



第793回
5nmの限界に早くもたどり着いてしまったWSE-3 Hot Chips 2024で注目を浴びたオモシロCPU
2024年10月14日 12時00分更新
128bit SIMDに変更されたWSE-3
DGX-H100と比較しても5倍以上高速
やっと2024年のHotChipsでの発表に移る。今回Cerebrasは第3世代のWSE-3を発表した。ただTSMC N7→N5ではあまり微細化の効果が得られていない。トランジスタ数こそ2.6兆個→4兆個で、倍増とは言わないまでも54%程増えているが、PEの数は85万個→90万個で5.8%増。搭載メモリー量は40GB→44GBだから10%増と、ほんのわずかでしかない。

WSE-3。トランジスタ数が大幅に増えているというのは、PUの内部が大幅に変わったことが主要因だろう
なぜPEの増加量とメモリーの増加量が一致していないかは後で説明するとして、7nm→5nmではロジックは微細化の恩恵を多少は受けるが、SRAMの微細化はほとんどない、という実例のような結果になってしまった。もちろんそれでも動作速度向上(あるいは同じ動作周波数で消費電力削減)の効果は見込めるため、意味がないわけではないのだが。
さてWSE-3では、PUの内部が大幅に変更になった。WSE-2までは16bit FMAC×4の構成だったのが、WSE-3では128bit SIMDに変更され、また8bitでは16個のデータを同時に処理できるようになった。演算性能だけで言えば、16bitで従来の2倍、8bitなら4倍になる計算である。
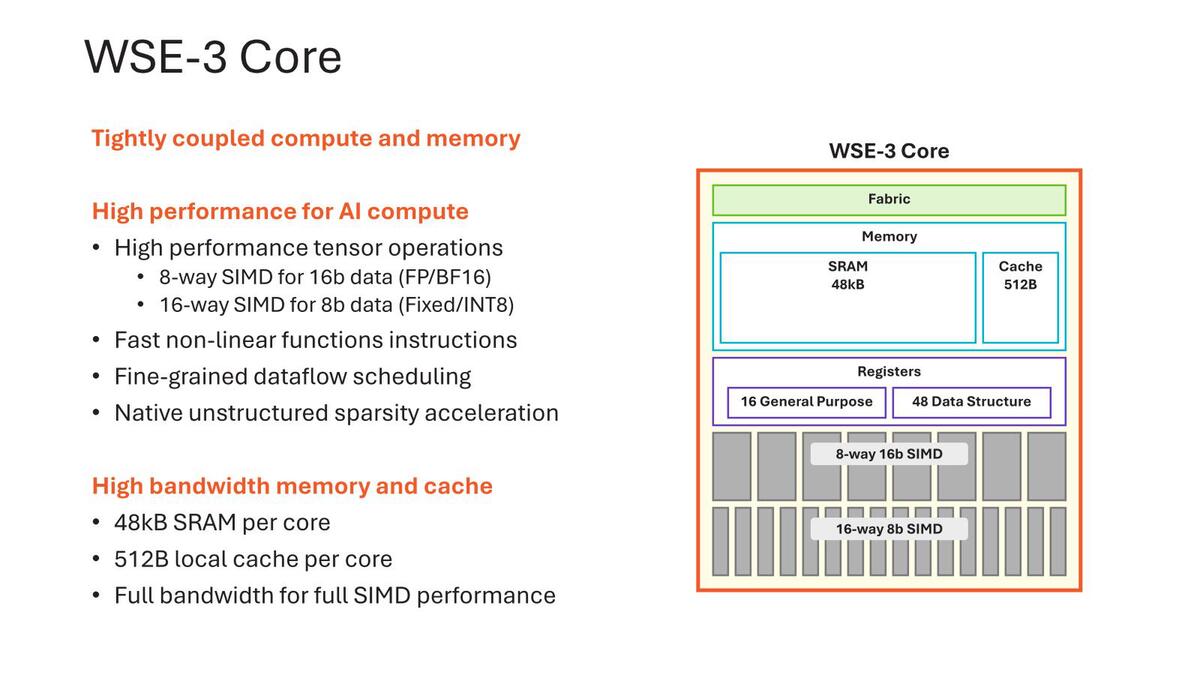
SRAM増加量がPU増加量より多いのは、一つはCacheが256Bytes→512Bytesになったこと、それとDSRが44→48になったこと。それとGPR/DSRともに従来は64bit幅で済んだのが今回128bit幅に拡張されたこと、の3つが関係していると思われる。逆にSRAMそのものには変更はなさそうだ
ただ、演算性能が2倍なり4倍になったりするのであれば、それに合わせてメッシュネットワークの高速化もしないと追い付かない気もするのだが、それに関する説明は今回なかった。変更がないのか、変更はあるけどまだ未公開なのかは不明である。
性能という意味で示されたのが下の画像である。Llama 3.1-70Bの推論が、Cloudベースのソリューションは元より、DGX-H100と比較しても5倍以上高速としている。
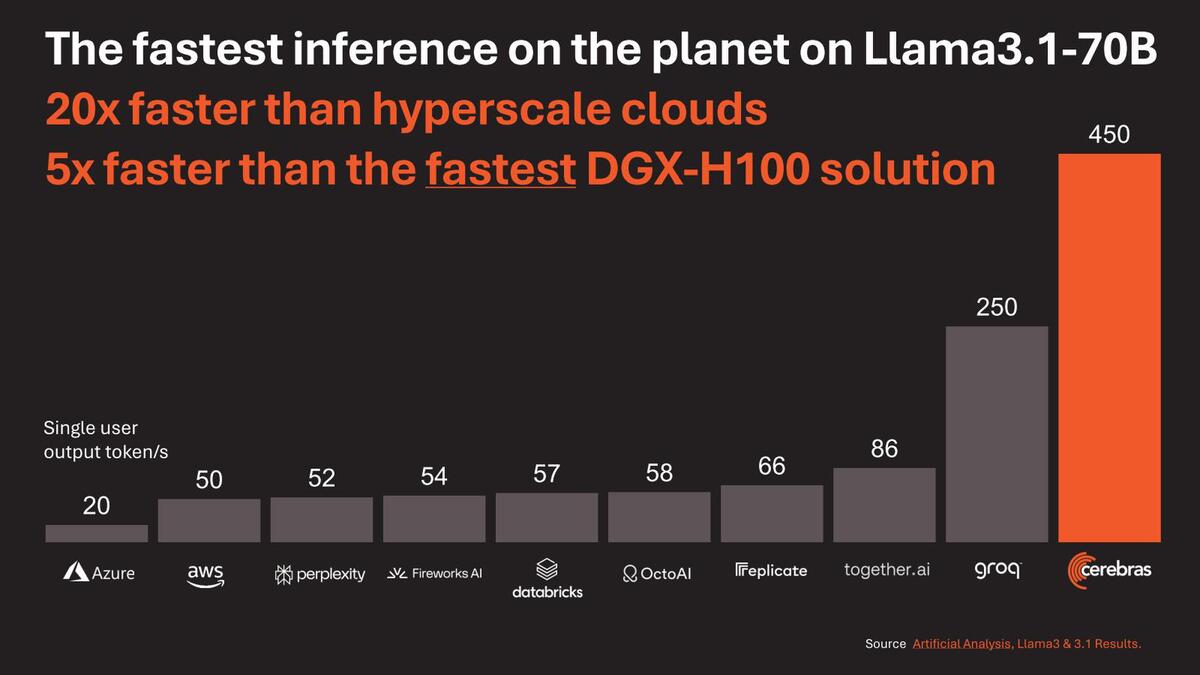
WSE-3の性能。それでもGroqが半分以上の性能を残しているのはさすがだと思うが。ちなみにLlama3.1-8Bの場合、Groqは750Token/s、WSE-3は1800Token/sだそうだ(DGX-H100は不明)
ちなみにこの理由に関してのCerebrasの説明が下の画像だ。要するにHBMの帯域がネックになっているから、ということだ。
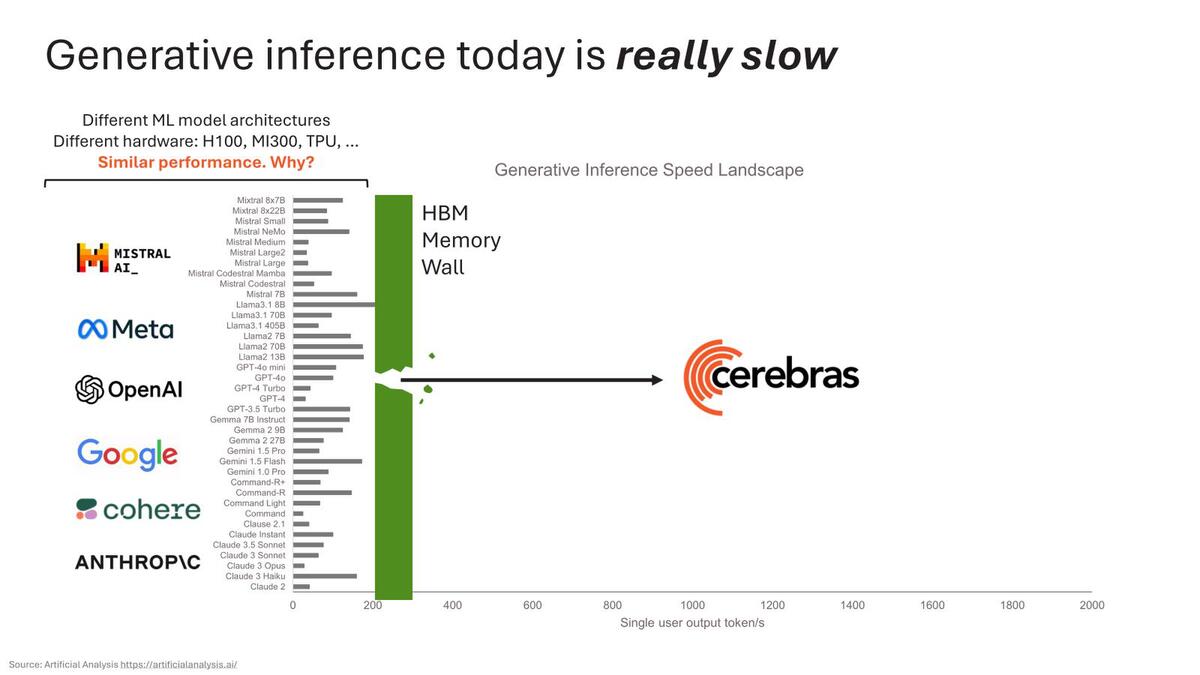
どんなモデルであっても、だいたい200トークン/秒あたりでメモリーの限界に達する、としている
そうなると、WSE-3とH100を比較するとメモリー帯域は7000倍と言っているわりに性能は5倍にしかならないのか? という疑問が出てくるわけだが、これは実際には大規模ネットワークを稼働させると煩雑にMemoryXから重みを読み出す必要がある。層ごとにこの読み出しが入るわけで、これがボトルネックになっているものと思われる。
それにしてもWSE-3はもう5nmの限界にたどり着いてしまった感がある。これ、このまま3nmに持っていっても性能が大して上がらずにコストだけが跳ね上がりそうだ。WSEの欠点は少ないメモリー量で、これを補うためには次世代ではロジックウェハーの下にSRAMウェハーを3D接続するなどしてローカルのSRAM量を増やすとともに、SwarmX/MemoryXとの帯域を大幅に引き上げる必要がある。
ただ現状でもSwarmXが明らかに能力不足の感がある。これをスイッチメーカーと協業するなどして改善できれば、もう少し性能の伸びが期待できそうではある。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります