



第789回
切り捨てられた部門が再始動して作り上げたAmpereOne Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月16日 12時00分更新
高密度/省電力な構成のAmpereOne
スケジューラーは192エントリーと、決して多くない。なんなら前回のOryonの方が倍以上ある。実行ユニットは全部で12とあるが、FPUが3つ、ロード/ストアーが4つなのでALUは5つ。実質的には1サイクルで4つのALU命令と、これに付随するロード/ストアー命令を1サイクルで2つ実行できる、という構成である。
FP/Vectorも同じで、3つと言いつつ1つはストアーデータだったりするので、実質2命令+2ロードといった形で、決して高性能ではない(この構成を見るとSVEのサポートはなくNeon止まりな気がする)。
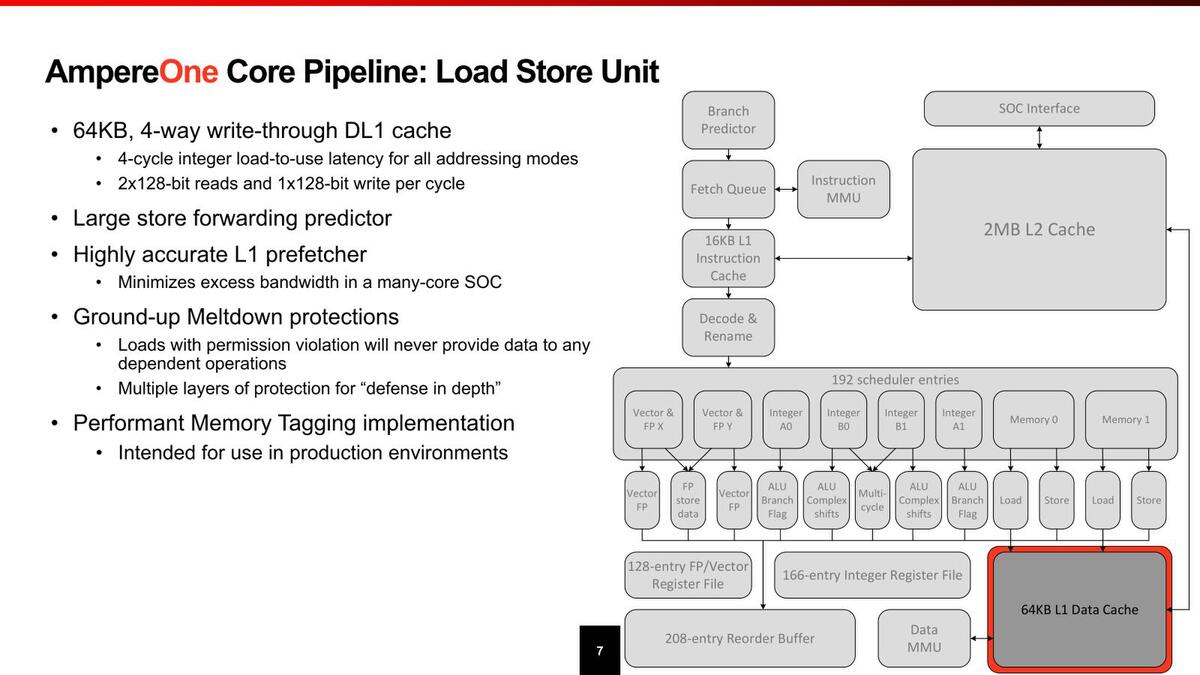
NEONユニット2つがフルに動いてもカバーできる帯域があることになる。それはともかくメルトダウン対策が当初からなされているというのもおもしろいが、これはArmのMemory Taggingを実装しているとのことだ
レジスターファイルはALUが168、Vectorが128で、これもそれほど多くない。ただALUは実質4+2命令(Vectorなら2+2命令)ということを考えるとこの程度で十分なのだろう。むしろこの規模でありながら、分岐予測を1サイクルに2つ実施できるのが目を惹く。この規模の他のプロセッサーは1サイクルあたり1つだったことを考えると、ピーク性能を高めるよりも実効性能を落とさないことに力点が置かれているように感じる。
ロード/ストアーユニットは当然L1 Dキャッシュと密接に関係しているわけだが、Load-to-useは4サイクルと結構高速だし、store forward predictor(書き出したデータをプログラムの中で再び使うという処理で、メモリーまで書き出し終わるのを待って読み直すのは遅くなりすぎる、書き出しを掛けてもその値を保持していたレジスタファイルを破棄せずに再利用できるようにする仕組みだが、それを事前予測することで効率的にStore forwardを実行できるようにする)というメカニズムは初めて目にした。
TLBはそれなりに重厚ではあるが、これはサーバー向けということを考えればそれほど不思議ではないし、極端に多いわけでもない。
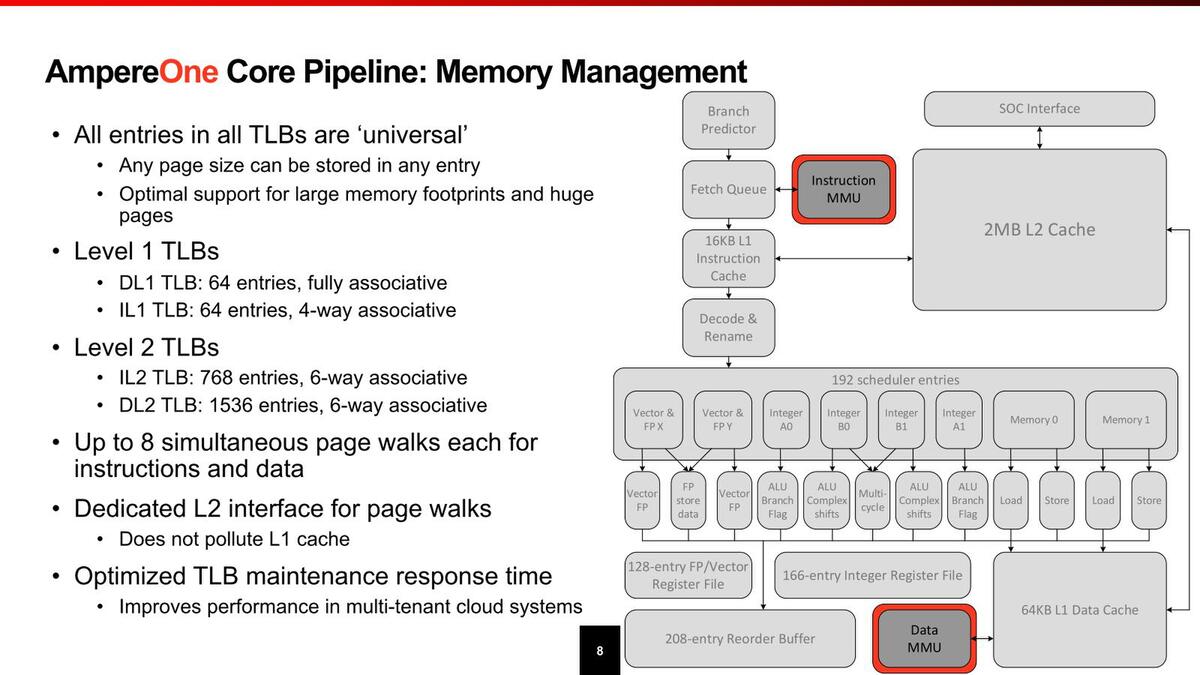
メモリー管理。これだけのPage Walkを可能にするとなると消費電力にインパクトがありそうだが、それもあってTLBのサイズは控えめなのかもしれない
おもしろいのは、TLBが任意のページサイズをサポートできる(インテルのx86では、4KB/2MB/1GBで利用できるエントリー数が違う)あたりだろうか。あと同時に8つのPage Walkを同時に発行できたり、1次キャッシュと2次キャッシュを別々にPage Walkできたりするあたりは珍しい。このあたりも、Page Walkで余分なレイテンシーが増えることを極力避けるためと思われる。
2次キャッシュはコアごとにプライベートである。消費電力増加を避けるためか、Load-to-Useは11サイクルと大きめだが、これは2次キャッシュの速度としては妥当だろう。
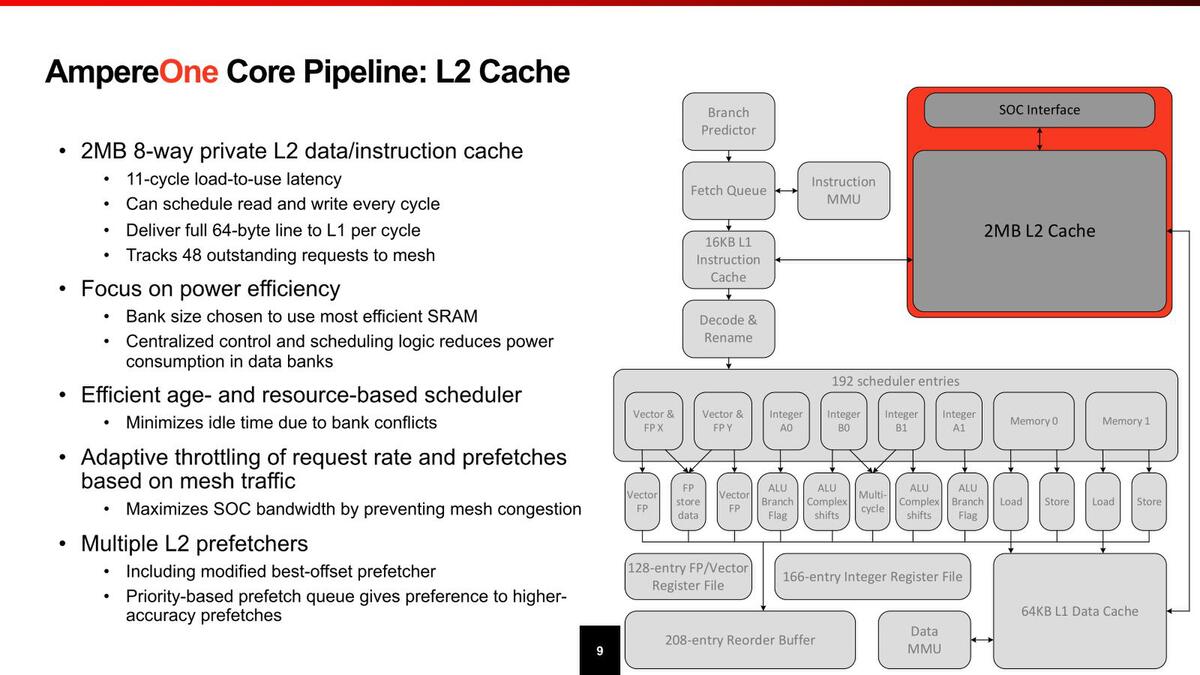
2次キャッシュは、構成も省電力最優先とあるので、おそらく高密度/省電力の構成になっているものと思われる。そのわりにレイテンシーが常識的なのは驚きである
1次キャッシュとの帯域は64Bytes/サイクルで、このあたりは最近のプロセッサーらしい速度。3次キャッシュとの関係は不明だが、後述するように3次キャッシュは全部で64MBしかなく、しかもスヌープフィルターも兼ねていることを考えるとインクルーシブ・キャッシュ構成というのは考えられず、エクスクルーシブ・キャッシュ構成と思われる。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります