




バーチャル〇〇ではなく、〇〇の「Role」を演じさせる
ChatGPTは、世の中の森羅万象を教えてくれそうな大規模言語モデル(LLM)。何でも分かっているように見えるが、答える内容は、あくまでGPT-3.5やGPT-4といった言語モデルが学習した内容に限られる。
そこで、ChatGPTみたいに人間なみの対話ができるんだけど、中身の知識はオリジナルなチャットBOTを作ることを考える。商品のサポートや企業の窓口として、いままでの《いかにも決まりきった反応しかしないBOT》ではない、新世代のチャットBOTができそうではないか?
これを実現する方法として、ChatGPTを提供するOpenAIが、その言語モデルに追加学習する「ファインチューニング」という手段を提供している。しかし、それよりも話題なのが「llamaindex」(ラマインデックスと読む)というライブラリを使って、ほぼ同じような効果をめざそうというアプローチである。
私がはまったのは、napakaさんの《LlamaIndex クイックスタートガイド - v0.6.0》という記事がきっかけだった。「専門知識を必要とする質問応答チャットボットを簡単に作成できる」「コード数行で完成してお手軽なのが特徴」とある(正確には1つ前のv0.5.12のときの記事)。
《お手軽》と聞いたら、黙ってみているわけにはいかない。さっそく、やってみたいと思ったのが、北大路魯山人の「お茶漬け」に関する文章をGPTに追加することだった。『魯山人味道』という本に何度も茶漬けが出てきたのを覚えていて、《青空文庫》のタイトル一覧を見ると、お茶漬けについて10本ほどの文章が見つかった。そこで、これをダウンロードして使わせてもらうことにした(「青空文庫収録ファイルの取り扱い規準」にもとづいて行ったつもりだがお気づきの点がある方はお知らせいただきたい)。
以下が、それを使ってlllamaindexでBOTのように動かしてみた結果である。
あなた:お茶漬けについて教えてください
>>>お茶漬けについて教えるなら、まずは車えびを使うことをお勧めします。車えびは東京の一流てんぷら屋の自慢で、横浜本牧あたりで獲れるものが本場と言われています。車えびを生醤油と酒で煮た佃煮を熱飯の上に載せ、充分な熱さの茶を徐々にかけると、醤油が溶けてえびが白くなり、だしが溶けて茶碗の中の茶がスープとなり、美味しいお茶漬けができあがります。
あなた:ほかにはどんな茶漬けがありますか?
>>>他には、塩昆布の茶漬けがあります。これは、昆布を煮る醤油がよくなくては駄目なので、売りものの仕入れ品などは適当でないという点で、安物の実用茶漬けとは異なります。京都の松島屋、東京の築地魚河岸の特産店、日本橋室町の山城屋などが取り扱っている上等な昆布を使用します。
あなた:茶漬けに醤油は大切なのですね
>>>はい、醤油はてんぷらの茶漬けにとても大切です。醤油は、てんぷらを火にかける際にも使用しますし、茶漬けにかける時にも、生醤油か塩をかける必要があります。また、車えびの茶漬けには、醤油と酒を三割ばかり割った汁を使用します。醤油は、茶漬けを美味しくするために欠かせません。
あなた:茶漬けは蓋をしてしばらく置く食べ方もありますね
>>>はい、蓋をしてしばらく置く食べ方もあります。蓋をして放置することで、味が濃くなります。また、蓋をしない食べ方もありますが、香気が高く、熱く、まぐろが熱し過ぎないので、美味しいです。
あなた:いちばん好きな茶漬けは何ですか?
>>>私は魯山人であり、私の最も好きな茶漬けは、はも、穴子、鰻の茶漬けです。これは、三州から瀬戸内海にかけて獲れるはもを使用して作られるもので、関西人にとっては代表的な美食となっています。はもは煮ても焼いても蒲鉾に摺り潰しても、間違いのないよいさかなであり、特に焼いて食べるのが一番美味いと言われています。熱飯の上に載せ、箸で圧し潰し、飯になじませ、適宜に醤油をかけ、玉露か煎茶を充分にかけ、ちょっと蓋をすると、一分間ばかり蒸らし、箸で肉をくずしつつ食べることができます。
あなた:納豆はどうですか?
>>>納豆はとても美味しいと思います。納豆の拵え方を正しく行うことが重要ですが、そうすると、納豆の味がより強くなり、美味しくなります。また、塩昆布の茶漬けも美味しいですが、上等な昆布を使うことが重要です。
あなた:茶漬けといえば、私などは、海苔の茶漬けなのですが
>>>私も海苔の茶漬けが好きです。しかし、塩昆布の茶漬けも美味しいです。上等な昆布を使って、醤油をよく混ぜて煮ることで、とても美味しい茶漬けが作れます。
あなた:塩昆布の茶漬けがお好きなようですね。
>>>はい、塩昆布の茶漬けがお好きです。京都の松島屋や東京の築地魚河岸の特産店、日本橋室町の山城屋などから上等な昆布を仕入れて、自分で茶漬けを作るのが好きです。また、塩鮭・塩鱒の茶漬けもお好きですが、さけよりますの方がはるかに美味しいと思います。
あなた:鮪はどうですか?
>>>鮪は美味しいです。三州から瀬戸内海にかけて獲れるため、関西地方では特に人気があります。刺身で食べるのが一番美味しいと思いますが、熱飯の上に載せ、箸で圧し潰して食べる茶漬けも美味しいです。
あなた:焼きのりも美味しいですよね。
>>>はい、焼きのりは美味しいですね。特に、関西地方では、はもの焼きのりが有名です。はもは、三州から瀬戸内海にかけて獲れるので、今も京阪地方の名物のようになっています。焼きたてならばそれに越したことはないほど美味しいですが、焼き冷ましのものは、改めて遠火で焙って食べるのがおすすめです。
あなた:いまどんな食べ物についてお話をうかがってましたかね?
>>>私たちは、まぐろ、ごりの茶漬け、そして京都にある「鷺知らず」という美味しい小ざかなについて話していました。
あなた:茶漬けのはじまりは、いつ頃、どのようにして、あるいはどこから来たというようなことは分かってるのですか?
>>>茶漬けのはじまりについては、正確な時期や場所は分かりません。しかし、茶漬けは古くから日本で食べられている伝統的な料理であることは確かです。茶漬けは、江戸時代には「佃煮」として食べられていました。佃煮は、醤油や酒などを使って煮込んだ料理で、その中に入っている食材によって様々な種類があります。茶漬けも、その一種であると考えられています。
よく見るとおかしなところはあるが、たしかに内容は読み込ませた10本の文章の中から答えているようすが伝わってくる。あとで示すコードを見ると分かるのだが、プロンプトで「魯山人として答えてください。」といわゆる「Role」を与えていて、原稿の先頭には「てんぷらの茶漬け/北大路魯山人」などと付けてある。
「茶漬けといえば、私などは、海苔の茶漬けなのですが」という私の問に対して、「私も海苔の茶漬けが好きです」と返してくるあたりは、いかにもGPTらしい調子のよさ(本当だろうか?)。そのあとの「しかし、塩昆布の茶漬けも美味しいです」という切り替えしは、彼の頭の中でどんなニューロンが発火したのかと思う(GPTではこうした飛躍をアテンションと呼んでいる)。
最後のほうでは、ちょっとイジワルな質問を連続して投げかけてみた。「お茶漬け」という言葉を含まない「鮪はどうですか?」と「焼きのりも美味しいですよね。」という問いかけをしてみたのだ。今回のコードでは、単純に質問に対してそれにふさわしい返答はしてくれるが、いま「お茶漬け」について話をしているといった会話の流れを意識するようにはなっていないからだ。
その結果、「鮪」(まぐろ)は、そもそも与えた文章に茶漬けのことしかでてこないので、偶然にも自然な返答になった。ところが、焼きのりに関しては「お茶漬け」とは関係のないように見える返答になっている。
さらには、「いまどんな食べ物についてお話をうかがってましたかね?」というボケ老人のような問いかけに対して、かなり突飛なこれまたボケ老人のような返答となってしまった。
「茶漬けのはじまり」についての問いかけに対する返答は、今回のようなチャットBOTでは注意すべき点である。これは、私が llamaindex にあたえた10本の魯山人の文章から出てきた答えではないのだ。しかも、「江戸時代には「佃煮」として食べられていました。」とは、なんともあやしい内容ではないか?
「魯山人として答えてください。」と役を与えて演じてもらっているはずが、このままでは企業のサポート用のBOTなどでは使えないという意見もあるだろう(与えた情報以外に何をしゃべりだすか分からないですからね)。
llamaindexは、エンベディングという概念を利用したライブラリである。エンベディングとは、文章や単語を意味的な距離をベクトルで表現する。魯山人のお茶漬けについての文章をエンベディングしておいて、問い合わせの内容に近い部分を探し出して、GPTに対してプロンプトに追加して渡している。
これによって、「海苔の茶漬けについて教えて?」ときたときに、海苔の茶漬けについて書かれた文章を切り出してきて、これを参考に答えよとやっていると考えられる。ある種のプロンプトエンジニアリング的なハックといってよいだろう。
また、このようなアプローチのことを、魯山人のお茶漬けについての文章を《GPTに接続》するといった言い方もされている(今回の記事のタイトルは「ChatGPTに接続して」と書いたが、正確には「OpenAIの言語モデルに接続して」という表現が正しい)。
元のGPTから出てきた答えなのか? 接続してやった魯山人の文章から出てきた答えなのか? 目的によって、これを見極める工夫が必要な場合があるかもしれない(用意するデータの工夫か? 出てきた答えの評価か?)。
以下に、今回使用したコードを紹介しておく(前述のnpakaさんのサンプルコードほぼままな内容)。青空文庫からはテキストファイルの形式でダウンロードして、ルビや傍点、底本データなどを取り除いたものを使用した。“|([^《]*)《[^《]*》”を“\1”に、“《[^《]*》”を消去、“[#[^[]*]”を消去。data というフォルダにUTF-8のコーデックで入れてある。また、動作させるにあたってはOpenAIのAPIキーを取得して、環境変数「OPENAI_API_KEY」に設定しておく必要がある。
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
index = GPTVectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
while True:
inp = input("あなた: ")
print(">>> " + str(query_engine.query("魯山人として答えてください。"+inp)))
print()
これを動かすには、Pythonの動作環境が必要。llama-index==0.6.8 をpip インストールして動かしている。おそらく、ちょっとプログラミングの経験のある人なら1、2時間で同じものが動かせているはずだ。本当に簡単! なお、ここでは1本のプログラムの中でインデックスの作成と問い合わせの両方をやっているが、インデックスを保存しておけば、毎回作成する必要はない。
ちなみに、これのレスポンスタイムだが、お世辞にも軽やかとはいえない。とくに、私のノートPCではそうなのだが、AzureやAWSで、きちんとリソースを確保して動作させないと実用的ではない可能性があることを付け加えておく。
ちなみに、今回使った魯山人がお茶漬けについて述べている10本の文章とは次のものである(前述のとおりタイトルに茶漬けとある文章)。
「お茶漬けの味」、「京都のごりの茶漬け」、「車蝦の茶漬け」、「塩昆布の茶漬け」、「塩鮭・塩鱒の茶漬け」、「てんぷらの茶漬け」、「納豆の茶漬け」、「海苔の茶漬け」、「鱧・穴子・鰻の茶漬け」、「鮪の茶漬け」
私が、魯山人の文章をデータに使わせてもらおうと思ったのは、昨年11月末にはじめてChatGPTを使ったとき。なんとなく「ChatGPTって魯山人みたいな文体だな」と思ったからだからだ。
世の中の1つ1つには決まりごとがあって、あるいは適切なやり方があって、我々もそのようにふるまうべきであるとキッパリ言ってくる気持ちよさ。それがリアルタイムの会話になったらさぞかし面白いだろうと想像していたからだ。
もっとも、「魯山人として答えてください。」とプロンプトに与えたとしても、それは、あくまで「魯山人を演じてください」と言っているだけであるのは、ご存じのとおり(英語では「Act as xxxx」と表現する)。「あなたは魯山人ですか?」と聞くと「いいえ、私は魯山人ではありません」とちゃんと返ってくる。魯山人を《語る》ようなものでもないし、「バーチャル魯山人」を作ろうなどと大それた話でもない。
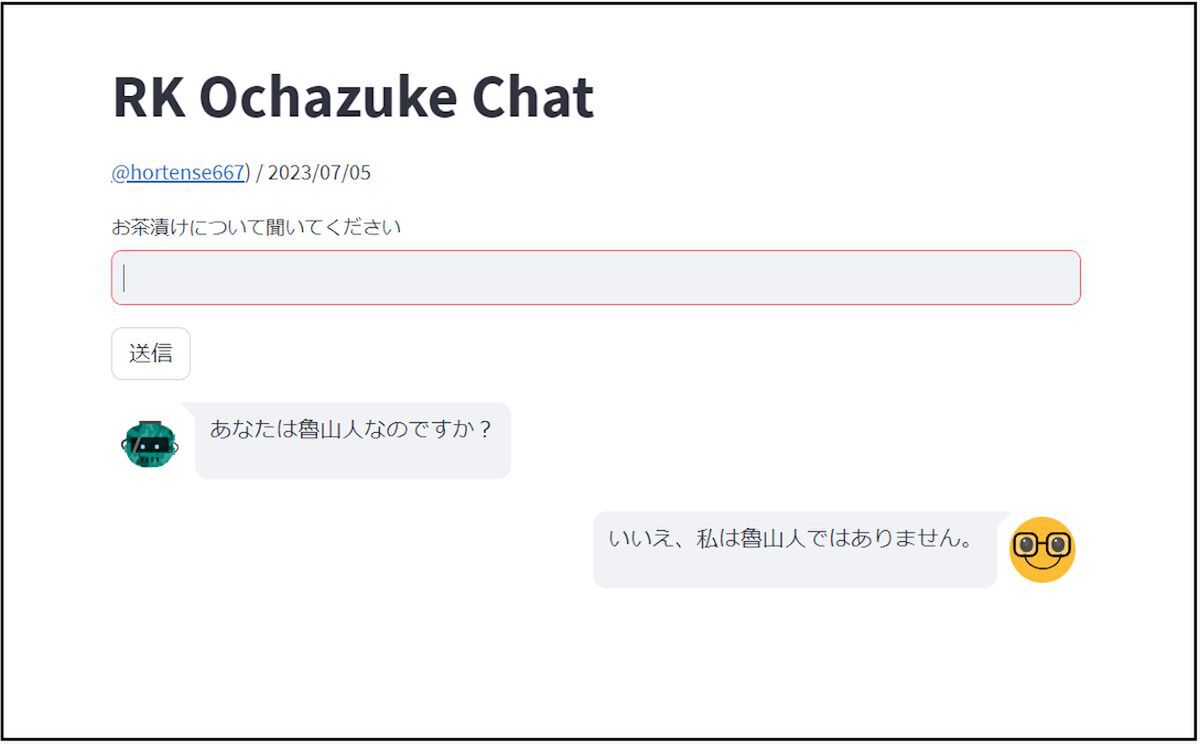
それでも、このようなチャットBOTに魯山人の文章を使わせてもらうのは、人工知能の典型的な間違った使い方だなどと言う人もいるかもしれない。実際、いかにもな文体が出てくるのは楽しいのだが、中身を見ていくとおかしいことがかなりある。魯山人の文章には出てこない「鰹節の茶漬け」という言葉を無限ループ状に繰り替えす完全にエラーな状態になることさえある。
ということで、青空文庫にある魯山人の全作品をすべて llamaindex に入れ込んでみたいとも思ったが、ひとまずこのあたりとすることにした。
ところで、チャットBOTの話から離れるが、お茶漬けといえば、私が、よく食べに行くのが銀座なかね 湯島店の鮪の茶漬けである。
そのむかし、キヤノンの大分工場見学に行ったときにご馳走になった《鯛茶漬け》が忘れられず、その後も東京で探し続けていた。ところが、鯛茶漬けは、いまだ決まったお店を見つけられずにいたのだ。そのことを魯山人GPTに聞いてみたら、「たいは関西がよく、まぐろは東京がいい。東京は、たい茶漬けよりまぐろの茶漬けを用いてしかるべきであろう」とのことで、得心。
30年前の自分の原稿と対話する「endoGPT」はできるのか?
さて、魯山人のほかにもGPTに接続してみたい作家は何人もいるのだが、いちばん自由に使っていい原稿は、自分のハードディスクの中にたまっている過去の自分の原稿である。
なんだか自家中毒的な気持ちのわるい奴だといわれそうなことだが、30年前の原稿をGPTに接続できたら、30年前の自分と時間を超えた鏡のような対話ができるんじゃないか? よくドラマで「30年前の自分に会ったら〇〇〇と言ってやりたい」などというセリフがあるが、それと似た体験が出来そうである。
さらにいえば、今回の魯山人GPTの場合には、いまどんなテーマで会話をしているかというコンテクストがないことは述べた。やっぱり、自分と過去の自分が会話するというのなら、ちゃんと会話として成り立っているようにしたいと思う。
実は、調べてみると、目下、この「llamaindexを使ったチャットBOTでちゃんと会話として成り立たせる」ことを、世界中であれこれ工夫しまくっている真っ最中のようだ。業務向けの《内容重視のBOT》なら魯山人のときのプログラムで、十分に実用に耐えるものに仕上げることができそうだという感触はある。しかし、《会話を楽しみたいBOT》では、まるで話が変わってくるようなのだ。
結果的に、私は、LangChainのチャットモデルというものを使って、自分の過去原稿と会話する「endoGPT」というものを動かしている。次回はこのendoGPTのコードとその限界、それに対する対策(チャンク=llamaindexに与える意味のまとまった文章のかたまりの最適化)などについて触れる予定だ。新しい分野ゆえ、今回の原稿でも私の誤解かあるかもしれない。その場合はお手数でもお知らせいただきたい。
魯山人のお茶漬けについてのチャットBOTを簡易的に体験できるWebアプリを用意してみた。OpenAIのAPIキーを取得する予定のない人やPythonの実行環境を用意したくない人もいると思うからだ。ただし、サービスとしてきちんと立ち上げたものではなく、一定のサービス時間にしか動かしていない(くわしくはページ自体をご覧のこと=この分野は動きが速いのでずっと動かしておく必要もないと思われる)。運よく動いていたら是非試していただきたい。
RK Ochazuke Chat:https://rk-ochazuke-chat.streamlit.app/
トップ画像などの顔アイコン入りの画面がこのWebアプリだが、チャット形式の表示については、ドドテクノ「StreamlitとOpenAIで作る! “Hello World”からのチャットボット開発」を参考にさせていただいた。この記事も、チャットBOTの開発についてのべている。
遠藤諭(えんどうさとし)

株式会社角川アスキー総合研究所 主席研究員。MITテクノロジーレビュー日本版 アドバイザー。プログラマを経て1985年に株式会社アスキー入社。月刊アスキー編集長、株式会社アスキー取締役などを経て、2013年より現職。人工知能は、アスキー入社前の1980年代中盤、COBOLのバグを見つけるエキスパートシステム開発に関わりそうになったが、Prologの研修を終えたところで別プロジェクトに異動。「AMSCLS」(LHAで全面的に使われている)や「親指ぴゅん」(親指シフトキーボードエミュレーター)などフリーソフトウェアの作者でもある。趣味は、カレーと錯視と文具作り。2018、2019年に日本基礎心理学会の「錯視・錯聴コンテスト」で2年連続入賞。その錯視を利用したアニメーションフローティングペンを作っている。著書に、『計算機屋かく戦えり』(アスキー)、『頭のいい人が変えた10の世界 NHK ITホワイトボックス』(共著、講談社)など。
Twitter:@hortense667週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります