



不十分な日本のデータ活用に一石を投じるデータビークル
最強の統計学をビジネスに活かせる、専門スキル不要のデータ分析ツール
医療現場や流通・小売業、そのほかさまざまな業種で、データの活用が改めて注目を浴びている。現場の勘に頼った経営が限界を迎え、経営戦略が売れなくなった時代。あらゆるデータを読み取ることで、課題の解決、最適化、未来予測へとつなげるデータ分析は、市場の動向を把握する上で、今後ますます不可欠な手段となっていくだろう。
しかし、データ分析は統計学やプログラミング技術などの専門スキルを要求されるため、参入障壁が高く、コンサルティング料も高額となるため、日本企業ではなかなか導入が進まない現状がある。そうした状況に一石を投じるのが、データ分析ツール「Data Diver(データダイバー)」を提供する株式会社データビークルだ。
データサイエンスに基づいた設計で、専門的な知識や経験を必要とすることなく利用できる同社のソリューションは、データ分析という点で非常にユニークなアプローチを行っている。株式会社データビークル代表取締役CEOの油野達也氏と、同社代表取締役であり「統計学が最強の学問である」の著者でもある西内啓氏に話をうかがった。

株式会社データビークルの西内啓代表取締役(左)と油野達也代表取締役CEO(右)
データサイエンティストの英知が結集されたデータ分析ツール

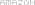
株式会社データビークルが提供するのは、統計学やプログラミングなどの専門スキルや経験が不要なデータ分析ツールだ。これらのプロダクトが生まれた背景には、学生時代から10年間以上データ分析に携わってきた西内氏の経験と知見がある。
大学で教鞭を執ったあと、データ分析のコンサルティングを手がけてきた西内氏は、そこでたまったノウハウを書籍「統計学が最強の学問である」にしたためた。本書がたちまちベストセラーになると、西内氏のもとにはコンサルティングの依頼が殺到。だが、属人的な個別企業への対応だけでは、真に訴えたかったデータ分析の活用法が企業・個人単位で浸透することはなかった。
そんな現状に対して、生産性の向上と効率化を図る必要性を感じた西内氏は、それまでに書いてきたデータ分析プログラムをライブラリー化することにした。これが、データサイエンスを駆使した分析ツールの原型の誕生だ。
データ分析ツール「データダイバー」
西内氏によれば、データサイエンティストは、大きく次の3つのステップでデータ分析を行なうという。1つ目は、業務のために蓄積されたデータを分析用に「加工」するというステップ。2つ目が、加工されたデータの「分析」をするフェーズ。3つ目が、分析結果が意味するところを考える「解釈」だ。
そもそもデータの加工には、手間と時間がかかる。どのように加工したらよいか、分析者が最初から正解を持っているわけではない。結果、関係者にヒアリングし、そこから得た仮説に合わせて都度データ加工をしていくことになる。企業が発注してせっかく分析したレポートも、「仮説が裏付けられた」というだけでは「当たり前の結果」で終わってしまうことが多い。せっかく膨大な時間とお金を費やしたのに、「やっぱりね」で終わってしまうと、データ分析をした意味はない。
一方、西内氏はまずありとあらゆるパターンでデータを加工したうえで、クライアントが関心のある変数に対して、何のデータがどれくらい効いているか、最適な変数の組み合わせを探し出す。このようなやり方によって、分析結果から意外な気づきが得られるのだという。
専門スキル不要のデータ分析ツール
「データダイバー」「データフェリー」
とはいえ、これまでデータを扱った経験もなければコードを書いたこともない人間にとって、データ分析はハードルが高いのではないか。そうした不安も、データビークルのツールはいとも簡単に拭い去る。
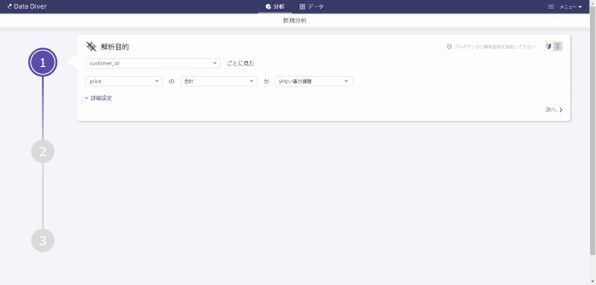
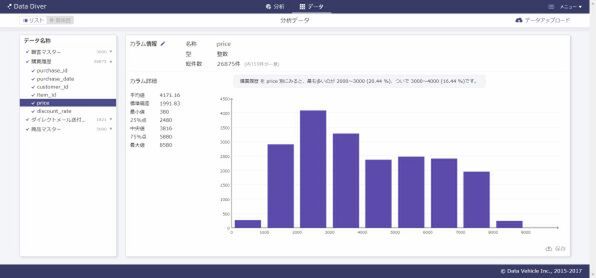
たとえば、データダイバーを使って効果的な販売方法を知りたいときには、「顧客マスタ」「ダイレクトメール(DM)送付履歴」「購買履歴」「商品マスタ」の4つのファイルをアップロードする。次に、解析目的画面で、「単価の高い優良顧客とそうでない顧客の違いを知りたい」「ヒット商品とそうでない商品の違いを知りたい」といった分析の目的が指定できる。
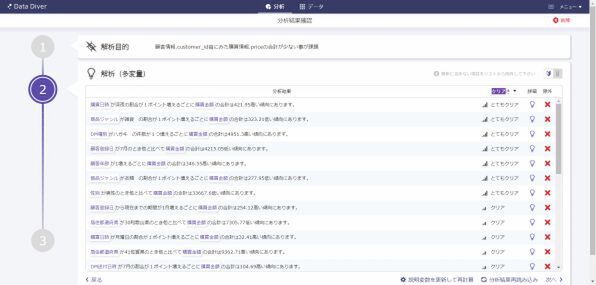
すると、クラウド上でデータの加工がはじまり、たとえば購入日やDM送付日を曜日別・月別・年別、月の上旬・下旬などの形で集計しなおしたり、DMや購入された商品などの種類といったさまざまな組み合わせから、一時的に数百列ものデータを作り出す。その中で最適な組み合わせパターンを、自動的に最大30個提示してくれる。このパターンこそが、西内氏が最も重視する変数の設定というわけだ。
このツールを使うと、データ分析をやったことのある人ほど驚きが大きいという。それだけ、手間のかかる作業を簡単な操作であっという間に完結できる。背景には、これまでのコンサルティングや実際の取り組みで培ってきた西内氏の分析メソッドがそのまま「データダイバー」に移植できた点が大きい。
もちろん、統計学やプログラミングの知識は一切不要。既存のデータの特徴検出がアルゴリズムに落とし込まれているため、データサイエンスをベースにした質問にそってマウスを操作するだけで、解へと導かれていく仕組みができあがっている。
だが、ビジネスに成果を出すためのデータ分析には、整理された”きれいなデータ”も求められる。データダイバーの前段としてデータを整備する必要があれば、データ整備ツール「Data Ferry(データフェリー)」を用いればよい。
こちらはPython、R言語、SQLといったプログラミング言語の知識不要で使えるデータ整形のためのソリューションとなる。データ収集と変換が、ブラウザー上で3ステップで完結する。別々のシステムから取り出したデータを、マウスでクリック&ドラッグしてつなげるだけで、同じファイル上で扱うことができる。通常はSQLを用いてしなければならない手間のかかる作業が、瞬く間に完了する。
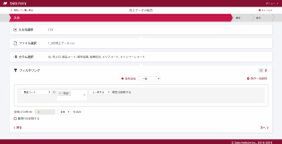
データフェリーでのUI
このようなデータ分析を用いての施策は「数パーセントの向上」という掛け算で功を奏するため、事業規模が大きければ大きいほど効果が高いという。たとえば製造業のようにppm、すなわち百万個あたりいくつの不良品といったレベルの品質管理がすでにできている業種では、そこから多少不良品率が低下してもコスト面でのメリットは小さいかもしれない。だが「もの」を単位に分析するだけでなく、これまで精密に見てこなかった「人」にフォーカスして人事側から考察することで、新たな気づきが提供できるという。
ビジネスモデルとしては、月額のSaaSとなっており、データダイバーが60万円(税別)、データフェリーが40万円(税別)で、月額100万円で分析が自社で可能となる。既存のデータ分析関連のコンサルティングなどと比べると、破格の設定ともいえる。
すでにリリースから3年がたち、利用企業には、通信大手や製造、自動車メーカーまで多くの大企業が名前を連ねている。では実際、どのような変化が「データダイバー」を導入することでおとずれるのか。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります