



第869回
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度
2026年03月30日 12時00分更新
Meta、Alibaba、AMDとの比較で見えたIntelの独自性
Foveros Direct 3Dが可能にする演算とメモリーの極限接近とその価値
下の画像が過去のHybrid Bondingを実装した論文との比較である。
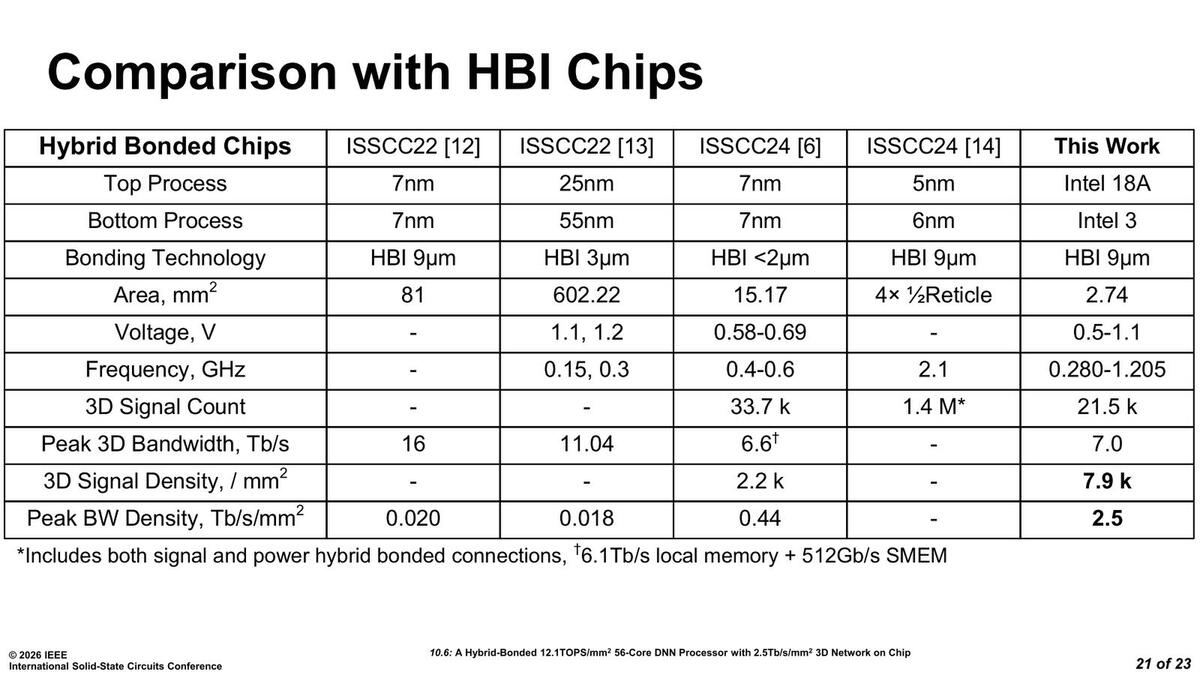
Hybrid Bondingを実装した論文との比較。あとは最先端プロセスを利用しての3D実装が可能になった、という点もアピールポイントかもしれない
ここでISSCC22の[12]というのはAMDの3D V-Cacheのインプリメント、ISSCC[23]はAlibabaの3D LogicとDRAMを積層したという論文、ISSCC[24]はMetaによるAR向けのアプリケーションプロセッサーの3D積層の論文、ISSCC[14]はAMDのInstinct MI300シリーズの実装に関する論文をそれぞれ指しており、なんというか単純な比較は難しいのだが、3D方向の配線密度はここに挙げられた現時点の実装に比べるとずっと高いことをアピールしている。同様にDNN PEの性能を比較したのが下の画像である。
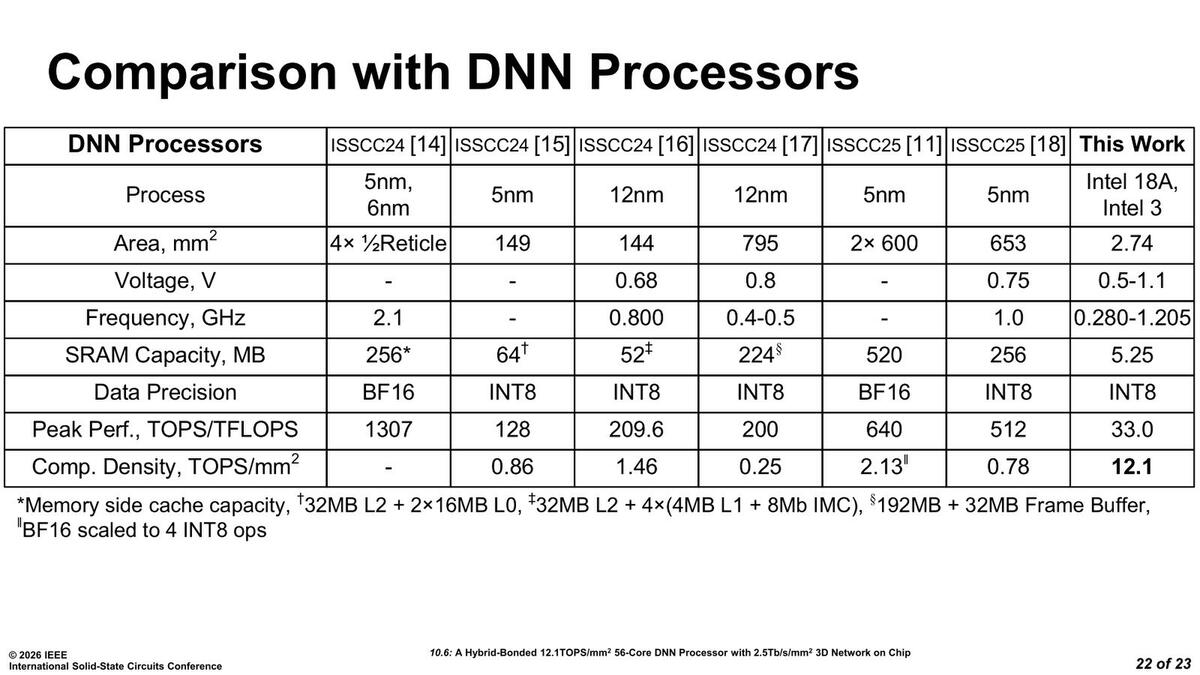
DNN PEの性能比較。ただこれ、SRAMがコアあたり96KBと小さいからこその数字であり、もっと広範なアプリケーション向けにSRAM容量を増やしたりすると下がりそうな気がする
ISSCC24[14]は上述のAMD Instinct MI300、ISSCC24[15]は韓国Rebellionsの5nmプロセスで製造されたML SoCの論文、ISSCC24[16]は蘭Axelera AIによる12nmで15TOPS/W、209.6TOPSの性能を出すEdge向けAI SoCの論文、ISSCC24[17]はIBMのNorthPoleという12nmプロセスのAIチップの論文、ISSCC25[11]はSambaNovaのSN40Lの実装、そしてISSCC25[18]は韓国FuriosaAIによるRNGDという5nmのLLM向けプロセッサーの論文である。
なんというかハイエンドからローエンドまでよりどりみどりという感じで一律に比較するのは難しいが、一応インテル的にはCompute Unitの演算密度(単位面積あたりの演算性能)では他を圧倒する、と主張している。
今回は純粋に研究目的での発表であって、これを商用化向けに考えるといろいろと困難が待ち受けているので設計の見直しは必要だろうが、3D実装にしたPIMに可能性があると示した(副次的に、Foveros Direct 3Dの性能の高さを立証した)ことでは、意味のある発表だと思われる。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります