




グーグルは7月1日(現地時間)、個人情報の扱いを詳細に規定したプライバシーポリシーを改定した。
グーグルはこれまで「Google翻訳」の機能向上などのためにインターネット上で公開されている情報を収集し利用してきたが、今回の改定で大規模言語モデル「Bard」をはじめとするAIモデルのトレーニングにも利用するという条項が追加された。ただし、現在のところ日本語版のプライバシーポリシーには記載されていない。
収集データの使い道に「Bard」などAI製品のトレーニングを追加
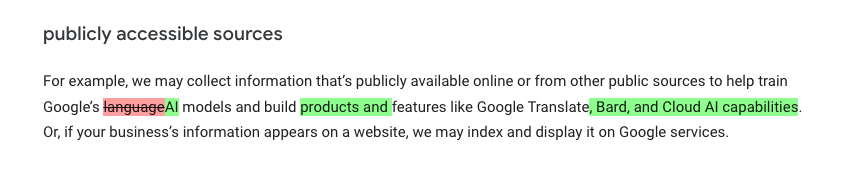
上記の画像は最新のプライバシーポリシーの中の「publicly accessible sources(一般に公開されている情報源)」の定義の部分だ。ピンクのアンダーラインは削除された、緑のアンダーラインは追加された文言になる。
これまでは「言語モデルのトレーニングやGoogle翻訳」だけだった、収集データの使い道に「Bard,クラウドAI製品の構築」が追加されているのがわかる。
Twitterはスクレイピングを理由に閲覧制限
このようにインターネット上に公開されている情報を機械的に収集する行為はスクレイピングまたはクローリングと呼ばれ、グーグルに限らず多くの企業が市場調査やデータ分析などを目的に行っている手法だ。
近年はトレーニングのために大量のデータを必要とするAI、特に大規模言語モデルのトレーニングを目的に、グーグルだけではなく他の企業もスクレイピングしたデータを利用している。
だが、スクレイピングはサーバーに大量のリクエストを一度に送るため大きな負荷がかかるという問題がある。Twitterが閲覧に制限を設けたのは(イーロン・マスク氏いわく)スクレイピング対策が理由だ。同様の理由で掲示板型コミュニケーションサービスの「Reddit」もAPI経由の無料アクセスを無効にしている。
日本語版は調整中か?

2022年12月15日版のプライバシーポリシー
ここまでは米国向け(英語版)プライバシーポリシーの話しだ。日本語で表示すると「公開情報」の扱いを定義した項目自体がまるまる削られている。訴訟も増えAIに関する法整備が急ピッチで進められている中、調整に難航しているのかもしれない。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります