



2019年1月21日、システムモニタリングのクラウドサービスを提供するDatadogは初のユーザーイベントを開催した。冒頭の「はじめてのDatadog」では、Datadogの概要やメリットはもちろん、モニタリングの必要性や分析のコツなども説明され、初心者にもわかりやすい内容となっていた。
モニタリングも“モダン”にならなければいけない
100名を超える参加者が集まったイベントの冒頭、「はじめてのDatadog」というタイトルで冒頭のセッションを担当したのは、セールスエンジニアの池山邦彦氏。昨年末に入社したばかりの池山氏は、「入社のテストでいろいろな機能を触ってみたら、メトリクスを見るだけではなく、思ったより奥が深いと感じた。これを拡げていきたいと思ってDatadogに入社した」と入社の経緯を語る。もちろん「犬のロゴがかわいかった」というのも大きかったが、「入社したら意外と猫派が多い」という感じだったという。

Datadog Sales Engineer 池山邦彦氏
2010年にニューヨークで創業されたDatadogだが、創業者2人はもともと教育関連のソフトウェアを手がけるエンジニアとして、システムの管理運用を担当してきた。そんな彼らが「チームごとに違うモニタリングツールを使うのが非効率だと思い、誰でも使えて、みんなが同じビューを見られるツールを作ろう」と考え、生まれたのがDatadogだ。ちなみに彼らはモニタリングしていたサーバーにDogを付けて呼んでいたが、そのうちパフォーマンスの劣化が多かったDBサーバーがDatadogと名付けられ、その名前がそのまま社名になったという。
Datadogはパフォーマンスを監視したり、アラートを上げたり、履歴を分析するモニタリングのSaaS。「とにかく簡単に使え、教育コストがかからないのが大きな売り」(池山氏)。メトリクス収集のイメージが強いが、APM(Application Performance Monitoring)やログの可視化の機能も持っている。なにが起こっているかをメトリクスでつかみ、アプリケーションの中身をAPMのトレースで踏み込み、なぜ起こったのかをログで調べる。こうした監視に必要な機能を単一プラットフォームで実現するのがDatadogの真骨頂だ。

システム可視性におけるメトリクス、トレース、ログの三本柱
時代とともに変化するシステムの監視をすぐに始められる
Datadogは変化を続けるIT業界のトレンドをいち早くフォローアップするところが大きな売りだ。監視やモニタリングのツールは長い歴史を持っているが、今では大手ベンダーの製品のみならず、オープンソースやクラウド型の製品も増えている。監視対象のユニットも物理マシンから仮想マシンへ、そしてコンテナやファンクションへとどんどん変わっている。開発サイクルもウォーターフォール型からアジャイル型やDevOps化が進んでいる。「IBMやCA、Zabbix、Nagiosなど数多くのツール・サービスがある中、モニタリングもモダンにならなければならない。Datadogを使えば、分散化・マイクロサービス化する時代でも、クラウドやコンテナの監視も容易に行なえる」と池山氏はアピールする。
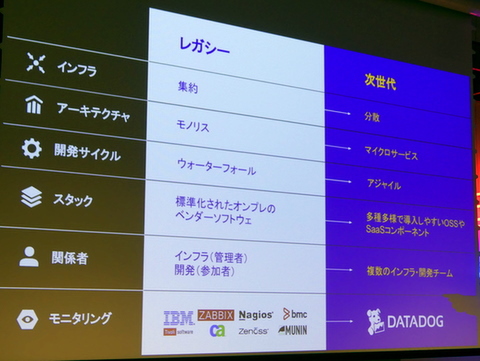
モニタリングも次世代へと進化すべき
続いて池山氏は、改めてモニタリングがなぜ必要かを説く。たとえば、サービスダウンによる機会損失。「100%のSLAを目指すことが正しいとは思えないが、約1億円/時間のECサービスの場合、3時間のダウンでサラリーマンの生涯年収を上回る機会損失に至ってしまう」と池山氏は指摘する。もちろん、システムダウンは避け得ないものではあるので、障害からいち早く復旧し、機会損失のリスクを最小限に抑えるためにはモニタリングは欠かせないわけだ。
その点、Datadogで一番のメリットはセルフサービスで簡単に使えること。エージェントを導入すれば、250以上の「インテグレーション」と連携させることで、監視をすぐに始められる。「5時間かかってサービスを復旧させていたお客様は、Datadogをセットアップし、原因究明や復旧をたった1時間で実現させることができた」(池山氏)。こうした「ファーストタイムツーバリュー」が大きなポイントと言える。
クラウド時代のモニタリングは「サービス」にフォーカスせよ
モニタリングの必要性やDatadogのアピールを終えた池山氏は、クラウド時代のモニタリングについて「Cattle,not pets(ペットではなく、家畜)」というメッセージを挙げた。池山氏は、「ペットは一匹ごとに名前を付けたり、トリミングしたり、手をかけてケアするが、家畜の場合はそんなことはしない」というコメントし、サーバーや仮想マシンの運用・管理に手を尽くすのではなく、あくまでサービスとしての可用性や性能にフォーカスすべきと指摘した。

ペットではなく家畜
ここでの鍵がメトリクスに付与された「タグ」だ。Datadogはキーバリュー形式で1つのメトリックに複数のタグを付与できるので、このタグごとにグループ化やフィルタリングなどをかけられる。「たとえば、Webサーバー、DBサーバーなどの役割、インスタンスタイプやメモリなどのスペック、展開している地域やデータセンターなど、タグごとに多元的に見ることができる。これが何千台、何万台単位でサービスを見ていくために重要」という。
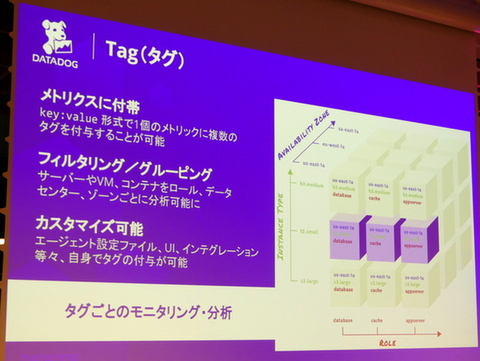
メトリクスに付与されたタグが鍵
では、なにから見ればよいか。まずはシンプルにスループット、成功/失敗、パフォーマンスなどの「ワークメトリクス」をチェックし、たとえばサービスレベルを決めていく。次に使用率、飽和度、失敗、可用性などの「リソースメトリクス」を見て、問題を特定していくという。
その他、システム変更やオートスケール、アラートなど重要な通知の「イベント」、アプリケーション内部に踏み込んだスループットやエラーを収集した「APM」、サービスを構成するコンポーネントの関連図を表した「サービスマップ」、さらにデバッグ情報やシステムの挙動を記録した「ログ」などもチェックできるので、適材適所でさまざまなデータを使い分けるとよいという。「ログそのものもエラーだけを漠然と見ていても、埋もれてしまう。そういったときにはエラーのパターンを機械学習でクラスタリングしてくれる。Datadogにログを入れれば、こうした分析もすぐに利用できる」(池山氏)。
導入から利用まで容易なDatadogの魅力をデモで披露
残り時間はデモ動画を披露しながら、導入のスムーズさをアピール。「エージェントをインストールするのも、UbuntuやDebian、Macなどプラットフォームを選択し、値をコピペするだけ。数十秒でエージェントがダウンロードされ、システムメトリックをDatadogに送ってくれ、可視化までやってくれる」(池上氏)。
また、nginxのメトリクスを見たいといった場合でも、インテグレーションを選択して、表示した値をコピペすればOK。タグの設定もYAMLファイルを編集すれば、エージェントを再起動すればよい。「アラートの追加やダッシュボードの作成もちょっとした操作でできるので、難しいコマンドや関数を書く必要がないのがDatadogのいいところ」(池上氏)。
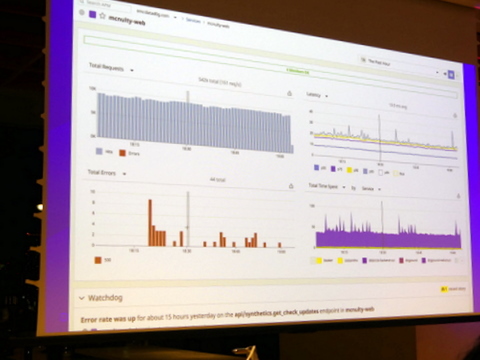
ダッシュボードで見やすいグラフを一覧表示
最後、池上氏は登壇予定のイベントやCTOの来日イベントについて説明。ユーザーの声を集めて、今後もミートアップを開催していきたいとアピールして、30分のセッションを終えた。後半のユーザー事例とLTの概要は、別稿でお届けする。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります