




Google I/Oにて、次世代の大規模言語モデルPaLM2を発表するスンダル・ピチャイCEO。今後、Googleの様々なサービスに統合される予定
今回は、Googleが生成AIで直面するイノベーションの速度の課題と、OpenAIのサム・アルトマンCEOがAIへのレギュレーション(規制)をするための専門機関の必要性を訴える動きを中心に紹介します。生成AIは、官民を巻き込んだ国際レベルへの問題へと発展しつつあります。
「Googleはオープン化すべき」との内部文書
まず、5月10日にGoogle I/Oが開催されました。正直やっぱりインパクトが弱いなぁと思ったのは、すでにマイクロソフトがOfficeに生成AIを統合するとアナウンスしていたことと、検索エンジンの強化に力点が置かれて発表されていたからですね。技術的には順当な成長だと思うんですが、勝手なことを言うとワクワクしなかった。グーグルも競争のまっただなかなので、なんとも言えないところではあると思うんですが。
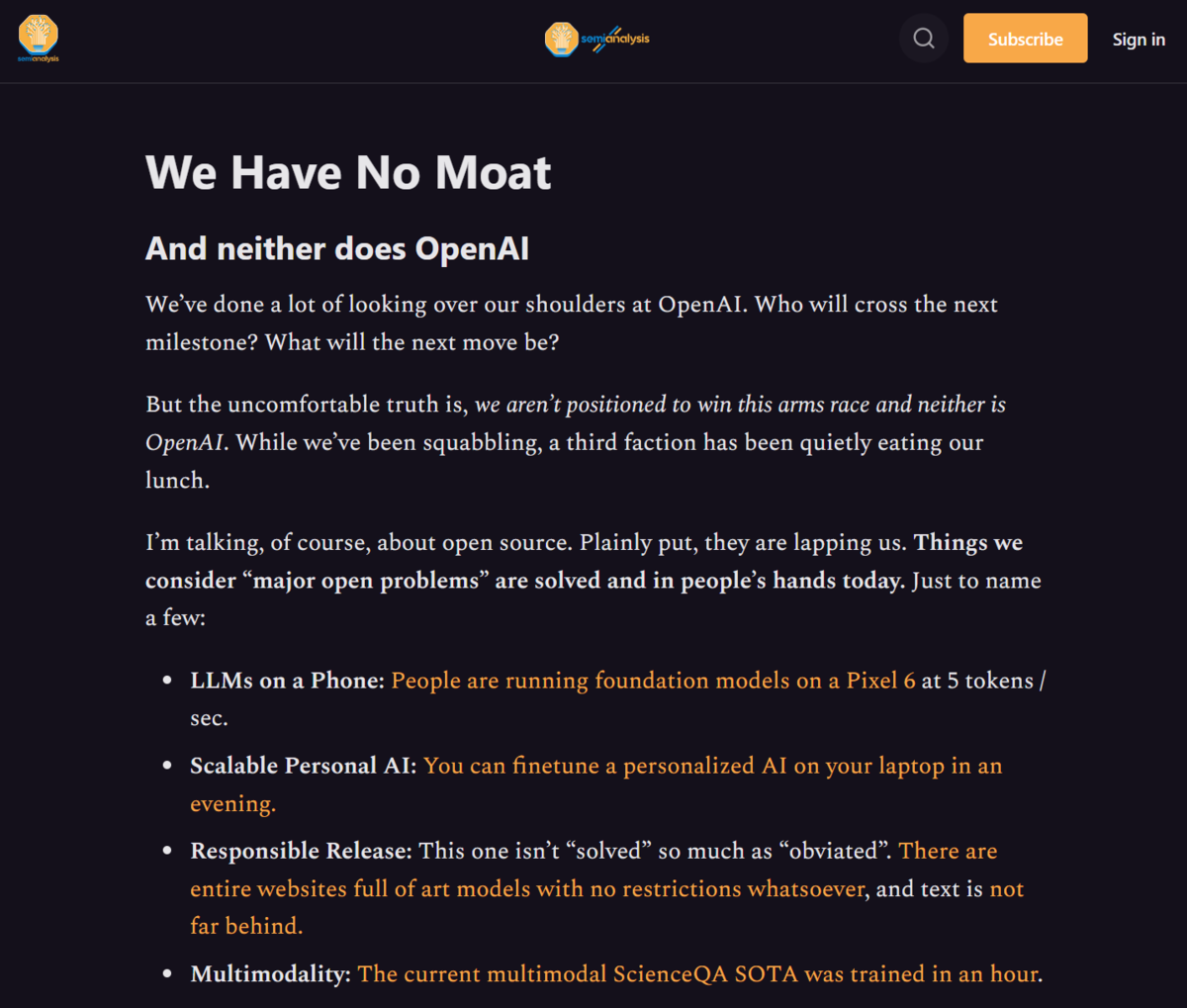
半導体向け業界情報を掲載するニュースメディアSemiAnalysisに掲載されたリークされたとするテキスト
Google I/Oと前後して、5月4日にグーグルのAI研究者により作成されたとされる内部文書も話題になりました。「私たちには堀がない、OpenAIにもない(We Have No Moat, And Neither Does OpenAI)」というタイトルの文書です。技術を秘密にしてイノベーションの優位性を確保するという今のグーグルのやり方ではうまくいかないんじゃないか、それは先んじているOpenAIでさえ同様なのではないか、と書かれたものです。
3月上旬にメタが開発した大規模言語モデル「LLaMa」がリークされたことをきっかけに、そのコードを土台として、オープンコミュニティで非常に様々な実験が始まっています。性能としてはまだOpenAIで言えば「GPT-3」相当だと言われていますが、それでも色々な派生技術が出てきている。たとえば、スマートフォンのPixel 6で動作させる人が出たり、ノートPCで一晩学習させるだけで個人用にカスタマイズしたり、Googleが開発していた技術にわずか数週間で肉薄してきているというのですね。
文書では「新しいアイデアの多くは、一般人から生まれています。トレーニングや実験への参入障壁は、大手研究機関の総生産量から、一人の人間、一晩、そして頑丈なノートパソコンに低下したのです」と述べています。リークをきっかけに、大規模言語モデルはオープンモデルへと否応なしに移行しました。大手企業は無料で使えるものと競合しながら、どうやって付加価値をつけるかを再考させられることになります。
画像生成AIの「Stable Diffusion」も、Stablity AIがオープンソースとして公開したことをきっかけとして加速度的なイノベーションが始まりました。この文書では画像生成AIと同じく大規模モデルで一定の学習をさせたものが出てくれば、そこから先はオープンソースで出した方がイノベーションは速くなるとしています。「オープンソースと直接競合するのは負け組」とまで述べてオープン化を促しています。
この話に関連して、Google I/Oの発表についていまひとつだなと感じてしまったのは、「今夏」「年内」といった発表が多く、今この瞬間に何ができるのかがわかりにくかったことでした。
基本的にGAFAMが春先に開くカンファレンスでの発表は期待値を上げるためのプレゼンテーションとして慣習化しており、1年単位でのアップデートを見るものでした。しかしインターネットを通じてリアルタイムで数多くのユーザーによってアップデートが進んでいく生成AIの世界では、毎日のように変化が起きるようになっているため、求められるスピード感が変わりつつあるとも感じてしまいました。
なお、件の内部文書が作成されたのは3月末から4月頭だと推測されますが、その後、ChatGPTの90%の性能に匹敵するという「Vicuna-13B」や、Stability AIの「StableLM」といったオープンソースの大規模言語モデルなどが相次いで発表され、開発者を自陣営にいかに引きつけるかという争いに変わってきています。
Googleはまだ新しい市場環境に適応する戦略をうまく打ち出せていないと言えます。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります