



32GT/sの信号速度と驚異の冗長設計
Rebel100のUCIe実装に見る「壊れても動く」信頼性
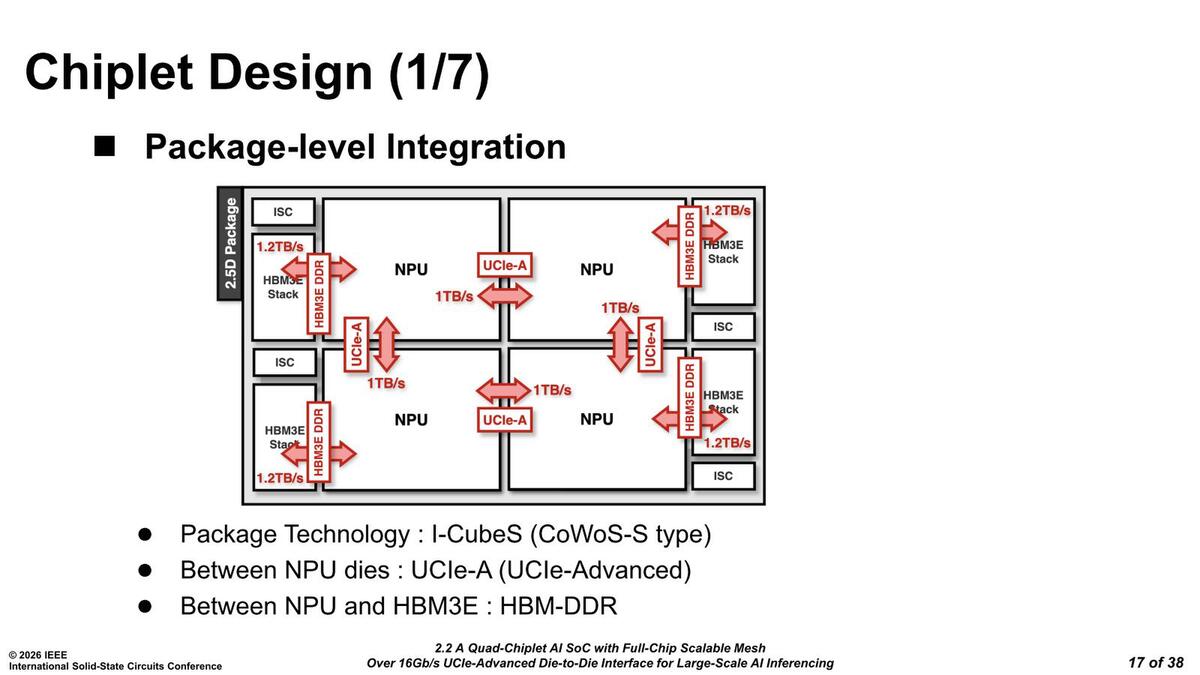
次にチップレットレベルの話。UCIe-A I/Fはいずれも1TB/秒の帯域を持つ。信号速度が32GT/秒と仮定すると256本ほどの配線になる計算だ。UCIeのアドバンスド・パッケージはx64で1つの塊なので、これを4組搭載する構成と考えられる。
これが動作しているということは、I-CubeSはUCIeのアドバンスド・パッケージを問題なく実装できると証明したとしてもいいのだろう
ちなみにアドバンスド・パッケージの場合の配線密度は1317GB/秒/mmなので、UCIeのI/Fの幅は1mmに満たないことになる。これがスタンダード・パッケージでは224GB/秒/mmほどなので、5mm弱の幅を取ることになり、Rebel100のサイズがもう少し大型化することは避けられなかっただろう。HBM3Eとは1.2TB/秒での接続である。
ただUCIeはあくまでも物理的(電気的)な接続方法の規定であって、その上に通すプロトコルへの規定はない。ではどんなプロトコルというか、なにを通しているのか? という話が下の画像である。
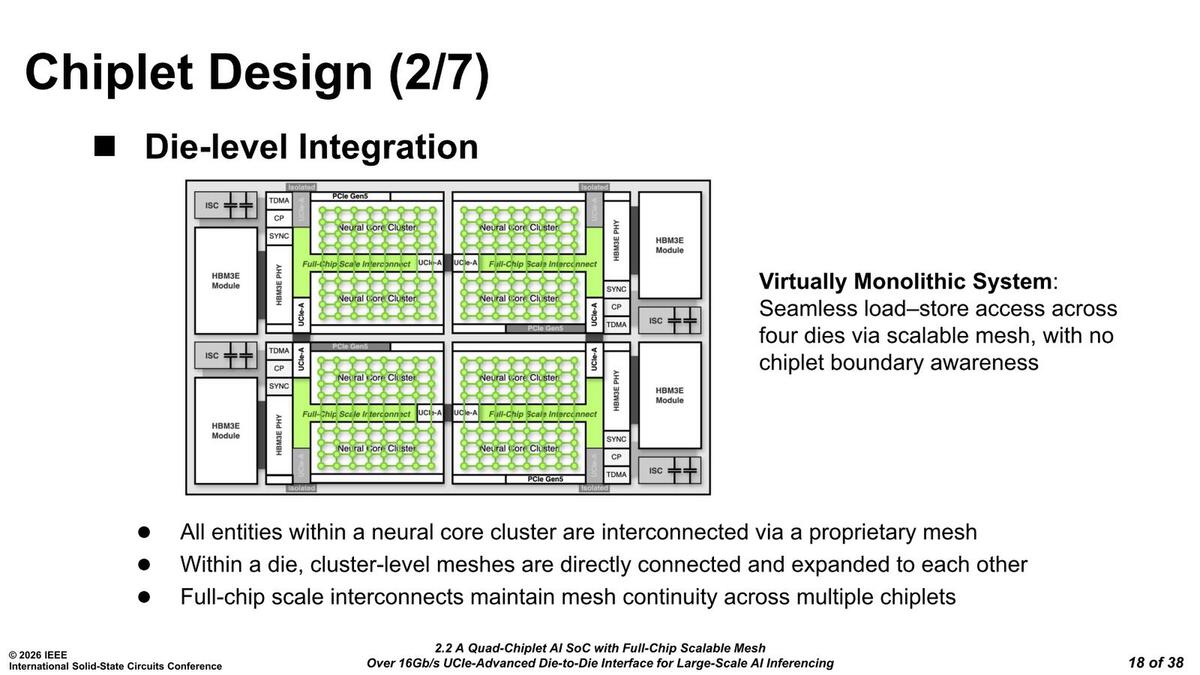
load-storeは4つのチップレットどこに対してもシームレスに行なえるとは書いてあるが、Load/Storeユニットが直接別のニューラルコアのスクラッチパッドにアクセスできるかどうかはまた別の話である。それが同一ダイ内か、別ダイかは問わない
そもそもRebel100内では、16個のニューラルコアに対して64個のメッシュストップが存在している。数が合わないように思えるが、32MBの共有メモリーにも複数のメッシュストップが配されている様子が後のスライドでも出てきている。
おそらく、32MBのスクラッチパッドは2MBずつのブロックになっており、ここにおのおのメッシュストップがあるのでこれだけで16個。それとは別にニューラルコアはスクラッチパッドとニューラルDMAにそれぞれ1個づつメッシュストップが設けられており、これが8コアで16個の合計32個で、これで1クラスター分という構成なのではないかと筆者は想像している。
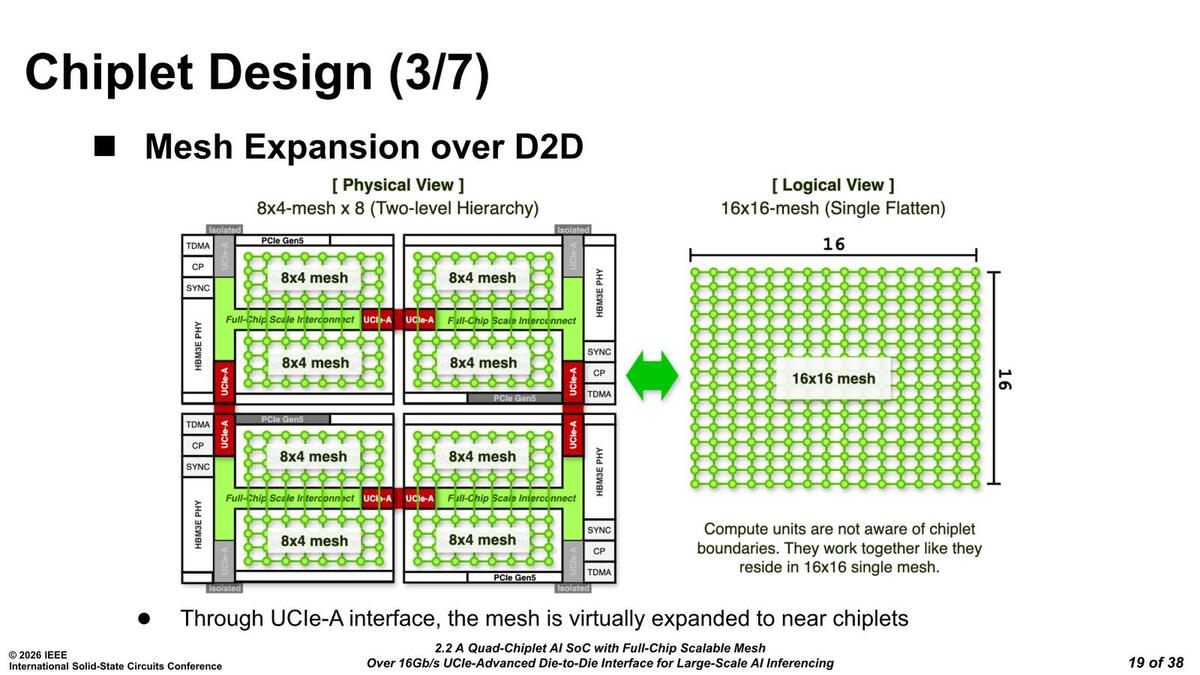
前にUCIeはおそらく256bit幅(64bit×4)と書いたが、縦横のメッシュの速度が32bit幅のUCIe(256GB/sec)相当だとすれば辻褄は合うし、レイテンシーは若干増えるだろうが、帯域的には問題ない計算になる
別の案では、32MBのスクラッチパッドは4MBのブロックになっており、これで8個のメッシュストップ。そしてニューラルコアの方はスクラッチパッドとニューラルDMA、それとLoad/Storeユニットにそれぞれ1つという可能性もある。
ただLoad/Storeユニットは、自身のコア内のスクラッチパッドに対してのアクセスのみを担当し、他のコア内のスクラッチパッドをアクセスする場合はニューラルDMAが動くような気がするので、ありそうなのは前者であるが、このあたりの詳細は明らかにされていない。
話をメッシュに戻すと、クラスターあたりでは8×4、チップレットあたりでは8×8のメッシュになるわけだが、仮想的には4つのチップレット全体をまとめた16×16のメッシュとして動作できるとする。というかプログラミングは、1つの16×16メッシュとして扱う形になっているようだ。
プログラムからするとメッシュの構造は完全に見えなくなっているようだ。メッシュストップ同士の接続は仮想的に専用レーンを構築してそこで転送できるほか、各クラスターの32MBのスクラッチパッドは、プログラム的には1つの256MBスクラッチパッドとして扱うこともできるらしい。
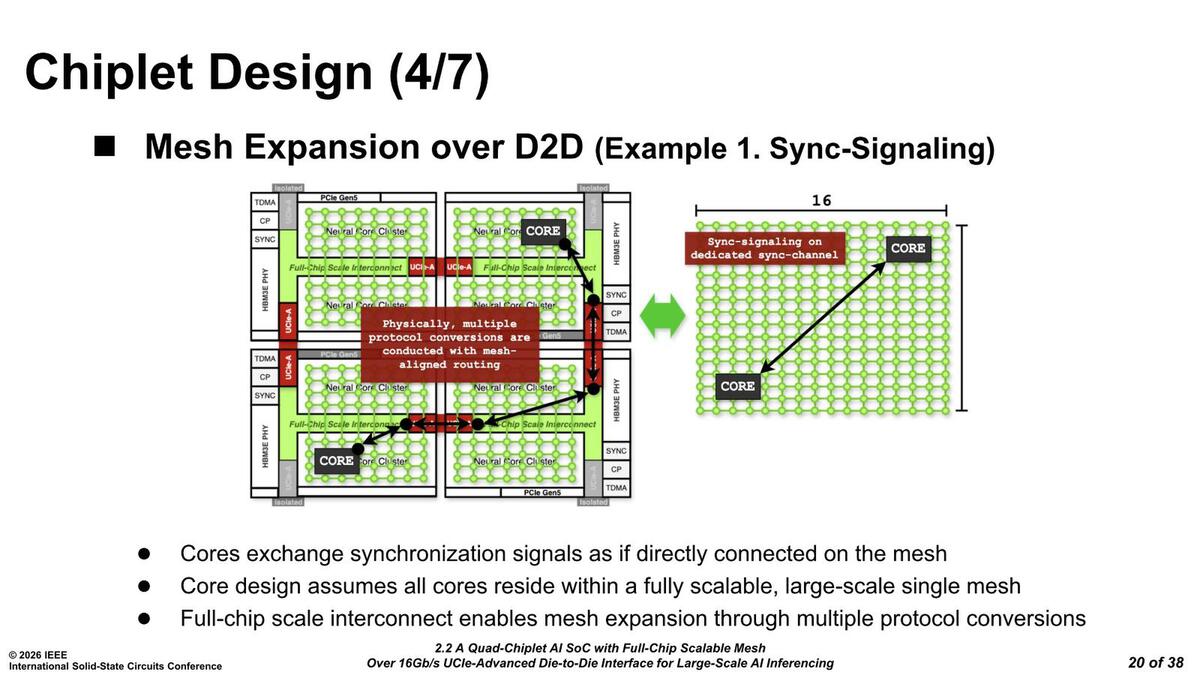
Multi Protocolというのがなにかであるが、単にデータ転送以外にSignal(相手への通知)なども送れるようで、データ転送以外に複数の通信をメッシュ上で載せられ、しかもVirtual Channel的に扱えるようになっている模様だ
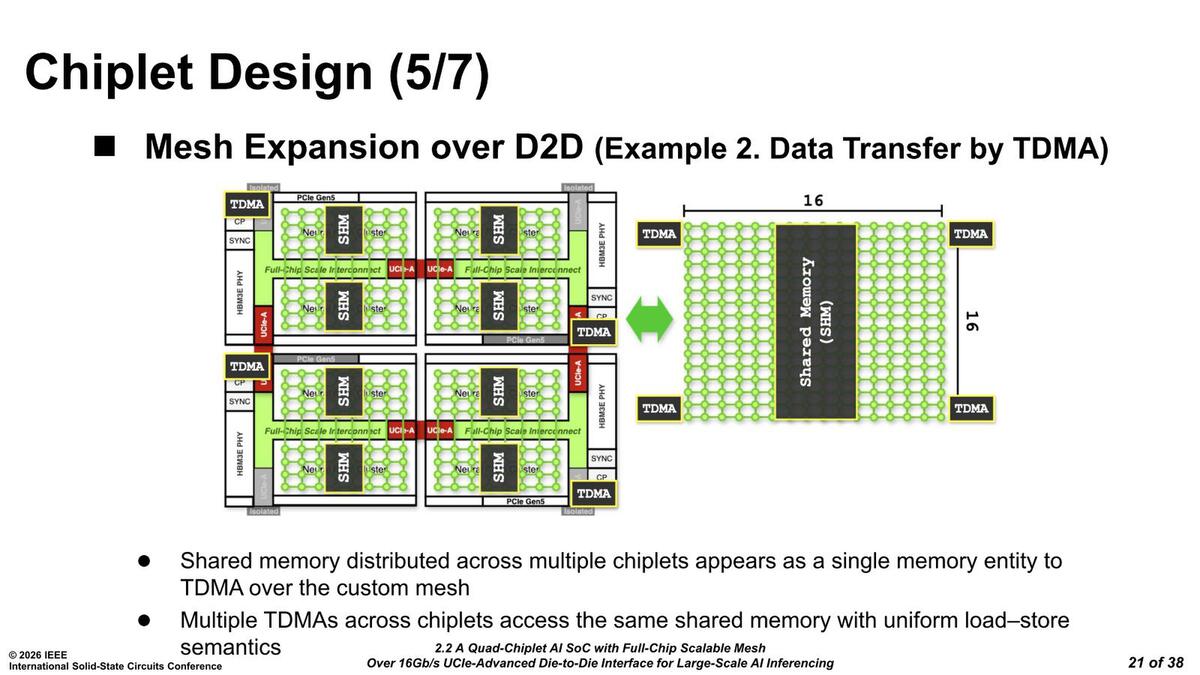
スクラッチパッドのハンドリングは各チップレット上のタスクDMAユニットが行なうとしている。おそらく個々のTDMAは、他のTDMAと相互に通信しながら、自身のチップレット内のスクラッチパッドの制御をしているのだろう
メッシュの制御は、それぞれのチップレット内のSyncマネージャーが相互接続して調整する形になっているという話であった。
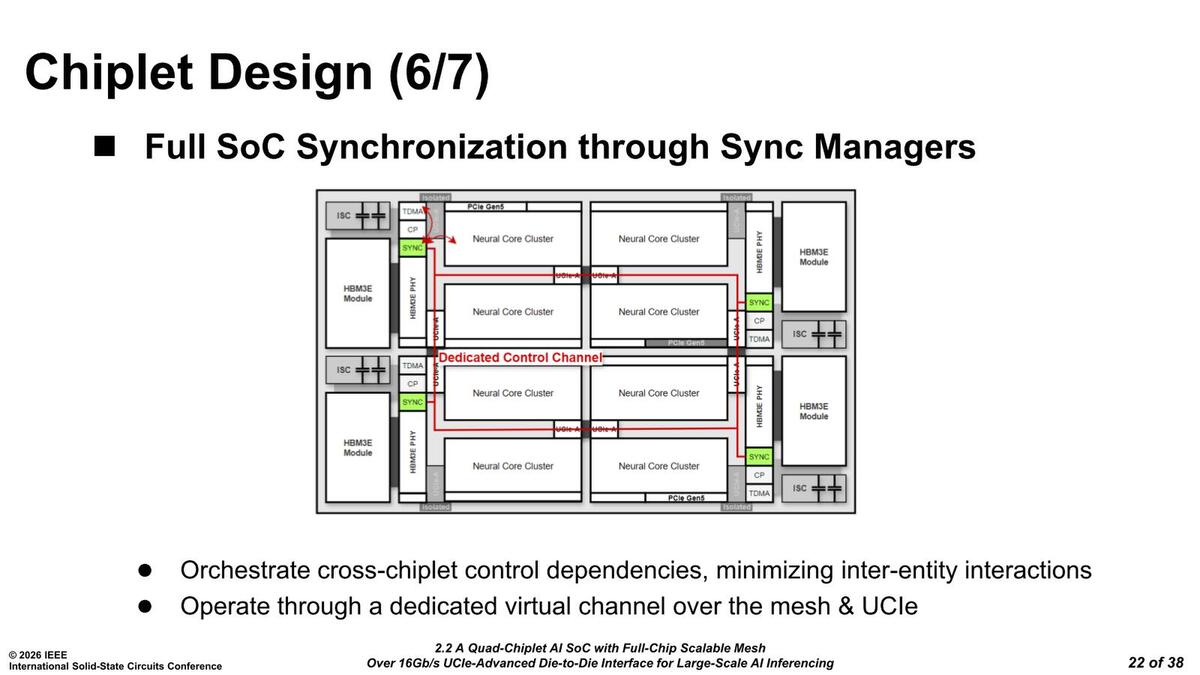
この表現だと、チップレット内部は専用配線が用意されており、ただしチップレットをまたぐところだけはUCIeを通るメッシュの信号に混載されるように見えるが、あるいはメッシュそのものにこれも別プロトコルとして重ねられている可能性もある
ところでUCIe周りでは不思議なスライドが示された。左側の話は冗長性に関する部分だ。
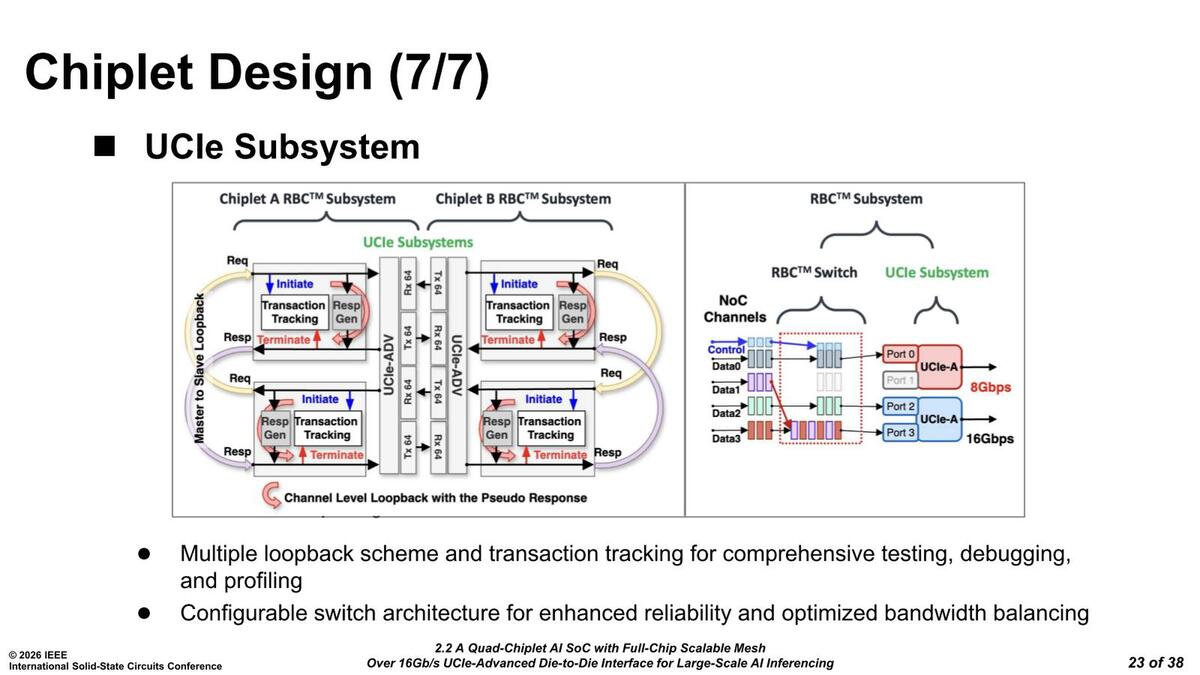
RBCは説明がどこにもない(論文の方にすらない)のだが、おそらくはRedundant Bump Circuitの略だろう。右側の動作を可能にするために、メッシュとUCIeの間にわざわざRBCスイッチを入れているわけだ
もともとUCIeのアドバンスド・パッケージの場合、冗長レーン(Redundant Lane)という考え方が当初から含まれている。製造時、あるいは稼働中に不具合が出た場合、その不具合のある配線を捨てて冗長レーンを利用するというものだが、このためにはまず正常に動作するかどうかを確認する必要がある。それが左側の図で、64bit幅の4chのI/F同士でループバック(対向試験)をすることで正常かどうかを検出するというものだ。
それはいいのだがおもしろいのは右側で、これはPort 1にあたる配線がエラーだった場合で、その場合はData 1の内容をPort 3に多重化させることで、伝送失敗を防ぐ仕組みである。問題はここでData 0~3がいずれも8Gbps相当になっていることだろう。要するにメッシュは4bit幅でそれぞれ8Gbpsの速度で信号が流れている、ということを示唆しているように思える。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります