




要約AI「ELYZA DIGEST」
東京大学松尾研発・AIスタートアップ、ELYZA(イライザ)は8月26日、日本語における生成型要約モデルの開発に成功したと発表。同日より、本モデルを用いた要約AI「ELYZA DIGEST」(イライザ ダイジェスト)をデモサイトとして一般公開した。
ELYZA DIGESTは、入力したテキストデータを3行に要約するAI。大規模言語モデルを用いた「生成型」の要約モデルであり、読み込んだテキストを元にAIが一から要約文を生成する。書籍・小説・ニュース記事のような誤字脱字の少ない綺麗な文章だけでなく、議事録・対話テキストのような乱雑な文章・文字列であっても対応可能としている。テキストの直接入力以外にもURLを張り付けることで該当ページ内の全テキストから要約文を作成できる。
本AIモデルは、NLP(自然言語処理)の最先端技術を活用し開発され、医療におけるカルテ入力、弁護士業務における契約書類や判例の読解、コールセンターにおけるオペレーターの対話メモ作成、メディアにおける記事の原稿作成など、あらゆるホワイトカラー業務で発生する議事録づくりなど多数のユースケースでの活用を想定されている。
ELYZAでは、「対話テキストの要約」の実用化にも挑戦。ニュース記事と比較し、対話テキストの要約は主に下記の4つの要因から難易度が高いとされる。
1 口語のため、文の構造が大きく崩れていることが多い
2 音声認識の失敗による誤字脱字の存在
3 話者が複数存在
4 対話トピックが多様
AIを用いた要約には従来から複数のアプローチがあるが、対話テキストの要約において、文中から一部を抜き出す「抽出型」や「圧縮型」、もともと用意したテンプレートの一部を置き換える「テンプレート型」では、上記の要因が障壁となり精度の高い要約は難しいという。一方で、ELYZA DIGESTで採用している「生成型」のアプローチでは、一から柔軟に要約文を生成できるため、これらの課題を解決できる可能性がある。
下図は実際にELYZA DIGESTを用いて対話テキストを要約した例で、口語特有の「あのー」「えーと」などの間投詞や、音声認識のミスがあっても、妥当な要約文を生成できていることがわかる。

煩雑で難易度が高い「対話テキストの要約」に挑戦
さらに同社は、ELYZA DIGESTによる要約の精度評価を行なうために、人間が作成した要約文との比較検証を実施した。
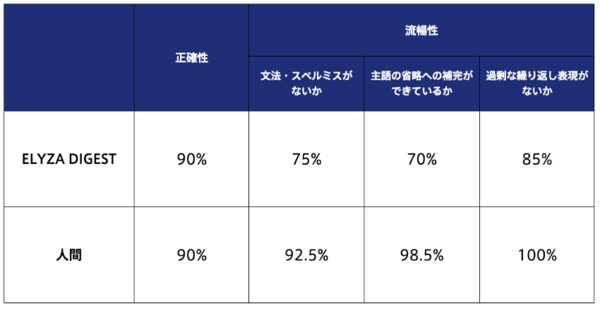
ニュース記事について、ELYZA DIGESTと人間の要約文を比較した結果。数値は対象のニュース記事のうち、各評価項目に対して問題ない要約文を作成できた割合(%)を表す
「正確性」の観点では、ELYZA DIGESTは全体の90%の記事に対して問題ない出力ができており、人間に匹敵する精度で要約文を生成できているという結果となった。一方、「流暢性」の観点では、人間の要約と比べると何らかのミスがある出力をする割合が多い結果となった。その内訳としては、いわゆる文法のミスに加え、日本語によくある原文での主語の省略に対して、要約文で適切な主語を補完できていないことにより、文が少し読みにくくなっているような箇所が見受けられた。これらの点については、改善が必要としている。
また、要約の効率性については、今回の検証で用いた記事は平均900字程度だったが、ELYZA DIGESTでは1記事あたり10秒以下で要約できる一方、人間の場合は5分程度の時間を要した。このことから、精度が十分であれば、要約AIを活用することで大幅な業務の効率化が期待できるという。
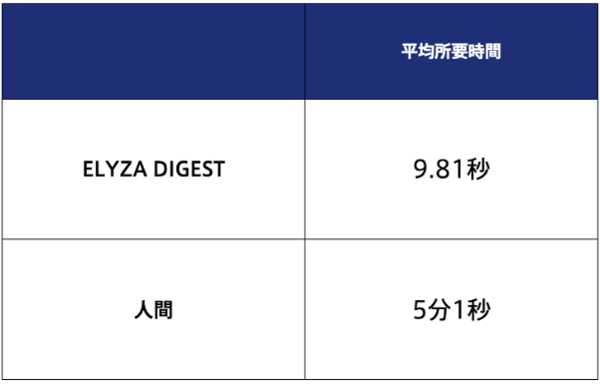
要約の所要時間の比較
同社は、「対話テキストの要約」を実用化するための第一歩として、SOMPOホールディングスと提携し、グループ会社の損害保険ジャパンのカスタマーセンターにおける対話要約の作成業務を支援し、音声認識後の対話テキストから要約するAIの開発に取り組んでいる。
「ASCII STARTUPウィークリーレビュー」配信のご案内

ASCII STARTUPでは、「ASCII STARTUPウィークリーレビュー」と題したメールマガジンにて、国内最先端のスタートアップ情報、イベントレポート、関連するエコシステム識者などの取材成果を毎週月曜に配信しています。興味がある方は、以下の登録フォームボタンをクリックいただき、メールアドレスの設定をお願いいたします。

週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります