



第791回
妙に性能のバランスが悪いマイクロソフトのAI特化型チップMaia 100 Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月30日 12時00分更新
タイル1個あたりの性能が妙に高すぎてバランスが悪い
これをどう料理していくかが見もの
では現状ではチップ間をどう接続するか? であるが、400Gイーサネットを3本束ねて1200Gbpsのリンクを作り、これでチップ間接続およびノード間接続を行なう仕組みだ。1200Gbpsが4対分あるので、トータルで4.8Tbpsもの巨大な帯域を確保している。
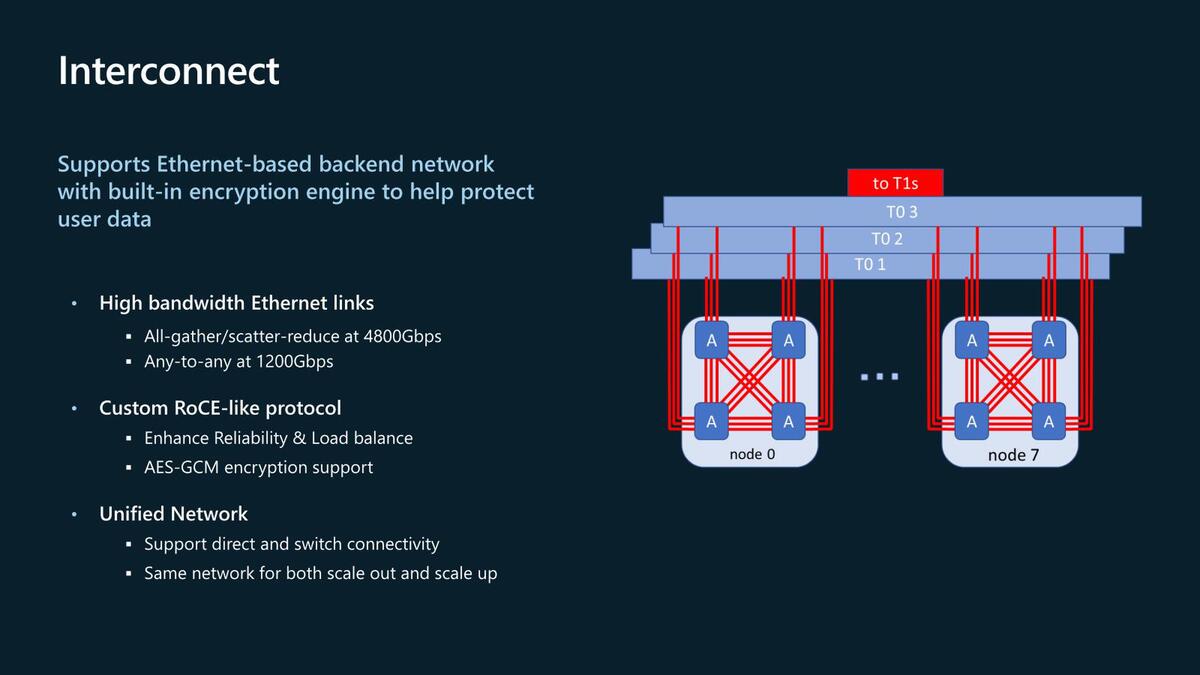
少なくとも第1世代のMaiaは、4つのチップで1つのノードを構成することになり、また1つのTO(Top of Rack Switch)に接続されるのは8ノードで決まりのようだ。これはラックの供給電力からの決定だろう。ちなみにTop of Rackとか言いつつ、スイッチの置き場所はラックの中央である
なお、マイクロソフトはUltra Ethernet ConsortiumのSteering Memberの1社でもあり、現在は独自プロトコルを実装しているとされるが、将来はウルトラ・イーサネットに置き換えられることになると思われる。
そのMaia 100のSoftware Stackが下の画像で、Pytorchベースの他にTritonベースとMaia APIの、合計3種類に対応する。Pytorchは広く使われているが、TritonはOpenAIが発表したOpen Sourceの言語で、Maia APIは名前の通りMaia専用のライブラリーとなっている。
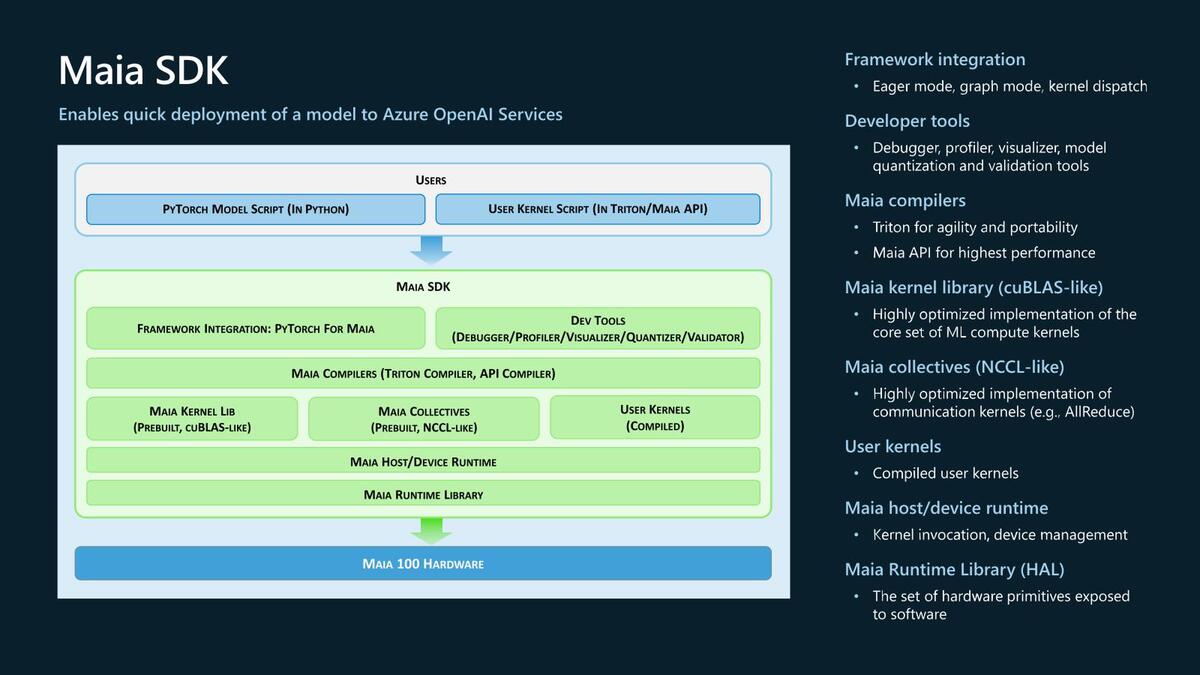
Tritonは高レベル言語であり、例えばFlash-Attentionを50行ほどのコードで記述できるのに対し、Maia APIは低レベル言語で、Flash-Attentionの記述には1000行ほど要するとする。ただしその分高速とのこと。Maia APIはマイクロソフトが自社のサービスの構築用に用意し、ユーザーにはPytorchとTritonを使ってMaia 100を使ってもらうという形だろう
以上がMaia 100に関する現時点で公開された情報である。なんというか、タイルの中の詳細などは一切明らかになっていないし、そのあたりを公開するつもりもない(おそらくMaia APIを使う際には必要なのだろうが、Maia APIを外部に公開するつもりがないのかもしれない)。
ただ冷静に考えると、BF16でも0.8POPs(800TOPS)である。16個のクラスターおのおのに4つのタイルが内蔵されているから、タイルあたりで言えば50TOPSの演算性能になる。これを実現するのはそう簡単ではない。動作周波数も不明だが、例えば2GHzだとすると1サイクルあたり2万5000 Op/サイクルになる計算だ。
この数字はTTUとTVPを合わせてのものだろうが、例えばTTUが24000 Op/サイクル、TVPが1000 Op/サイクルとしてもけっこう実装は難しい。なんというか、タイル1個あたりの性能が妙に高すぎるのである。SIMDで言えば1000Op/サイクルということは1万6000bit幅のSIMDとかいうバカげた代物になりかねない。
妙にバランスが悪い気がするのである(Granularityが大きすぎる、という表現ならおわかりいただけるだろうか?)。そうした部分も含めてまだ謎は多い。現在マイクロソフトはGen 2 Maiaを開発中という話で、先ほどのメッシュのところで触れたチップレットの可能性を含め、どんなふうに進化していくのか楽しみである。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります