



AIは世界を変えると確信してきた
自然言語処理や知識情報処理の第一任者でもある黒橋所長は、「長年の研究を通じて、AIは世界を変えると確信してきた。いまの生成AIの能力は、米国の司法試験では上位10%の水準に到達するなど、準専門家レベルのレベルに達している」と指摘する一方で、「生成AIでは、中でなにが起こっているのかが、自然言語の研究者でもわからない状況にある。大規模言語モデルの高機能性や汎用性、ハルシネーションなどの原因解明が必要である。生成系AIの仕組みを明らかにして、社会が安心して利活用できるようにすることが重要である」と語った。
さらに、「大規模言語モデルの研究開発が一部の組織の寡占状態となっており、健全な環境とはいえない」と指摘。「完全にオープンで、商用利用が可能なモデルを継続的に構築し、大規模言語モデルの原理解明や多分野展開などの研究開発を進めることが必要である」とも述べる。
また、日本語の情報を十分にカバーし、使用のルールや入力情報の機密性が明確にコントロールできる生成AIが必要であることを訴え、「日本語を十分に理解した生成AIの存在は、日本の企業におけるビジネス利用での効果が見込まめるだけでなく、経済安全保障の観点からも必須になってくる」と指摘する。
こうした課題に取り組むのが、2023年5月に発足したLLM勉強会だ。
NIIの黒橋所長は、この組織をリードする役割を担っている。
LLM勉強会には、自然言語処理および関連分野の約250人の産学の研究者が参加。オープンで、日本語に強い大規模言語モデルを構築し、原理解明に取り組む計画だ。
具体的には、2023年秋には130億パラメータの大規模言語モデルを構築するとともに、2023年度中には、1750億パラメータの大規模言語モデルを構築する予定だ。また、活動を通じて得られたモデルやデータ、ツール、技術資料などの成果物は、議論の過程や失敗事例を含めて、すべて公開するという。
「大規模言語モデルの研究開発は日進月歩だが、現状では、GPT-3と同等の1750億パラメータを持つモデルにおいて、創発が起こるとされている。日本においても、このスケールのモデルを構築し、原理解明に取り組む体制を作ることが必要である」とする。
また、LLM勉強会では、大規模言語モデルに関する技術課題として、学習原理の数理的解明(創発や汎用性がどのように学習されるか)や効率性(データ/モデル効率,グリーン)をあげているほか、大規模言語モデルに関する社会課題として、説明性・解釈性(ブラックボックス問題)、公平性(バイアス問題)、安全性(誤情報・ハルシネーション、個人情報、著作権問題、コンプライアンス)、信頼性(どう保証するか)をあげ、大規模言語モデルの多分野展開として、医療や法律、教育などへの展開、マルチモーダル情報やロボット制御などとの結合をあげている。
「大規模言語モデルの研究におけるスピード感を考えると、研究開発プログラムのトップダウンな設計は必ずしも最適ではなく、最も重要なことは土壌を作ることである。計算基盤と言語モデル構築基盤を整備し、国内外の研究者が様々な試行錯誤を行う環境を構築することが大切である」とする。こうした課題感をもとに、LLM勉強会では、大規模言語モデルの構築を急ぐことになる。
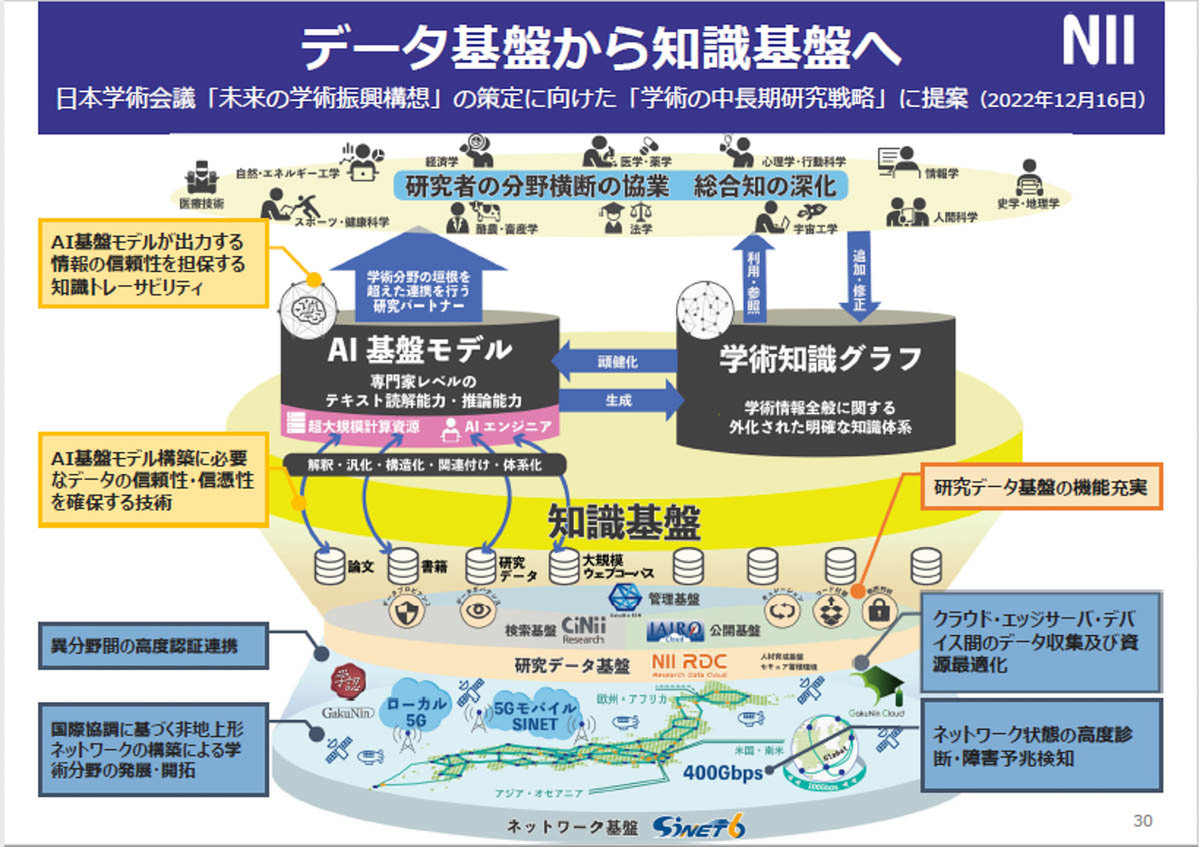
NIIの知識基盤づくりにも、LLM勉強会の取り組みは重要な意味を持つ。そして、この取り組みが、日本の社会課題の解決につながることになるのは明らかだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります