



今回取り上げるのは韓国rebellionsのREBEL-QuadというAI向けチップである。rebellionsは韓国初のAIユニコーン半導体企業なのだそうで、2025年3月には東京にもrebellions Japanを設立している。
rebellionsは2022年にION、2024年にATOMと呼ばれるAIチップをそれぞれ開発しており、どちらも市場出荷されている。IONはTSMC N7で8.7×8.7mmというコンパクトなチップで、FP16で4TFlops、INT 8/4/2でそれぞれ16/32/64TOPSの演算性能を2~6Wという低い消費電力で実現する、エッジAI向け製品である。
チップ単体のほか、HFT(High Frequency Trading:高頻度金融取引)向けのPCIeカード(名称はLightTrader)や、そのPCIeカードを8枚搭載したAIアクセラレーターサーバーなども用意している。
続くAtomはもう少しデータセンター向けに性能を高めた製品で、演算性能はFP16で32TFlops、INT 8/4で128/256TOPSの性能を持つチップをGDDR6 16GB DRAMと組み合わせてPCIeカードの形で提供しており、これを複数枚搭載したATOM-Max Serverや、そのATOM-Max Serverを複数台構成としたATOM-Max PODをすでにラインナップしている。
第3世代「REBEL-Quad」
チップレット構造で実現するLLM特化型性能
今回発表されたREBEL-QuadはION/ATOMに続く第3世代製品であるのだが、おもしろいのはこの製品は名前の通りRebel100というチップを4つ、チップレットの形で組み合わせた構造なことだ。

手前がREBEL-Quad。これも奥に見えるPCIeカードの形での提供を考えているようだ
さてこのREBEL-Quadの目標は、LLMを実用的に利用できる性能を提供することで、実際にこれを実現できたとしている。

ISSCCではデモセッション(DS1)で動作デモが行なわれたらしいが、残念ながらこちらのビデオはないので確認はできない。とはいえLlama 3.3の70Bを56.1トークン/秒で動かせるというのはそれなりの結果である
その設計目標が下の画像である。言っていることはわりと真っ当な話であるが、問題はこれをどう実装するかという仕組みである。

メモリーアクセスと計算の両方が重要というのはその通りだが、後半の"Lopsided optimization is not a sustainable"というのは、要するにコンピュートとメモリー帯域のどちらかを優先する方式ではうまくいかず、バランスが重要としている

Sign-off、つまりテープアウトに至るまでの設計工程のコスト(初期コスト)とYield risk(歩留まりに起因する量産コストの高騰リスク)を考えると、大きなダイを製造するのは難しい

消費電力を抑えるのは、単に電気代を下げだけでなく、チップの安定動作にも関わる話である。これに関してREBEL-Quadはなかなかおもしろい取り組みをしているが、これは後述する
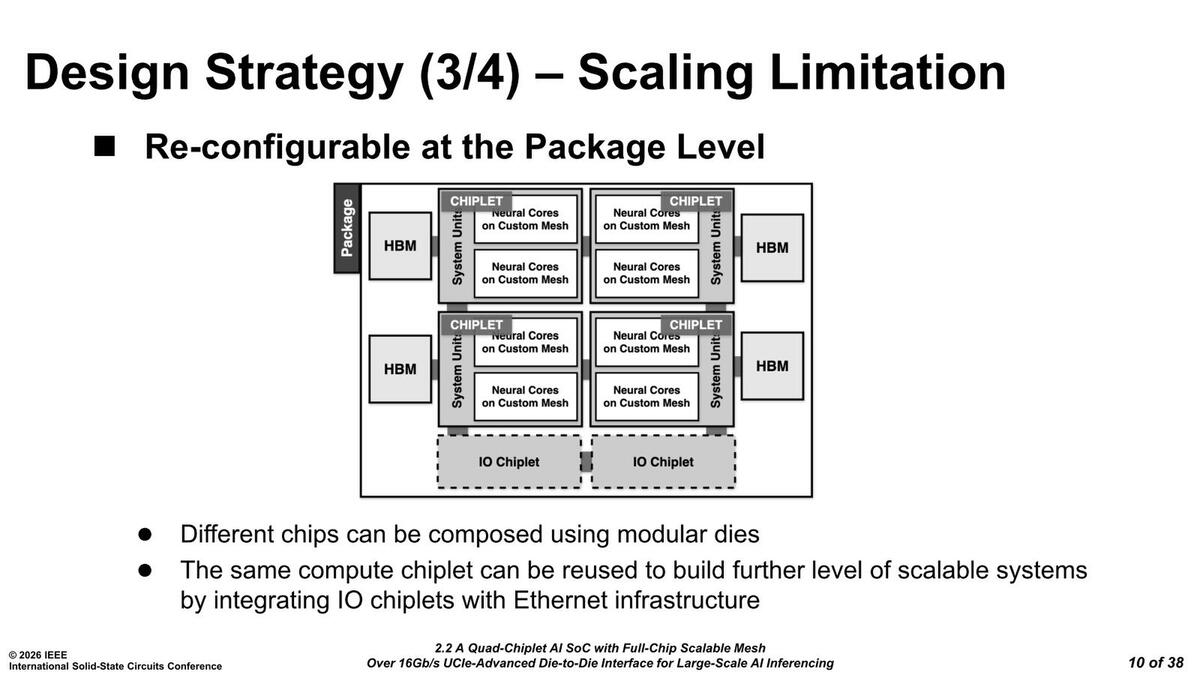
これに関する回答が下の画像である。基本的にはチップレットを全面的に採用する構造で、ただしあくまでも論理的にはそのチップレット構造を見せない配慮になっている。ただ将来はIOチップレットや(後で出てくる)メモリーチップレットなども自由に接続できるような配慮がなされている。
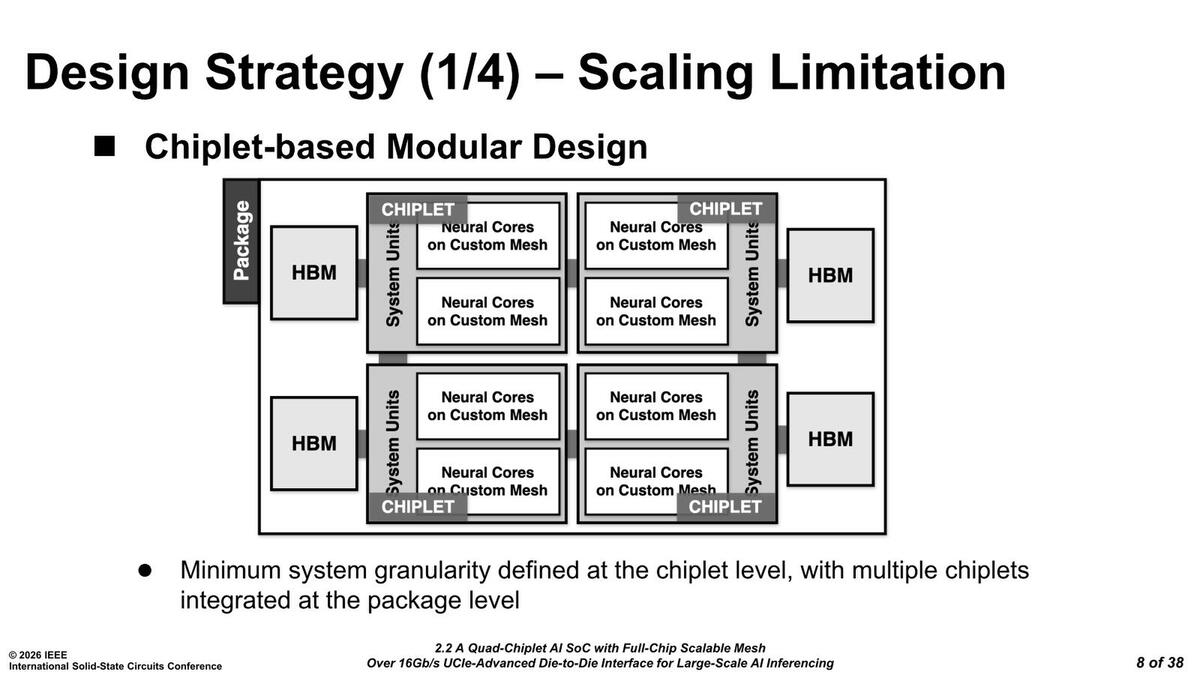
Rebel100というのがおのおののチップレットで、それぞれ2つのニューラルコアのクラスターから構成される。この4つを接続し、さらにHBMを外部に接続する形である
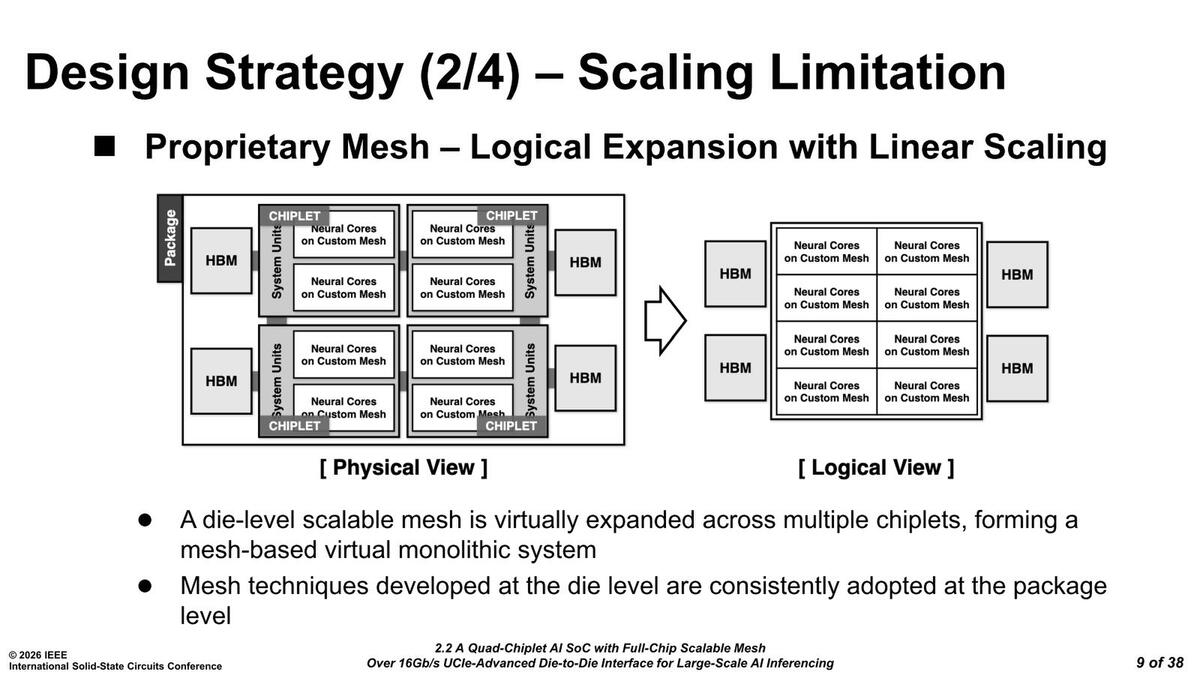
論理的にはこのチップレットのパーティションは存在せず、それぞれのチップレット上のニューラルコアが1つのメッシュでつながっている格好である。もっともHBMに関してはどこまで自由にアクセスできるのかちょっと謎だ
この2×2構造というのは、Sapphire RapidsやInstinct MI300のIODのように鏡対称と点対称での接続になるため本来なら2種類(鏡対称)のダイが必要だが、Rebel100は(後で出てくるが)この図で言えばダイの上下にUCIeのI/Fが用意されており、ただし現状は片方しか利用しないという形の実装になっているので、後追いで拡張が可能となっている

Energy Bufferingはパスコンを入れましょうという話なのだが、REBEL-Quadではなかなか独創的なアイディアを実装した(GraphCoreのBowを連想する仕組みである)
ちなみにIOチップレットはイーサネット向けとされているが、それがスケールアウトなのかスケールアップなのかは不明である。なんとなくrebellionsの考え方からすると、スケールアウトはチップレットでの接続に留め、イーサネットはスケールアウト向けという感じはしなくもない。
最後が電力管理の問題。時間当たりの電流と、PDN(Power Delivery Network)のインピーダンスのどちらも下げることで、電力供給の安定性を高められることになる。といっても、そもそも電力、というより電流を減らすには動作周波数を下げるしかなく、これは性能低下につながる。性能のターゲットが決まっている場合、この方策は取りにくい。
そこで、次善の策が負荷分散である。1つは時間的な電流負荷の分散である。つまりすべてのコアが一斉に稼働すると、ポーンと電流のピークが跳ね上がり、計算が終わるとコアが一斉に待機して電流が急減する。すなわち、コアの稼働にあたり若干の時間的ズレを入れてピークを高くしない方法、もう1つはEnergy Bufferingであるが、これは後述する。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります