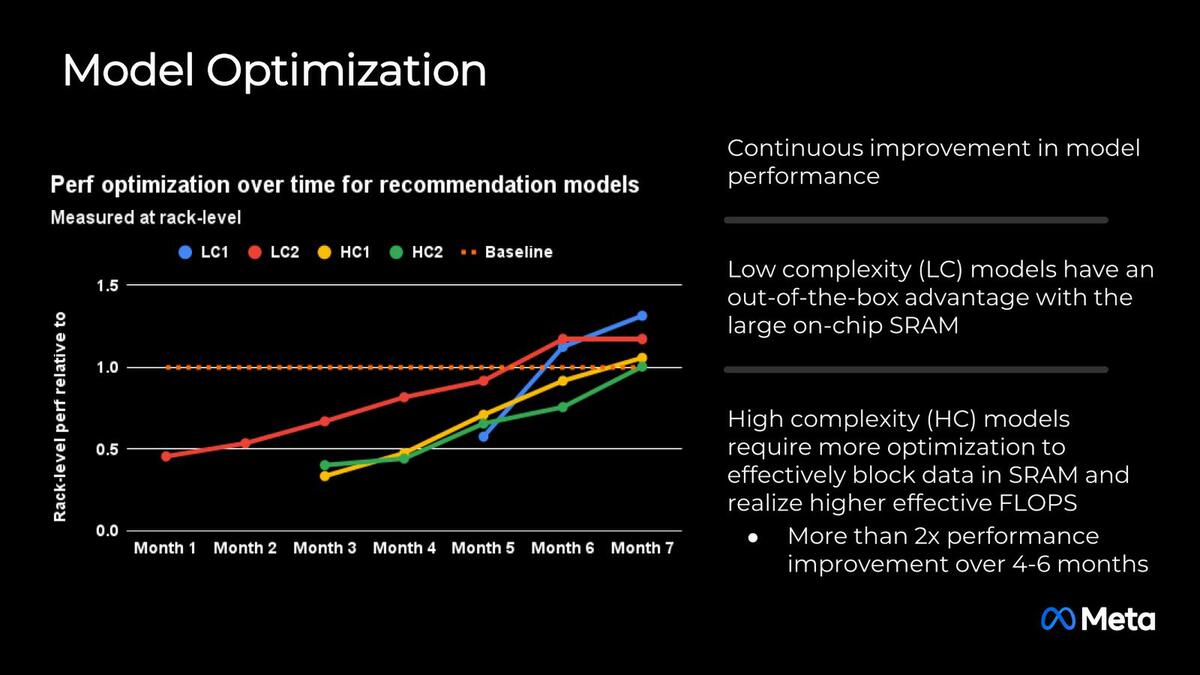
この結果が今年8月に講演されたことを考えると、2024年初頭にはもう展開がスタートし、そこから本格的に咲いて企画が進められたという格好だろうか
このあたりはもう少しして、最適化が一段落した段階でまたなにかしら示されることになるとは思う。価格あたりの性能や消費電力あたりの性能の改善、Metaのさまざまなサービスへの展開、それと開発の効率化を目指したのがMTIA v2であり、現在はその途中での経過報告といった感じの発表であった。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります