



CGレンダリングもAI性能もRTX 4090を超越
GeForce RTX 5090を検証、瞬間最大電力で650Wを食らう怪物GPUだった
2025年01月23日 23時00分更新
AIのパフォーマンスも大きく向上
AIのパフォーマンスは「UL Procyon」と「LM Studio」を用い、大規模言語モデル(LLM)のパフォーマンスを比較した。画像生成AIに関しては安定して動く環境が得られず、NVIDIAから提供されたFLUX.1ベースのテスト(UL Procyonの特別ビルド)もDLデータが巨大で時間的に間に合わなかったので割愛した。このあたりは今後の追試で明らかにしていきたい。
UL Procyonでは「AI Text Generation Benchmark」を使用する。大小4つの学習モデルを使い、それぞれに7つのテキスト生成タスクを課した。その際のトークン生成スピードと最初のトークンまでの待ち時間からスコアーを導き出すというものである。
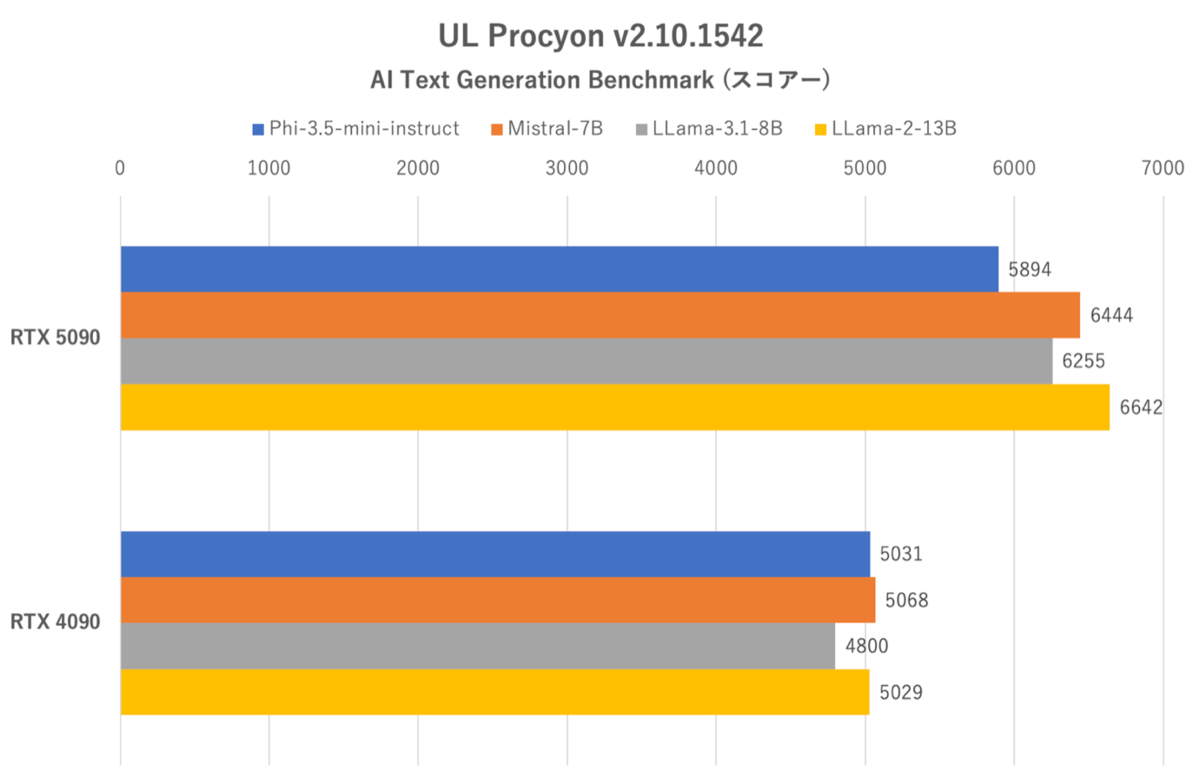
UL Procyon:AI Text Generation Benchmarkのスコアー。学習モデルの重さはPhi-3.5-mini-instructが最も軽く、LLama-2-13Bが最も重い
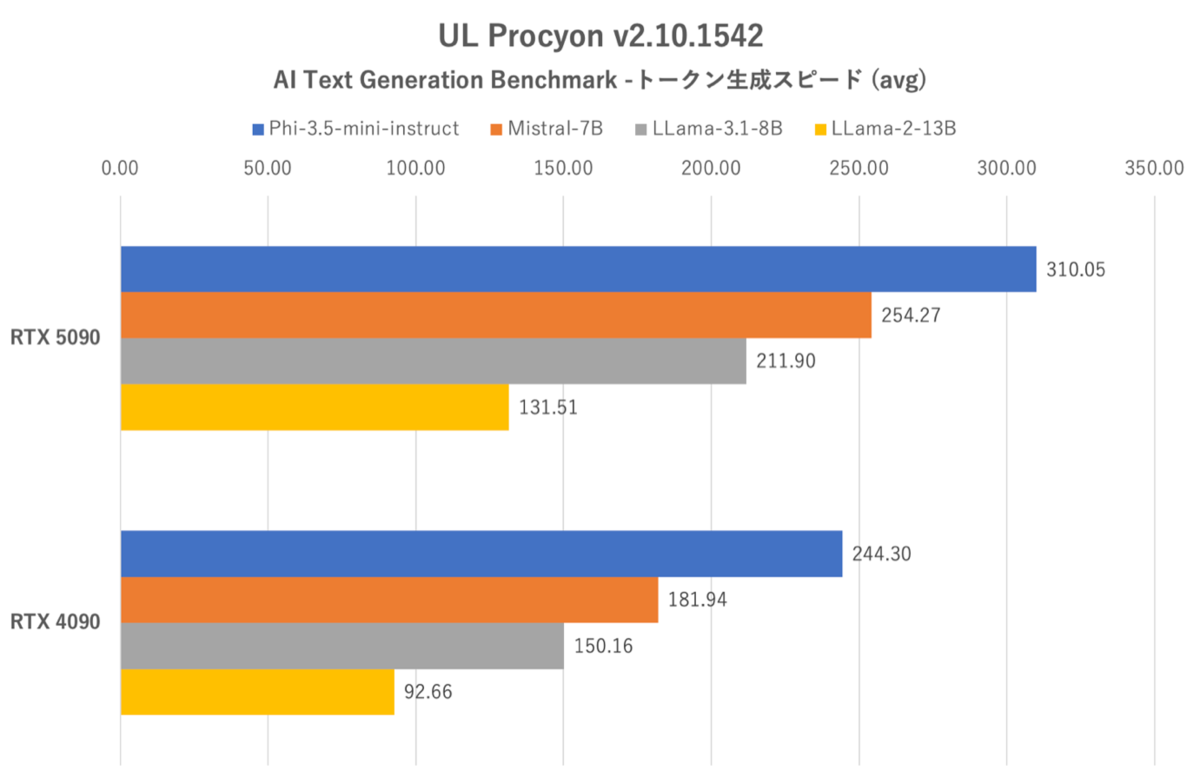
UL Procyon:AI Text Generation Benchmarkにおけるトークン生成スピード(OTS:Output Token Speed)。テストごとに平均値で集計している
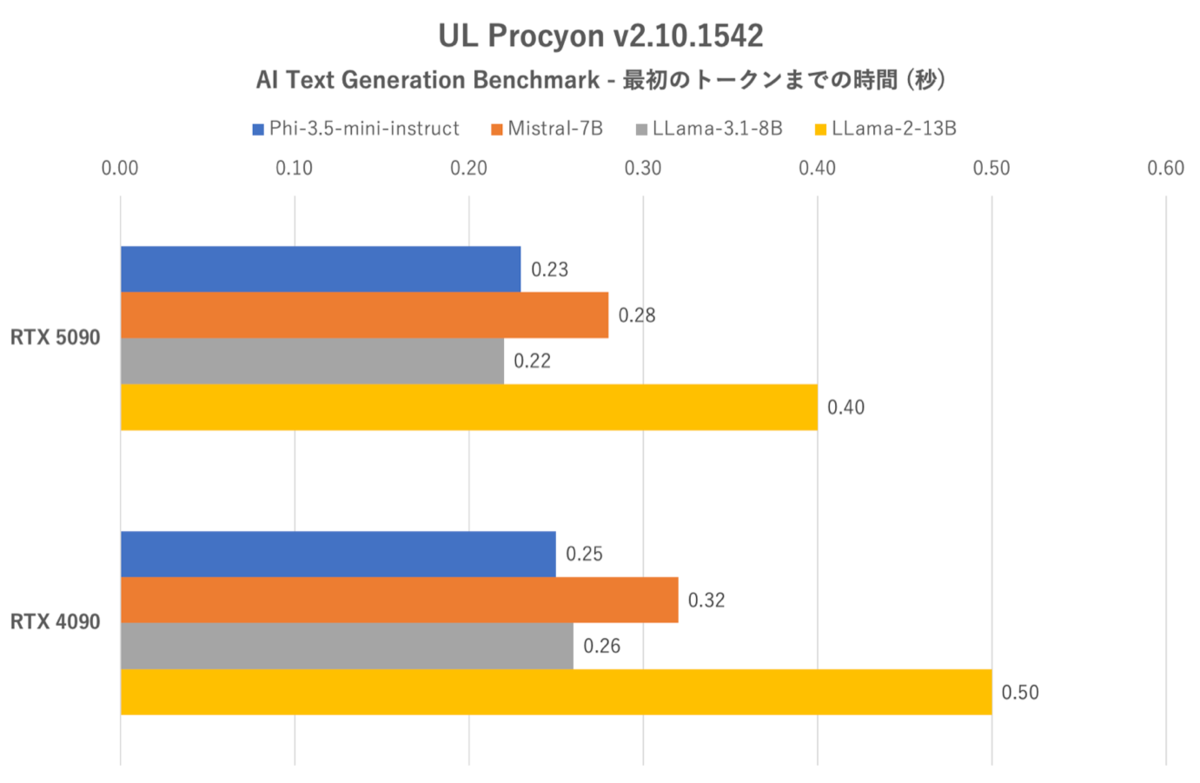
UL Procyon:AI Text Generation Benchmarkにおける最初のトークンまでの時間(TTFT:Time to First Token)
どのテストにおいてもRTX 5090が4090を大きく上回っているが、パラメーター数の少ないモデル(Phi-3.5-mini-instruct)では差が小さく、パラメーター数の多いモデル(LLama-2-13B)では大きくなるなど、3DMarkと似た傾向だった。
複数のAIが同時に走るような状況ではないため、RTX 50シリーズ専用のAMPが威力を発揮している様子はない。しかしながら、AIの馬力という点ではRTX 4090を最大40%程度上回る(トークン生成スピード基準)のはすさまじい。
LM Studioでは学習モデルに「Phi-4 14B Q8_0」を選択。「消えた1ドルの謎」(下記の囲みを参照)を解説するように以下のプロンプトを入力した。シードは固定し、GPUオフロードは最大(GPUを最大限利用する)に設定。1度回答を得るたびにモデルをロードしなおし、3回の平均値で比較した。

LM Studio:トークン生成スピード
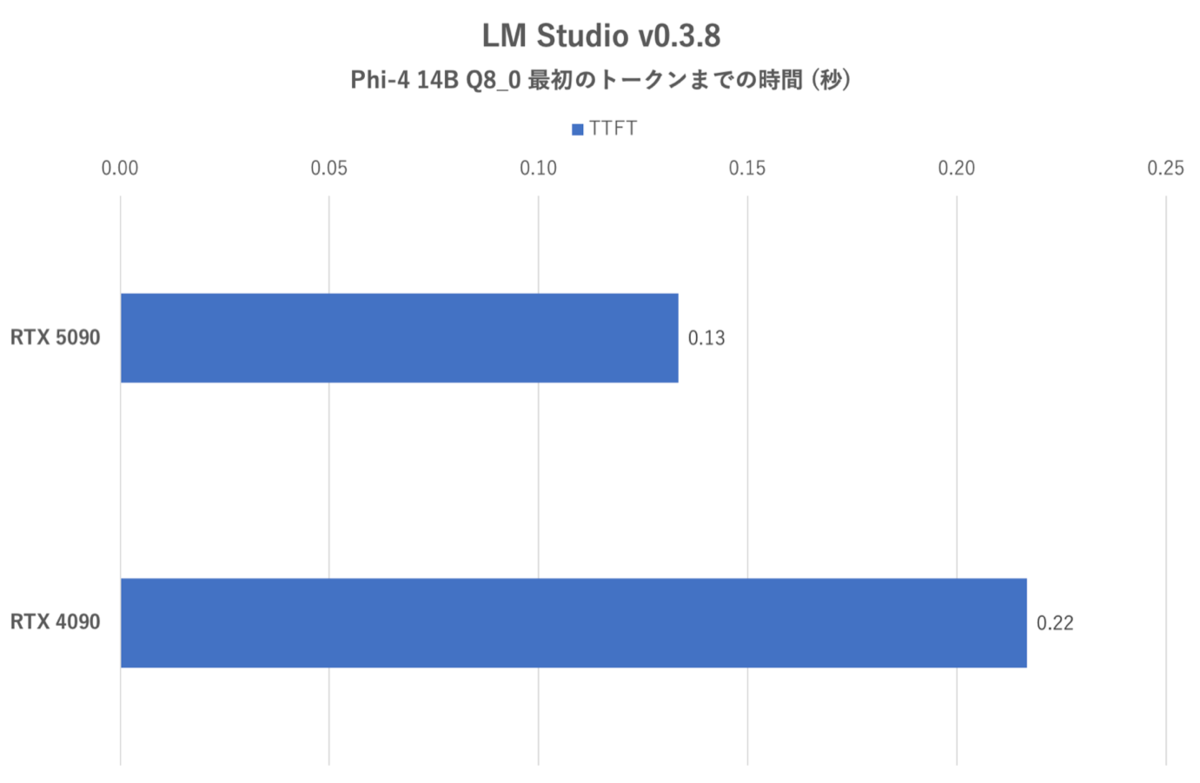
LM Studio:最初のトークンまでの時間
UL Procyonと同様、応答性においても生成スピードにおいて、RTX 5090がRTX 4090を圧倒した。今回は生成されたテキストに対する評価(内容が正しいか)は判定せず、トークン生成スピードだけを評価しているが、スピードに関してはRTX 5090の速さはハッキリと目視できるほどだった。
なお、もっとVRAMを食い尽くすような条件では、RTX 5090の強さをより感じられるはずだが、それは今後の課題としたい。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります