



NVIDIA GTCレポ:AI関連機能を大きく取り込んだVolta世代のアーキテクチャを発表
2017年05月12日 10時00分更新
NVIDIA社は、5月10日(現地時間)に米国で開催中のGTC(GPU Technology Conference)で基調講演を行なった。登壇した同社創設者兼CEOジェンスン・フアン(Jensen Huang)氏は、次世代GPUアーキテクチャ「Volta」を含む多数の発表を行なった。

GTCの基調講演に登壇したNVIDIAのCEOジェンスン・フアン(Jensen Huang)氏
計算能力の上昇が続くGPU
2025年には汎用プロセッサとの性能差は1000倍と予測
GTCでは例年、初日に基調講演が行なわれていたが、今回はその初日に決算発表があったため、製品発表などができなかった。そのため、5月10日に開催されることになった。
今回も多数の発表があったが、中心となるのは、次世代のGPUアーキテクチャであるVoltaとその具体的な製品である「Tesla V100」、そしてこれらを搭載した「DGX Systems」や「HGX-1」である。DGXは従来ラックマウントを想定したDGX-1のみであったが、デスクトップ型のDGXステーションが追加されシリーズ化している。

今回の基調講演では多数の発表が行なわれた
Voltaアーキテクチャでは、AI処理を想定したTensor Coreを新たに搭載、4×4の行列計算(内積と積算)を高速に処理できる。前アーキテクチャのPascalでは、AIに対応といいながらも、半精度浮動小数点(FP16)処理による高速化など、どちらかというと“小手先”の対応でしかなかった。しかし今回のVoltaでは、AI、特にディープラーニング処理で行なわれる行列演算を高速化できる。
ジェンスンCEOは、最初にスタンフォード大学のジョン・L・ヘネシー博士が今年3月に日本で行なった講演「The End of Road for General Purpose Processors and the Future of Computing」(以下の動画)を引き合いに出し、汎用プロセッサの成長は限界に近づきつつあるとした。かつては1.5倍/年で成長していた汎用CPUの性能は最近では、1.1倍/年にまで落ちているという。
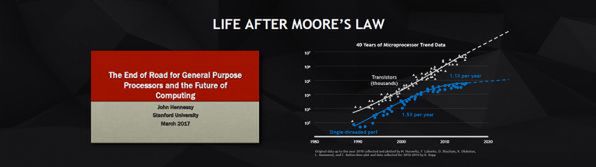
プロセッサ設計の教科書として著名な「コンピュータアーキテクチャ 定量的アプローチ」(ヘネシー、パターソン著。通称ヘネパタ)、「コンピュータの構成と設計」(パターソン、ヘネシー著。通称パタヘネ)の著者ジョン・L・ヘネシー博士の日本での講演から
これに対して、GPUの計算能力は1.5倍/年を維持しており、2025年には、汎用プロセッサとの差は1000倍になるとした。このあたりは、多分にインテルを意識した話である。
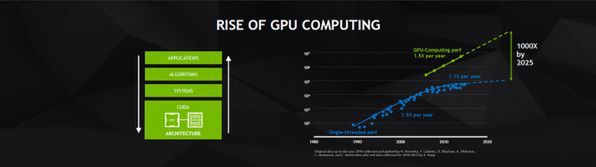
汎用CPUに対してGPUの性能向上は、1.5倍/年を維持しているという
ディープランニングに最適化した
VoltaアーキテクチャのGPU「Tesla V100」
さて、最初の発表は、「Project HOLODECK」である。これは、写真クオリティのコンピュータグラフィックスと物理シミュレーションが可能なネットワークによる共同作業環境だ。たとえば、CADデータを元に自動車の高精度なCGなどを使って仮想世界での共同作業ができるもので、EPIC GamesのUnreal Engine上に作られている。なお、HOLODECKとは新スタートレックに登場する仮想世界を作り出せるエンタープライズ号船内の施設のことだ。


写真クオリティのグラフィックスと物理シミュレーションのある仮想環境での共同作業が可能になるProject HOLODECK
話は、ディープラーニングに移る。最近のAIでは、さまざまな試みが行なわれており、その例として、レイトレーシングCG技術にディープラーニングを応用し、画像のリアリティを上げるというものや動画から企業名やロゴを検出して、ブランドのインパクトを測定するなどの応用(SAP社が開発し、DGX-1が使われているという)を紹介した。
そして、さまざまなディープラーニング技術が開発されるにつれて、そのネットワークモデルは複雑化し、さらに強力な学習や推測のためのエンジンが求められているとした。

2015年のResNetでは6000万パラメーターだったが、2017年のMNTでは87億パラメーターとなりそれにつれて必要な処理性能も大きくなってきた
そこで発表されたのが、VoltaアーキテクチャのGPUであるTesla V100だ。科学技術計算用GPUであるTeslaシリーズには、NVLinkを持つIBM Powerプロセッサと接続するNVLink版とインテルPCなどで利用するPCI Express版があるが、今回NVIDIAがディープラーニングの学習用として発表したのはNVLink版のTesla V100である。

まず発表されたのはNVLink版のTesla V100。新しいVoltaアーキテクチャのGPUで、ディープラーニング用のTensor Coreを搭載する
最大の特徴は、4×4の行列の内積を求め、前回の結果と加算する処理を1命令で処理できる「Tensor Core」をGPU内部のSM(Streaming Multi-Processor)に組み込んだこと。1つのSMで処理可能なスレッドの制御単位であるWARP(32スレッド)で16×16の行列の内積と積算ができる。
著名なディープラーニング用フレームワークであるCaffe2、マイクロソフトのCognitive Toolkit、mxnetが対応するという。

ディープラーニングフレームワークであるCaffe2、Cognitive Toolkit、mxnetがVoltaアーキテクチャ向けに対応するという
さらに、このTesla V100を搭載したDGX-1(発表と同時に受注開始。8×Tesla V100+2×Xeon E5-2698で、14万9000ドル)とデスクトップ型のDGXステーション(4×Tesla V100+Xeon E5-2698で、6万9000ドル)を発表した。

Tesla V100を8個搭載したDGX-1。すでに受注可能。14万9000ドル

同じくTesla V100を4個搭載したパーソナルDGXことDGXステーションも登場
また、同じくTesla V100を使うクラウド向け(データセンター向け)の製品としてHGX-1とPCI Express版Tesla V100も発表した。

クラウドサービス向けのデータセンター用HGX-1も発表された。最大2CPU、8GPUを含む3つの構成がある

PCI Express版Tesla V100は、クラウド向けの推論エンジンという位置付け
PCI Express版Tesla V100は、クラウド向けの推論エンジンという位置付けで、インテルのSkylakeプロセッサの15~25倍の推論性能を実現可能だという。こちらはフルハイトハーフレングス(FHHL)のPCI Expressカードサイズ。これに合わせ、NVIDIAのTenserRT(推論オプティマイザー。学習済みのニューラルネットワークから推論用に最適化されたランタイムを作成する)をGoogleのTensor Flowに対応させた。
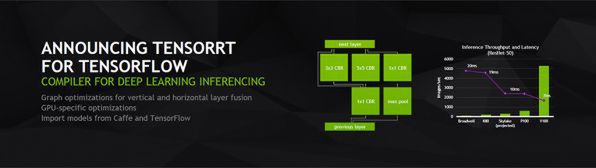
ディープラーニングの推論オプティマイザーTensorRTも強化され、GoogleのTensor Flowの学習済みモデルに対応した
AI関連の発表の最後は、NVIDIA GPU Cloud。クラウドベースの機械学習プラットフォームで、ユーザーはNVIDIAが常にメンテナンスしているNVDockerコンテナーを使ってシステムをクラウド上に作ることができる。こちらは7月からβテストが開始される予定としている。

ハードウェアを用意しなくてもクラウドベースでディープラーニングシステムが構築できるNVIDIA GPUクラウド。主要なディープラーニングフレームワークに対応している
トヨタ自動車との提携も発表
AIに舵を切ったNVIDIA、その成果がハッキリ見えてきた
次にNVIDIAは、トヨタとの提携を発表。トヨタは、NVIDIAのDrive PXを搭載した市販予定の自動運転車を開発中だという。あっさりとした発表だが、インパクトは大きい。また、Drive PX Xavierに搭載されているディープラーニングアクセラレーター(DLA)をオープンソース化することも発表した。

トヨタとNVIDIAは提携し、Drive PXを使い市販予定の自動運転車を開発中であることを発表
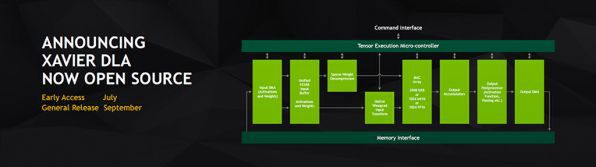
Drive PX Xavierに搭載されているDLA(Deep Learning Acceralator)をオープンソース化すると発表した
Drive PX Xavierには、エネルギー効率が高いディープラーニング用ハードウェアを搭載。Volta GPUよりも高効率なのだという。7月から特定ユーザー向けの早期アクセスを開始。9月に一般リリースをする。DLAはハードウェアなので、その設計自体をオープンにしてどのメーカーでも利用できるようにするのか、あるいはDLAのためのソフトウェアをオープンソースにして、ユーザー自身のディープラーニングシステムを移植しやすくするのかがちょっと不明ではあった。
最後にジェンスンCEOが発表したのは、ロボット開発のシミュレーターISSAC。
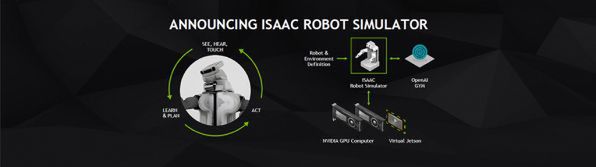
仮想環境でロボットを開発できるロボットシミュレーターISACC。ソフトウェア開発だけでハードウェアを作らずにロボット開発ができる
ロボット自体は仮想化されたJetsonボードで制御され、NVIDIA GPUを持つ環境でエミレーションを行ない、仮想世界の中でロボットを開発、テストすることができる。
2015年のGTCでAIに大きく舵を切ったNVIDIAだが。Voltaアーキテクチャでは、大きくAI関連機能を取り込んだ。通常GPUクラスの大規模な半導体では、3年ほどの開発期間がかかると言われている。おそらく2015年のGTC以前の段階でAIに対応することを決断したのだと思われる。2014年ではまだ、AIに完全にコミットという感じではなかったため、その間に転換したのだろう。このあたりの決断の速さがNVIDIAの強みと言えそうだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります