



第789回
切り捨てられた部門が再始動して作り上げたAmpereOne Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月16日 12時00分更新
2023年にクラウド向けのAmpere Oneファミリーを発表
Ampere Alter/Alter MAXから3年あまり経過した2023年5月、Ampere ComputingはAmpere Oneファミリーを発表する。最大192コアの構成で、クラウドに最適化したカスタム構成と説明されていた。ただこの時点では、そういう製品が存在することだけがアナウンスされており、具体的な登場時期や詳細な構成などは一切明らかにされなかった。
2024年の5月にはアップデートが公開され、コア数は最大256まで増やされるとともに、QualcommのCloud AI 100 Ultraを組み合わせたAI推論向けのソリューションを提供することもアナウンスされたものの、詳細は引き続き明らかにされていない。
現実問題として2018年に一度X-Gene 4がご破算になり、そこから新規にCPUの設計をスタートすれば、5~6年かかるのはごく普通のことである。加えて言えば、Ampere Oneの最初のシリーズはTSMCの5nmを利用するが、ご存じの通りこのプロセスは大人気で、大口ユーザーはともかく会社規模としてはスタートアップ+αでしかない同社の優先度はどうしても下がるため、製造には時間を要するのも仕方がない。
それでもなんとか2024年8月には量産出荷を開始するとともに、今後のロードマップを開示した。
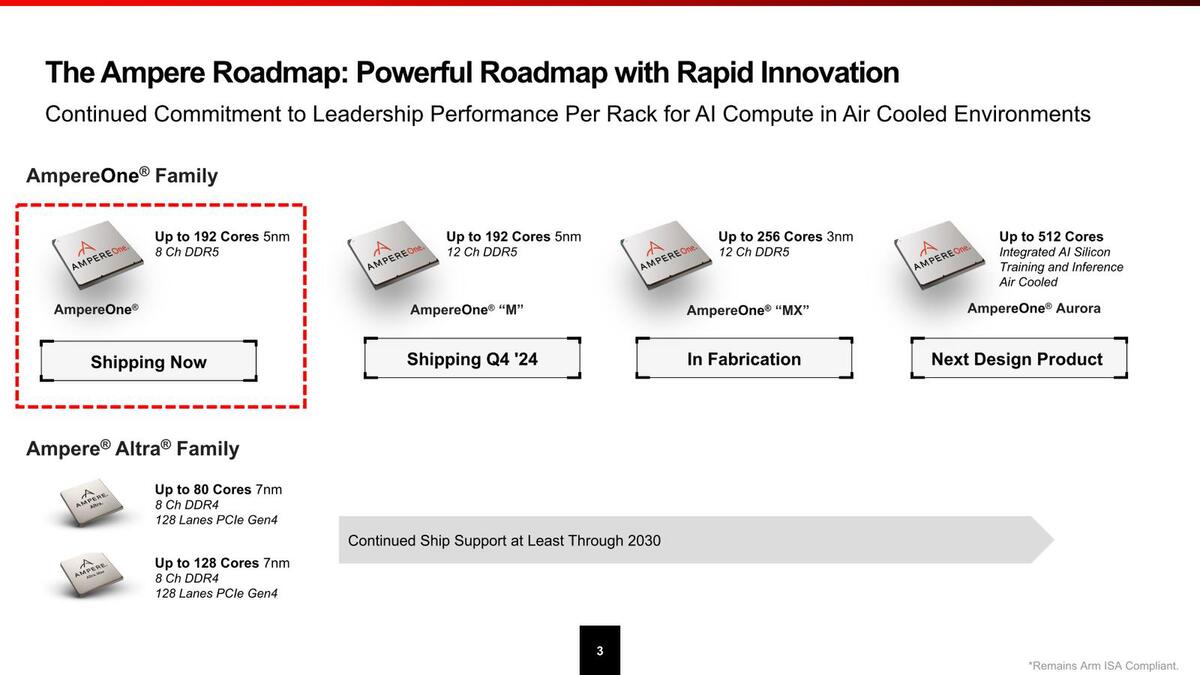
まずはメモリー8chのAmpereOne、次いでメモリーを12chにしたMバージョンとなり、256コアは3nmに移行した先ということは、早くて2025年後半だろうか?
そんなAmpereOne、まずコアの内部構造が下の画像である。
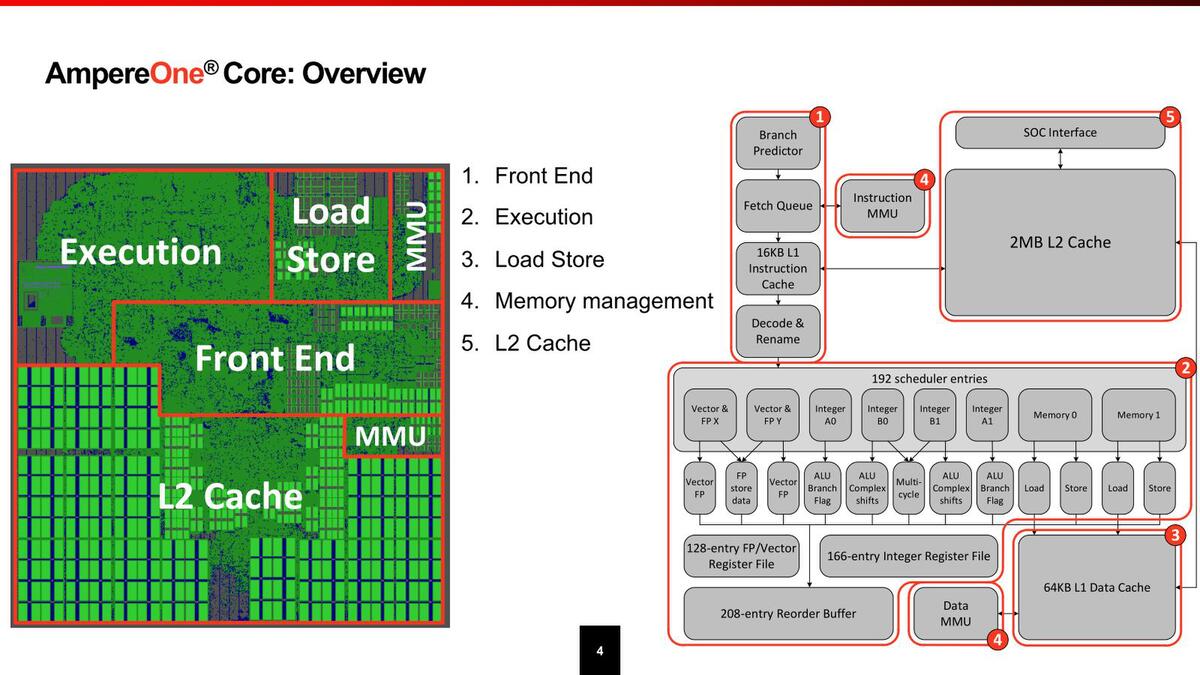
AmpereOneの内部構造。MMUとはなんだ? という話だが、これは単にTLB(Translation Lookaside Buffer)のことであった
基本的なAmpereOneの設計方針だが、絶対性能よりも性能/電力比やコア数に比例した性能、それと汎用性といったものを重視するとしており、これはインテルで言えばEコアベースのSierra Forestやその後継のClearwater Forestの方向性に近い。

おそらくX-Gene 4は左側の方向性を志向したコアだったのだろうな、と想像される。それはともかくハイパースレッディングはインテルの商標だった気がするのだが……
この思想はコアの内部構造にも反映されている。デコーダーは同時5命令で、これを4 MicroOpに変換してスケジューラーに送り込む格好だが、デコーダーそのものは最大で8命令/サイクルまで対応しているとする。
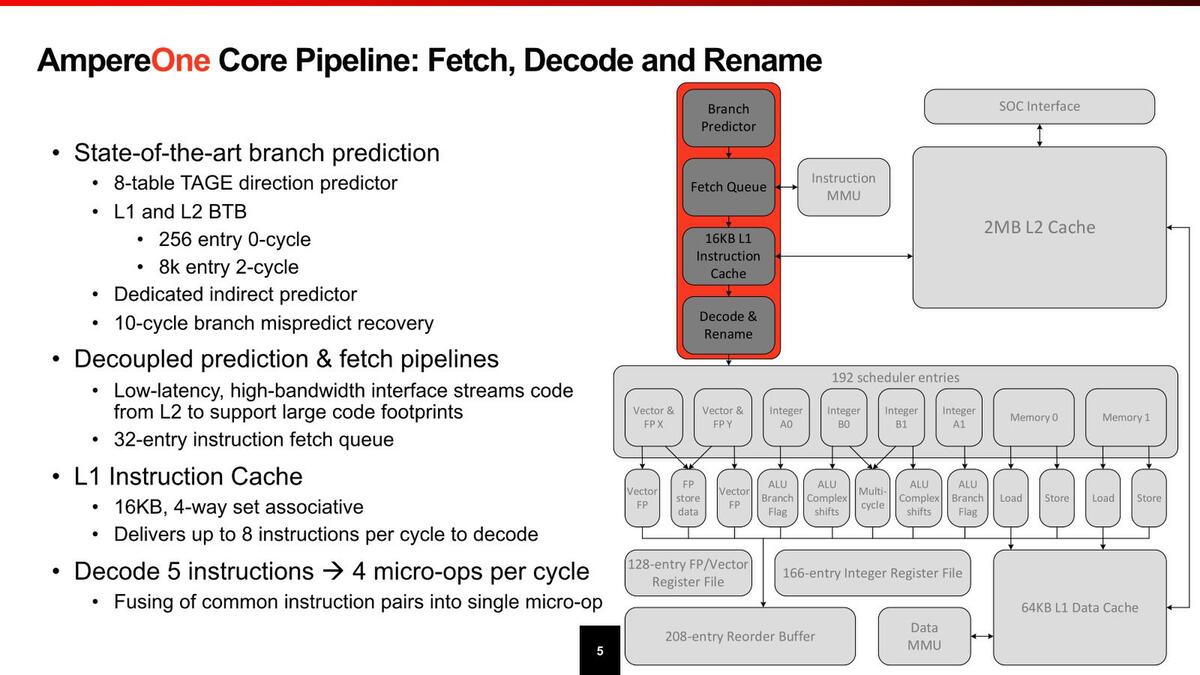
命令が減るのはMacro-Op Fusionを行なうからであるが、ただAArch32(32bit命令)はともかくAArch64(64bit命令)がそこまでMacro-op Fusionが効くのかやや疑問である
ここで性能を大幅に引き上げようと思ったらMicroOpキャッシュを設けるのが効果的だが、それをせずに32エントリーのフェッチキューのみで済ませているあたりは、AmpereOneのワークロードではMicroOpキャッシュが効くような処理はあまり多くないと考えているのかもしれない(API Server的な用途では、繰り返し処理の頻度が大幅に減るからMicroOpキャッシュが相対的に効きにくい)。
このあたりはピーク性能よりも性能消費電力比を重視して、あえてそこそこの性能に抑え、その分回路規模を小さくしたのかもしれない。
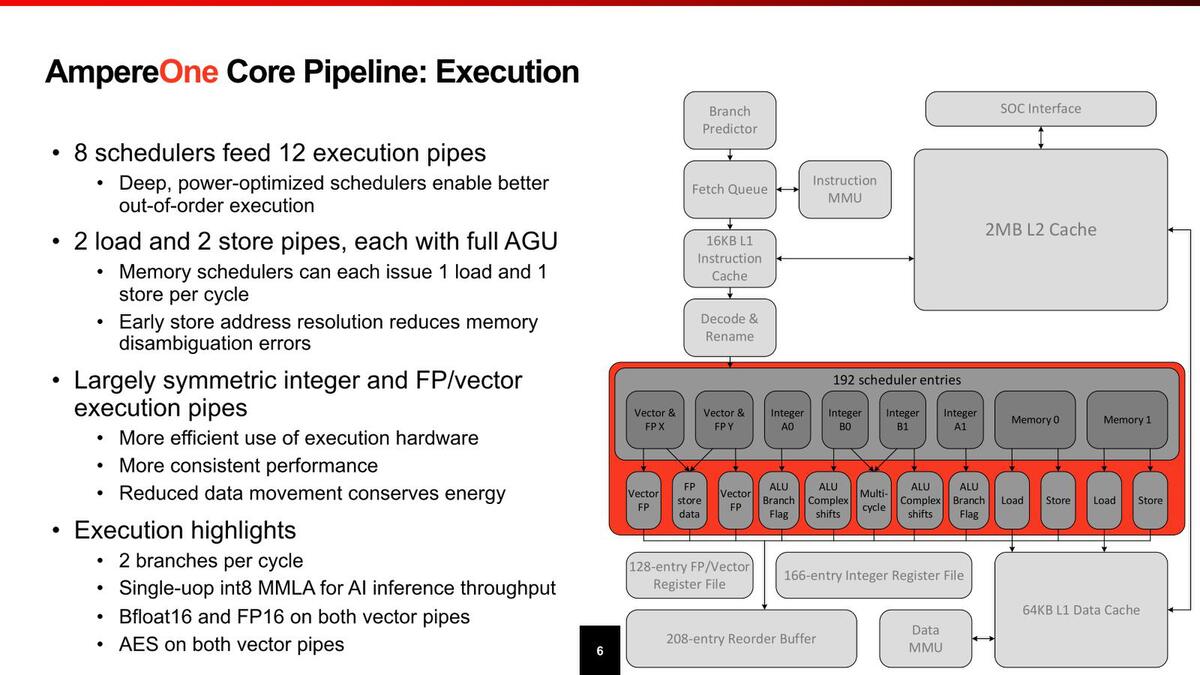
Multi-cycle(1サイクルで処理を完了できない命令向け)が別のユニットになっているのがおもしろい。つまり他の4つのALUは基本1サイクルで処理を終わらせる構成になっているわけだ
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります