



第797回
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月11日 12時00分更新
テンソル縮約に特化した内部構造
さて第1世代のWarboyでは公開されなかったNPUの中身である。RNGDではTCP(Tensor Contraction Processor)と呼んでいるが、そもそも畳み込みニューラルネットワークなどでは計算の大半がテンソル縮約(Tensor Contraction)の計算に費やされている。
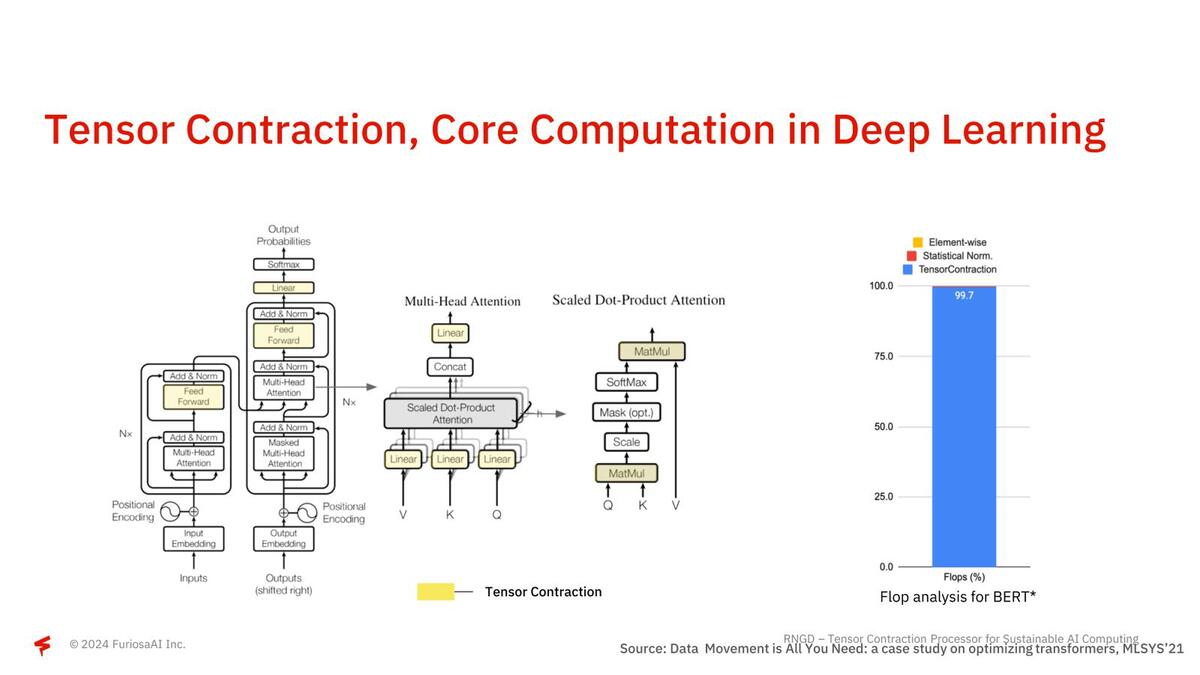
左は実際の処理の中でテンソル縮約が使われる箇所、右はBERTを実施する際の処理の比率で、もうとにかく大半がテンソル縮約であることがわかる
このテンソル縮約は要するに行列積(Matmul)であって、世の中に多く存在するテンソル演算用のアクセラレーター(例えばNVIDIAのGPUに搭載されるTensor Core)はこの行列積を高速に実行するための機構を搭載しているのだが、テンソル縮約≠行列積ではない、とFuriosaAIは主張する。

大抵の行列積の演算は、行列のサイズが決め打ちであり、大規模なテンソル演算の場合には行列を分解して処理をする
要するに扱うべき行列のサイズは、大抵の行列積演算ユニットのものよりはるかに大きいので、固定サイズの行列積演算ユニットを使うのは不効率、というわけだ。RNGDはこれをどうしたかというと、行列のサイズに合わせて行列積の計算に使うコンピュートユニットの数をダイナミックに変更しながら、目的のサイズの行列積を一発で行なえる、というところが異なるとする。
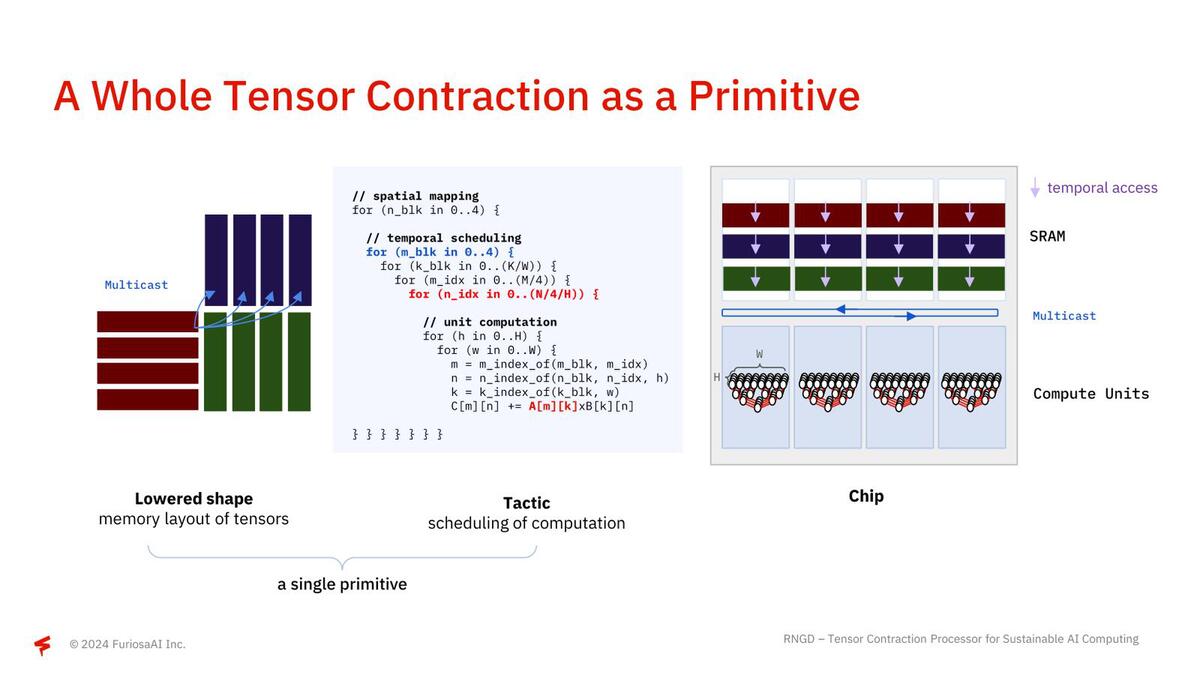
赤と青はそれぞれ積の対象となる行列の要素が入り、緑に演算結果が入る。赤のデータをすべてのコンピュートユニットにマルチキャストする機能が入っているのがポイント
下の画像左側がそのRNGDの構成で、1個あたり64TOPS/32TFlopsの演算性能と32MBのSRAMを搭載するTensor Unitが8つ搭載されている。右側はその個々のTensor Unitの構成で、内部的には8つのプロセッサー・エレメントが配される。
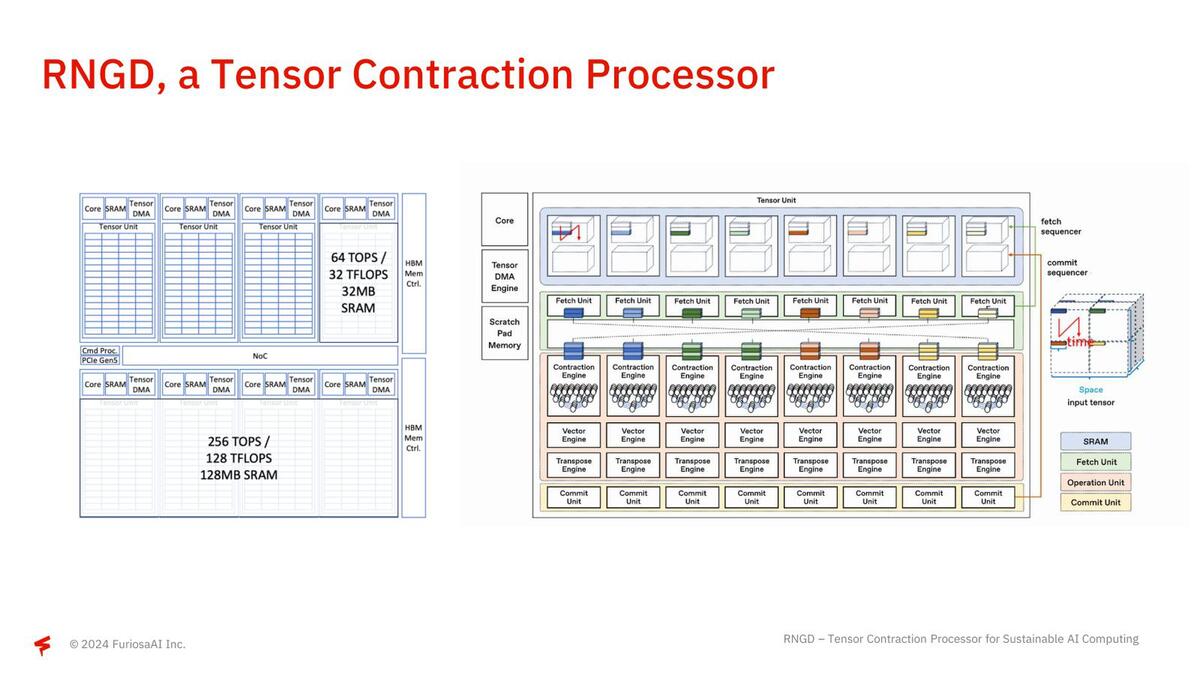
普通は個々のプロセッサー・エレメント内のメモリーと演算ユニットが密結合されており、間にスイッチが入るのはかなり珍しいというか、独特である
ここでFetch/Commit Sequencerと、テンソル縮約を行うContraction EngineやVector Engine/Transpose Engine/Commit Engineの間にスイッチが入っているのがミソで、大規模な行列に対してすべてのContraction Engine類が協調する形で処理できるようになっている。また個々のTensor Unitの間は非常に高速なNoCでつながっており、HBM3の帯域をすべてのTensor Unitで使い切れるような構成になっている。
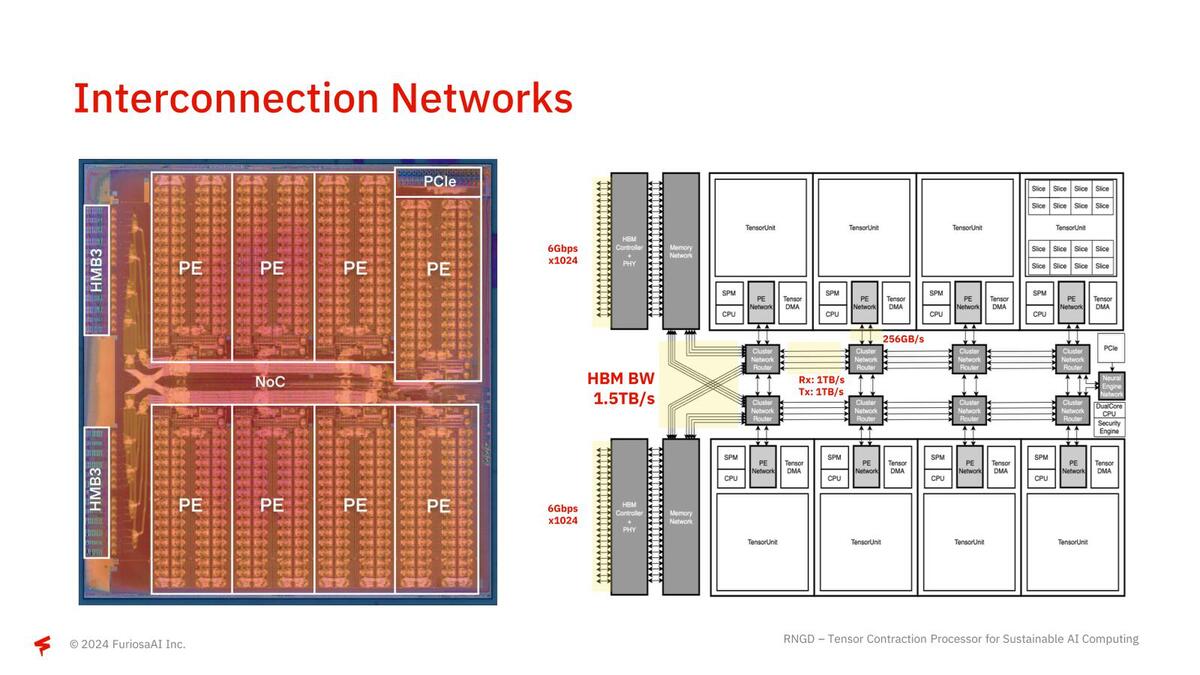
このネットワークは単にHBMとのやり取りだけでなく、Tensor Unit同士での接続にも使える模様。例えば1つのTensor Unitでは収まりきらないような大規模な行列の場合、複数個のTensor Unitで連携して処理できるようだ。それにしてもPCIeのI/Fがずいぶん変なところにある気がする
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります