



OpenAI「GPT-4」リリース 画像からの入力にも対応
2023年03月15日 14時30分更新

OpenAIは3月14日(現地時間)、「ChatGPT」を支える大規模言語モデル「GPT-3.5」の後継となる「GPT-4」を発表した。
GPT-4は、過去のモデルよりも問題解決能力が大幅に向上し、扱えるテキストの量も増加。画像からの入力(出力はテキストのみ)にも対応するマルチモーダルモデルに進化している。
有料版「ChatGPT Plus(月額20ドル)」に登録することですぐにGPT-4を試す(回数制限あり)ことができるほか、APIのウェイティングリストも開設されている。
すべての性能でGPT-3.5を凌駕
GPT-4は過去のモデルと比べ、より幅広い一般常識と問題解決能力により、難しい問題をより正確に解決することができるという。
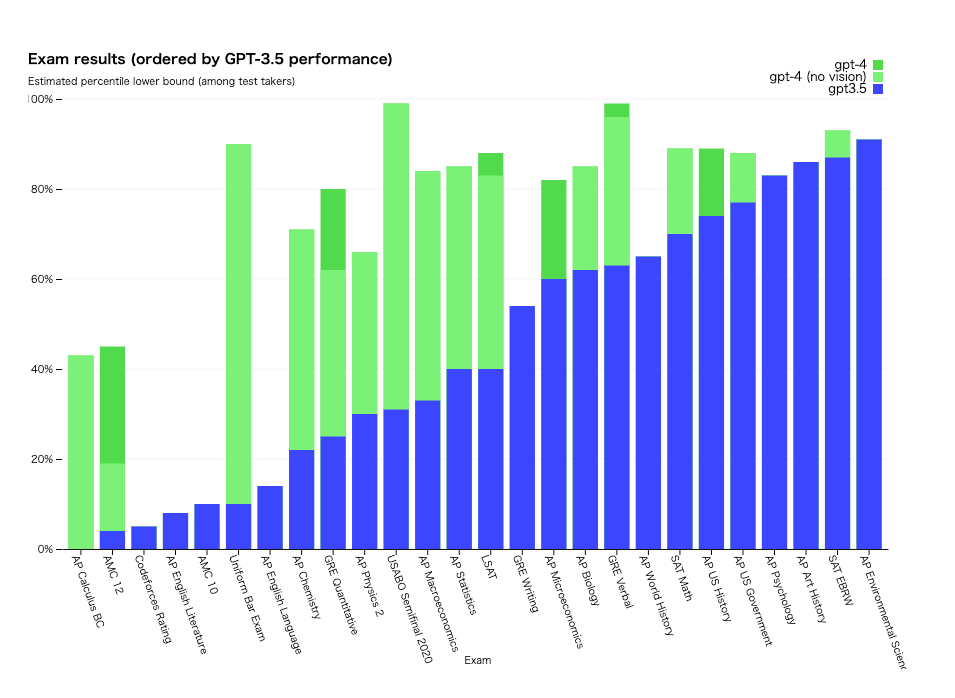
各種試験の結果(緑がGPT-4)
例えば、これまでのGPT-3.5では受験者の下位10%程度の点数しか取れなかった司法試験の模擬試験で上位10%に入るスコアを、また、高校生を主な対象とした生物学の問題を解く能力を競う「国際生物学オリンピック」の問題では上位1%のスコアを記録した。
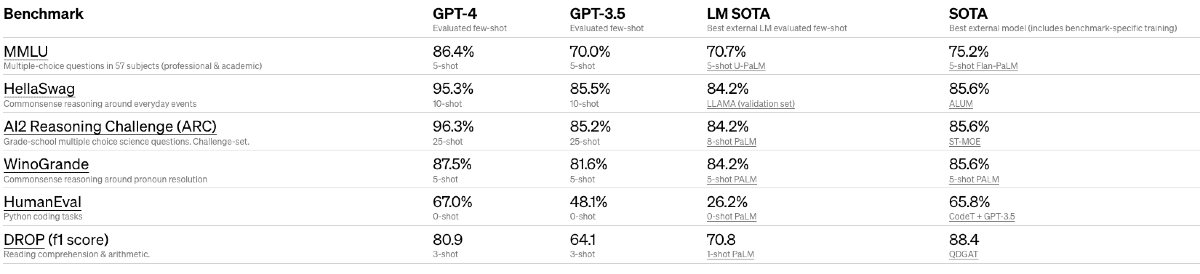
各種ベンチマークの結果
また、機械学習モデル用に設計された従来のベンチマークでもほとんどの最先端(SOTA)モデルを大幅に上回っている。
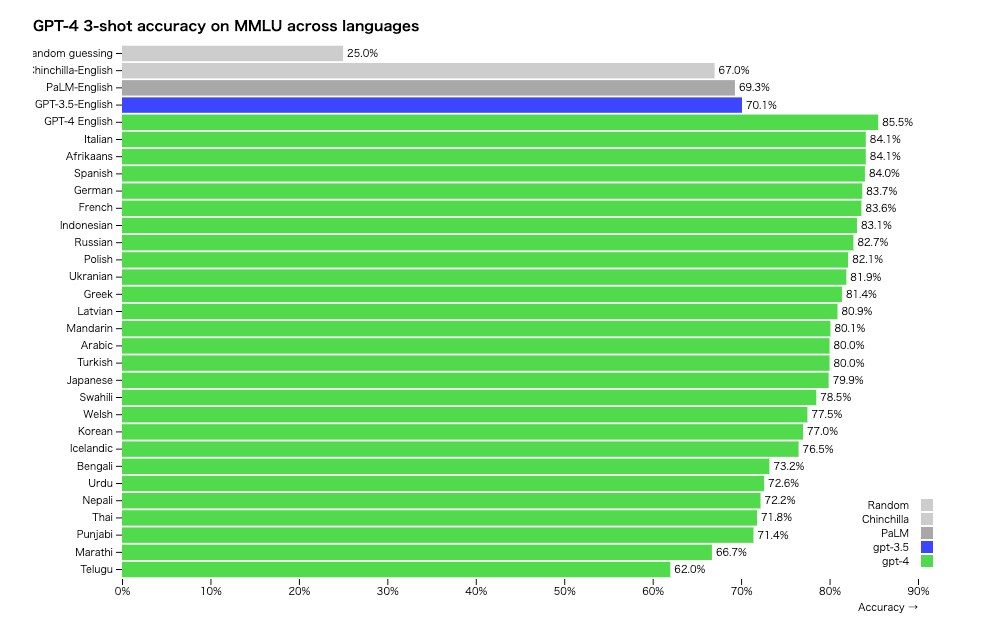
言語別の正確さテスト
GPT-4は英語以外の性能も向上している。57のテーマにまたがる1万4000の問題を解かせるMMLUベンチマークを使ってテストすると、26言語中24言語(ラトビア語、スワヒリ語などリソースの少ない言語を含む)においてGPT-4はGPT-3.5や他の大規模言語モデル(Chinchilla、PaLM)の英語での性能を上回っている。
画像をプロンプトとして入力することも可能
GPT-4は、テキストによるプロンプトだけではなく、画像を利用してその画像の説明や分類・分析をすることも可能になっている。

画像によるプロンプト
たとえば、上記の写真に加えて「この写真のどこがおもしろいか写真ごとに説明して」というテキストを入力すると、1枚ごとの状況を説明した上で「この画像のユーモアは、大きくて時代遅れのVGAコネクタを、小さくてモダンなスマートフォンの充電ポートに差し込むという不条理から生まれています」と解説してくれるのだ。
ただし、画像入力機能は現在のところ非公開であり、パートナー(恐らくマイクロソフト)と連携し、広く提供できるように準備中とのことだ。
扱える文字数も増加
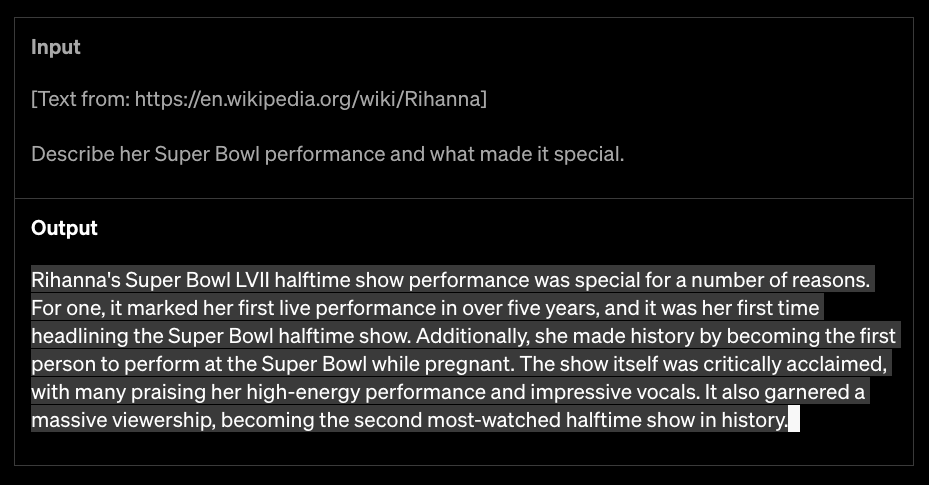
WikipediaのURLをプロンプトとして使用している
GPT-4は2万5000語以上のテキストを扱うことができるので、より長文のコンテンツ作成や文書の検索・要約・分析などが可能になった。
例えば1万語を超えるWikipediaの1項目全文を入力し、それを要約・分析することもできるのだ。
GPT-4はまだ完全ではない
大幅にパワーアップしたGPT-4だが、従来のGPTモデル同様の限界があることをOpenAIも認めており、完全に信用することのないよう注意を促している。
OpenAIは、GPT-4をより安全かつ整合性のあるものにするためのフィードバックによるトレーニングに6ヵ月を費やした結果、GPT-3.5と比較し、不適切なコンテンツを表示してしまう確率が82%低く、事実に基づいた回答を出す確率が40%高くなったという。
とはいえ、まだまだ完全ではない。これまでのモデルと同様、多くの人に使ってもらいながら定期的にアップデートしていく予定だ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります