



第792回
大型言語モデルに全振りしたSambaNovaのAIプロセッサーSC40L Hot Chips 2024で注目を浴びたオモシロCPU
2024年10月07日 12時00分更新
SN40LはLLNに全振りしたAIプロセッサー
ところでSambaNovaではSN30とSN40Lの性能比を示していない。性能とはパラメーター数4050億個のLlama 3.1で114トークン/秒の処理性能が出せることが大きくアピールされており、競合との比較はViT(Vision Transformer)の結果が示されている、SN30との比較は一切ない。

SN40Lの性能。これはMetaが今年7月に発表したものである
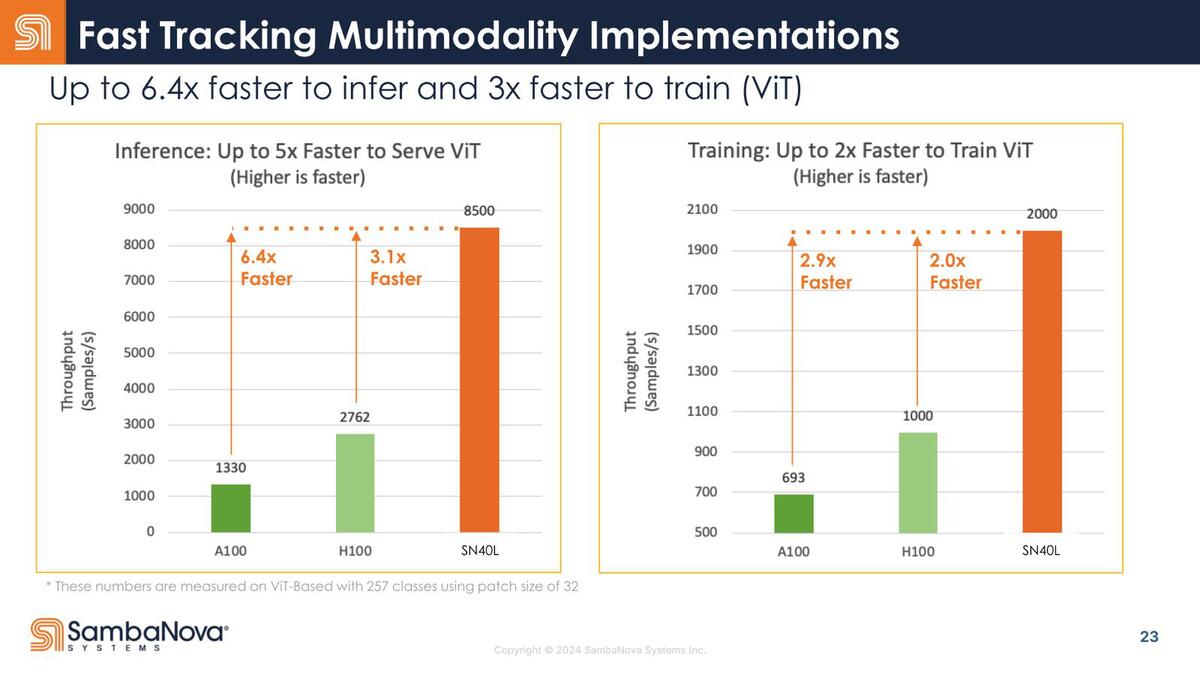
ViTとの性能比較。ViTはCNNなどを使わず、純粋にTransformerだけで処理されるもので、同じ条件でH100と比較して推論で3倍、学習で2倍高速とされる
これはある意味当然で、SN40は言わばSN30をさらにLLM向けに最適化したといった感じの構造になっているからだ。そもそもなぜLlama 3.1 405Bを大々的にアピールするかと言えば、現在リリースされているHBMベースのAIプロセッサーやGPUでは、メモリーに収まらずに扱いきれないほど巨大なモデルだからである。
ところがSN40の場合、HBMとは別に1.5TBのDDR5を用意できるので、こうした巨大なモデルであっても問題なく動作する。ピーク性能で言えばおそらくSN30の方が上で、小規模なモデルであれば多分性能差が付かないし、逆に性能差が付くようなモデルはそもそもSN30だと満足に動作しない可能性すらある。
こうした巨大モデルでは、処理性能そのものよりメモリー帯域の方がむしろ支配的であり、だから演算性能はやや落としつつ3 Tier(SRAM/HBM/DDR5)のメモリー構成を取ることでメモリー帯域を確保して効率を高める、というのがSN40Lの設計方針と考えられる。言ってみればLLNに全振りしたAIプロセッサーに生まれ変わった、というところだろうか。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります