



第865回
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略
2026年03月02日 12時00分更新
前回までは、半導体に関する最高峰の国際学会「IEDM 2026」で発表された話を説明してきたが、その間に、半導体のオリンピックこと集積回路国際学会「ISSCC 2026」が閉幕した。そこで、今回からISSCCで発表された話を説明していこう。

初回は、Session 2-1 "AMD Instinct MI350 Series GPUs: CDNA 4-Based 3D-Stacked 3nm XCDs and 6nm IODs for AI applications"の内容である。前回がちょうどAMD Instinct MI300Xをテーマにしたチップレットの構築だったので、これがAMD Instinct MI350Xでどう変わったかなども加味する形で解説したい。
驚異のTBP 1400W!
AMD MI350シリーズが描く次世代AI基盤の姿
まずMI350シリーズの基本的な特徴が下の画像だ。MI300シリーズと比較して1.9倍のピーク性能であるが、TBPは750W→1400Wと大幅に増えている関係で、性能/消費電力比そのもので言えばほぼ変わらない(1%ほど向上している程度)になっている。

MI350シリーズの特徴。MXFP4をサポートして理論性能は倍になっている計算だし、動作周波数も伸びているのだが、その分CUの数がやや減っているので、性能はピークで1.9倍に留まっている
構造上は、XCDが8つなのは変わらない。ところがMI300シリーズはIODが4つで1個のIODにXCDが2つ搭載される形だったのが、MI350シリーズではIODが大型化され、IODの数そのものは2つに。そしてそれぞれのIODにXCDが4つずつ搭載される構成になっている。
MI350の構造図が下の画像だ。MI300シリーズの構造と比較しても大きな違いがない。もともとMI300Xの時点で、4つのIODをカバーするようなシリコン・インターポーザー(CoWoS-Sで製造)があり、その上でIOD同士の接続される形態だったし、IODの上にXCDが載る構造も同じである。おそらくIOD同士の接続や、IODとXCDの接続の形態はMI300シリーズに準ずる構造になっているものと考えられる。
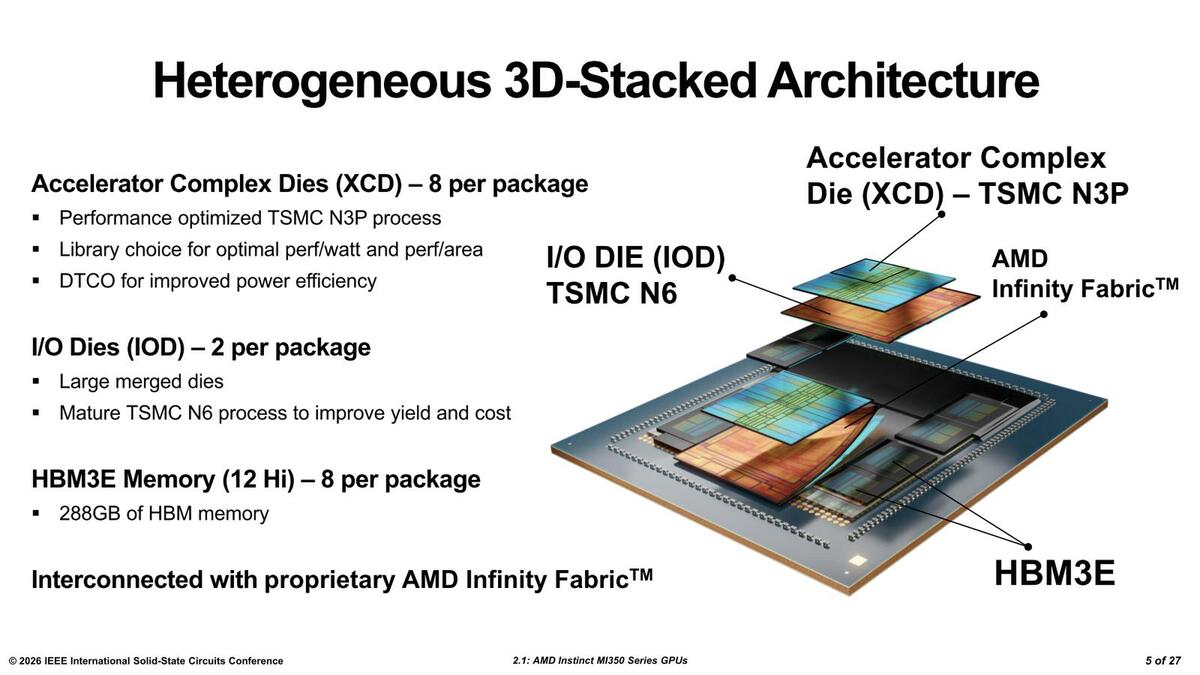
この構造図では横方向のIoD同士の接続がないので、間に配線がないのが違いと言えば違いか。MI300シリーズではXCD/CCDの脇にダミーのダイが明記されていた。MI350シリーズでもダミーダイは存在するものと思われる
では違いがないのか? というとそんなことはなく、XCDはいろいろと異なっている。MI300シリーズとMI350シリーズのXCDの構成を比較したのが下の画像である。
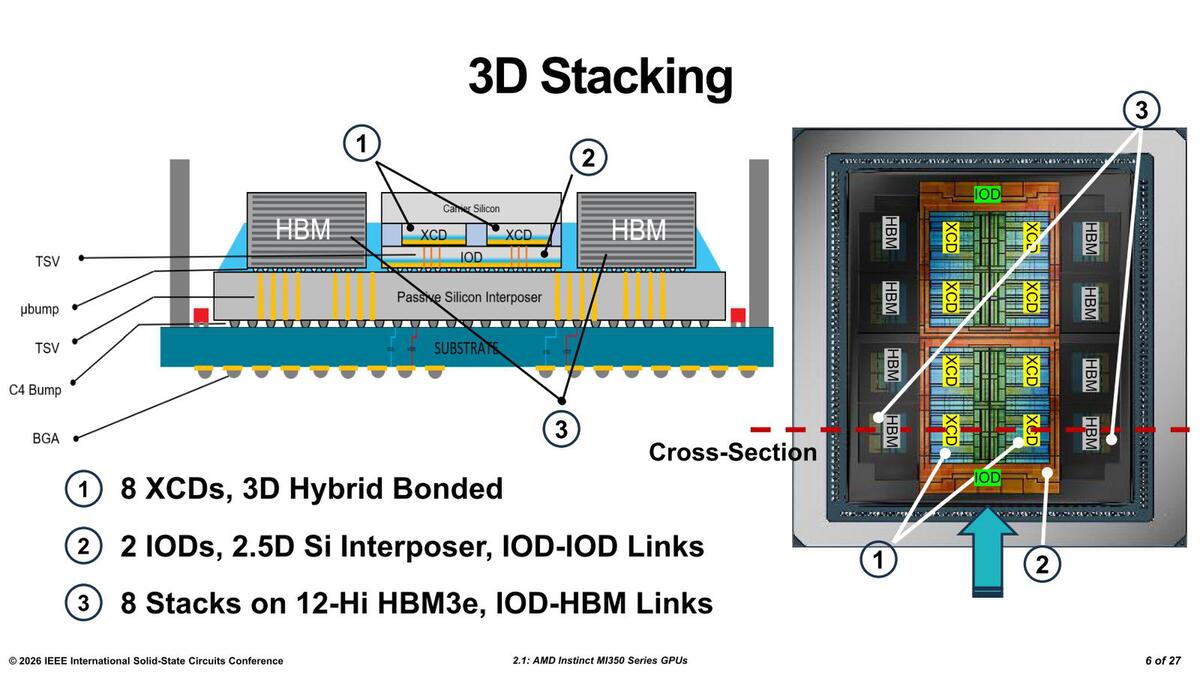
2つのIoDの間の接続が、MI300シリーズ同様にSoWとでも呼ばれる構造(要するにPHYなし)なのかどうかはこのスライドでは判断できない
当然プロセスはTSMC N5からTSMC N3Pになってトランジスタ密度は上がっているのだが、エリアサイズはMI300Xと同じ110mm2に抑えられている。これはおそらくIODの大きさに制限があるため、現実問題として110mm2程度が実装できる限界なのだろうと想像される。配線層は15層から17層になっているが、これはプロセスの特性に起因するためである。

同じ110mm2といっても、横幅は微妙にMI355XのXCDの方が広く、その分わずかに高さが低くなっているようだ
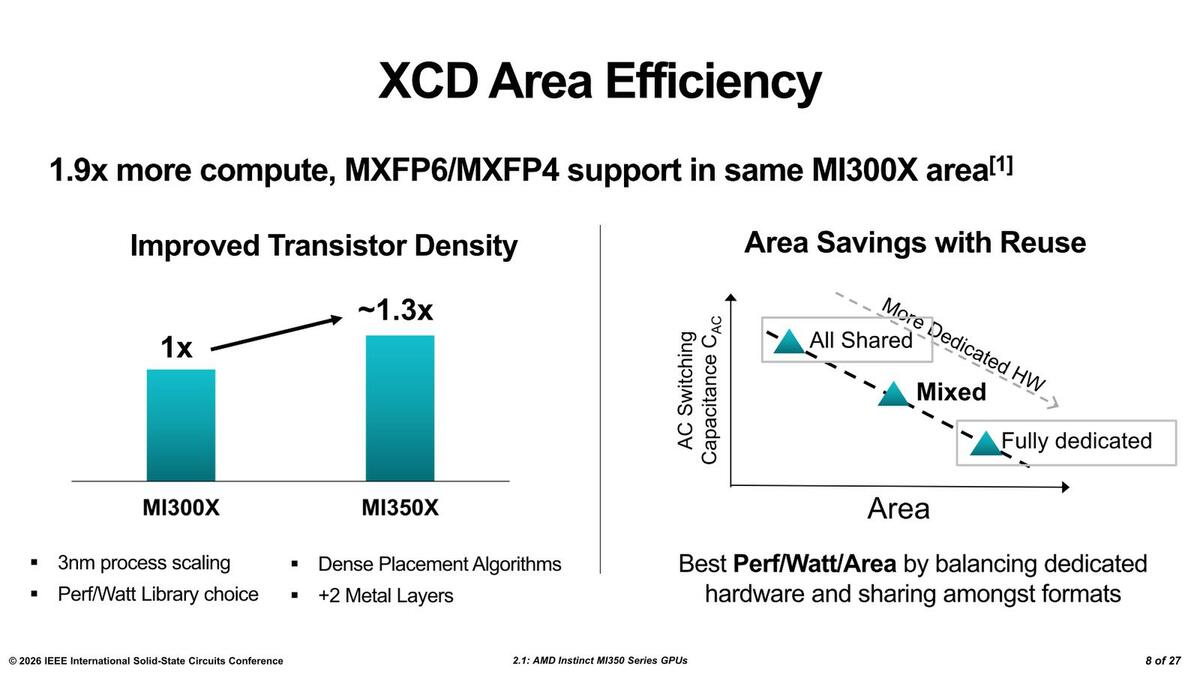
一番おもしろいのはMI300Xでは物理的に40CU(Compute Unit)を実装しており、うち2つが冗長CUで有効38CUなのだが、MI355Xでは物理36CUで、うち4CUが冗長CUとなり、実効32CUであることだ。どちらも4MBのL2+グローバルリソースの大きさはほぼ変わらず、実質的にCUあたりの面積が11%ほど拡大している計算になる。
そもそもTSMCはN5→N3Bでロジック密度が70%向上すると説明しており、N3PはN3Bと比較してやや密度向上(数値は示していない)していることを考えると、トランジスタの数は最大倍近くになっているという計算が成り立つ。
もっともこれはトランジスタの面積だけを計算した場合で、配線密度はそこまで向上しないため実際のトランジスタ数の増加はもっと少ない(次のスライドでは30%増しという数字が出てくる)が、CUの数を増やすのではなく、CUあたりの性能を向上させる方にトランジスタを費やしたことがわかる。
このあたりの損得勘定は難しい。CUを増やすのとCUあたりの性能を引き上げるの、どちらがトータルで性能を上げやすいかのシミュレーションを繰り返した結果だろうが、結果としてCUを減らしてでもCUあたりの性能を上げる方が得策と判断されたものと思われる。
またMXFP6/MXFP4のサポートに関しては、完全に従来の演算器(FP8/FP16/BF16など)との共用でも、専用ユニットを追加するのではなく、適切な中間地点を選んだと説明されている。
MXFP6/MXFP4は指数部を共通化し、仮数部だけそれぞれデータを持つというフォーマット。OCPで定義されている
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります