



第793回
5nmの限界に早くもたどり着いてしまったWSE-3 Hot Chips 2024で注目を浴びたオモシロCPU
2024年10月14日 12時00分更新
Hot Chips第6弾は、CerebrasのWSE-3を取り上げる。Cerebrasは連載572回で紹介したが、Celebrasは2019年のHotChips 31でWSEを発表して以来、HotChipsの常連となって毎年のようになにか発表している。
もちろんIBMやインテル/AMDのように毎年多数のチップを発表しているメーカーならこれは珍しくないのだが、WSEシリーズしかないメーカーでこういうのは珍しい(単に発表の場をスポンサー枠で購入しているだけ、というのは口の悪い言い方かもしれないが)。
ちなみに同社は2018年にTraining Session 3(Accelerating Training in the Cloud)も実施しており、これまで入れると7年連続での登場になる。
85万コアを有するウエハースケール計算エンジンWSE-2
HotChips 32から今年のHot Chips 2024までの間の発表を簡単にまとめると、まず2020年のHotChips 32は"Software Co-design for the First Wafer-Scale Processor (and Beyond)"と題して、初代WSEことWSE-1上でどうソフトウェアが動作するのか、あるいは逆にソフトウェアでどうWSE-1の上の動作を制御できるのかの説明があった。詳細は割愛するが、この講演の最後で第2世代製品に関するプレビューが示された。

WSE-1が1.2兆トランジスタ、40万コアなので、第2世代製品は倍以上である
翌2021年のHotChips 33ではWSE-2ことWSE-2が発表された。チップの面積そのものはWSE-1と同じく46,225mm2であり、一方でトランジスタ数やコアだけでなく、オンチップメモリーは18GB→40GB、メモリー帯域は9PB/秒→20PB/秒といずれも2.2倍ほどに膨れ上がっている。要するにプロセスをTSMC 16FFからTSMC N7に変更しただけで、これだけのコアやメモリー容量向上が実現した格好だ。

WSE-2。チップサイズは、もともと300mmウェハーのギリギリを攻めていたので、300mmウェハーを使う限りこれ以上大きくはならない
WSE-1からWSE-2の変更はこれだけでなく、新たにSwarmXおよびMemoryXという名称のシステムが提供開始され、これで最大192台のWSE-2でクラスターを構築可能になったとしている。

このスライドではSwarmXがスイッチ6台で実装されているように描かれているが、実際はもう少し大きくなると思われる
このクラスターの目的は、大規模ネットワークへの対応である。オンチップメモリーで40GBというのはある意味驚異的ではあるのだが(なにせこれは全部SRAMである)、絶対的な量という意味では全然足りていない。
そもそもNVIDIAのA100ですら40GB版に加えて80GB版をリリース。H200は141GB、GB200ではHBMだけで384GBを搭載する。AMDもInstinct MI300Xで192GBを搭載したが、次のInstinct MI325Xでは288GBに増量することを発表している。LLMの規模がどんどん大きくなることでメモリー不足になるのは明白である。
これはCerebrasも認識しており、そのための対策として提供されたのがチップの外にメモリープールを置き、これをインターコネクトで接続するという上の画像の構成である。

この時点ですでに1T(1兆)パラメーターのMSFT-1Tが出ており、10TBを超えるメモリーと10EFlopsの処理能力が必要、とみなされていた。なんというか縦軸と横軸がどちらも対数表現というのが結構イヤな話である
このMemoryXを併用する場合、重みデータはすべてMemoryXに置かれる形になり、アクティベーションのみがWSE-2のSRAMに格納される形になる。またこの重みのアップデートはMemoryX内のプロセッサーで行なうため、WSE-2には負荷をかけずにできるとする。
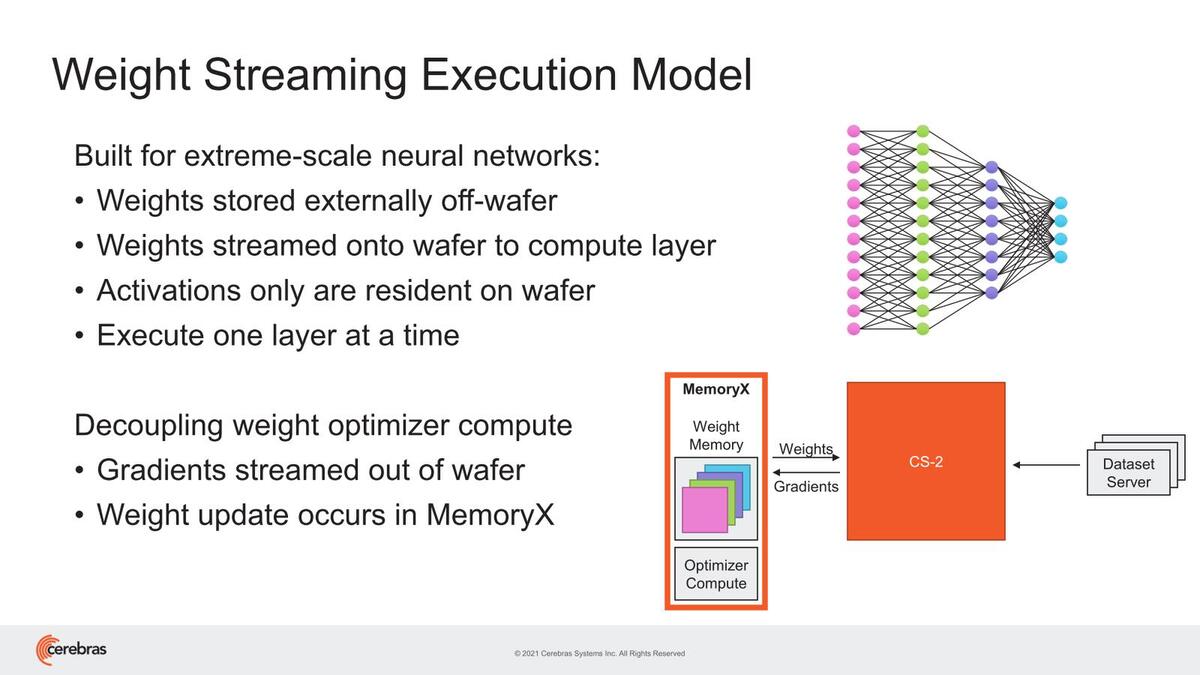
この場合、MemoryXからWSE-2への重み(Weight)の伝達は、間に入るSwarmXがブロードキャストで実行されるので、仮に192台のWSE-2があってもMemoryXからの読み出しは1回で済む
ちなみにこのMemoryXは、2~192台までのWSE-2に対応し、4TB~2.4PBまでのメモリー搭載量であるとしている。

当然2.4PBものDRAMを実装できるわけもなく、"DRAM and flash hybrid storage"であるとしている
4TBの場合で200B個、2.4PBなら120T個のパラメーターを格納できるとしているほか、内部動作をパイプライン化することでレイテンシーを遮蔽できるとしているが、このあたりの詳細は語られていない。
全体でクラスターをいくつまで論理的に分割できるのかは明示されていない。分割可能であることはわかっているが、その1つの論理的なクラスターに所属するWSE-2は、すべて同じネットワークを動かし、重みも共通して持つ形になる。
2つ上の画像で"Execute one layer at a time"という言い方をしているあたり、ネットワークのある層を複数のWSE-2で分割して処理する形であり、その際にMemoryXはSwarmX経由で、その層の重みを対象のWSE-2にブロードキャストするようだ。
この方式のメリットは、WSE-2の台数にほぼ比例する形で性能がスケールすることだとしている。従来のGPUやAIプロセッサーの場合、結局重みをおのおののローカルメモリーで保持するこになるため、最初にメモリーネックになる。結果、多数のAIプロセッサーやGPUをクラスターにしても、性能が生かしきれない(煩雑にホストとの間で重みのやり取りが発生する)。ところがMemoryX+SwarmXを組み合わせると、この問題が一気に解決するこになる。
もちろんメリットばかりではない。MemoryXを組み合わせると、1層の処理ごとにMemoryXから重みを受信する必要があるので、カード1枚当たりの性能はオンチップSRAMだけを使った場合に比べれば落ちることは避けられない。
もっとも先に書いたようにWSE-2でも40GB「しか」メモリーはないので、大規模LLMを稼働させようとするとホストから煩雑に重みを受け取る必要があり、それよりはMemoryX+SmarmX経由で重みを受け取る方が速い上にスケールする、というわけだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります