



LM StudioでQwen3.5-9Bを動かす
では実際にローカルで動かしてみよう。今回は2つの環境でQwen3.5-9Bの動作を検証した。
| 環境 | スペック | 役割 |
|---|---|---|
| Windows PC | RTX 4070 / 12GB VRAM / 32GB RAM | メインのデモ環境(GPU推論) |
| M2 MacBook Air | M2 / 16GB統合メモリ | ノートPCでの動作検証 |
ローカルLLMを手軽に試すなら、WindowsにもMacOSにも対応しているLM Studioが現時点で最も敷居が低い選択肢だ。GUIでモデルを検索・ダウンロードし、そのままチャットできる。lmstudio.aiから自分のOS向けインストーラーをダウンロードして実行するだけで準備が整う。
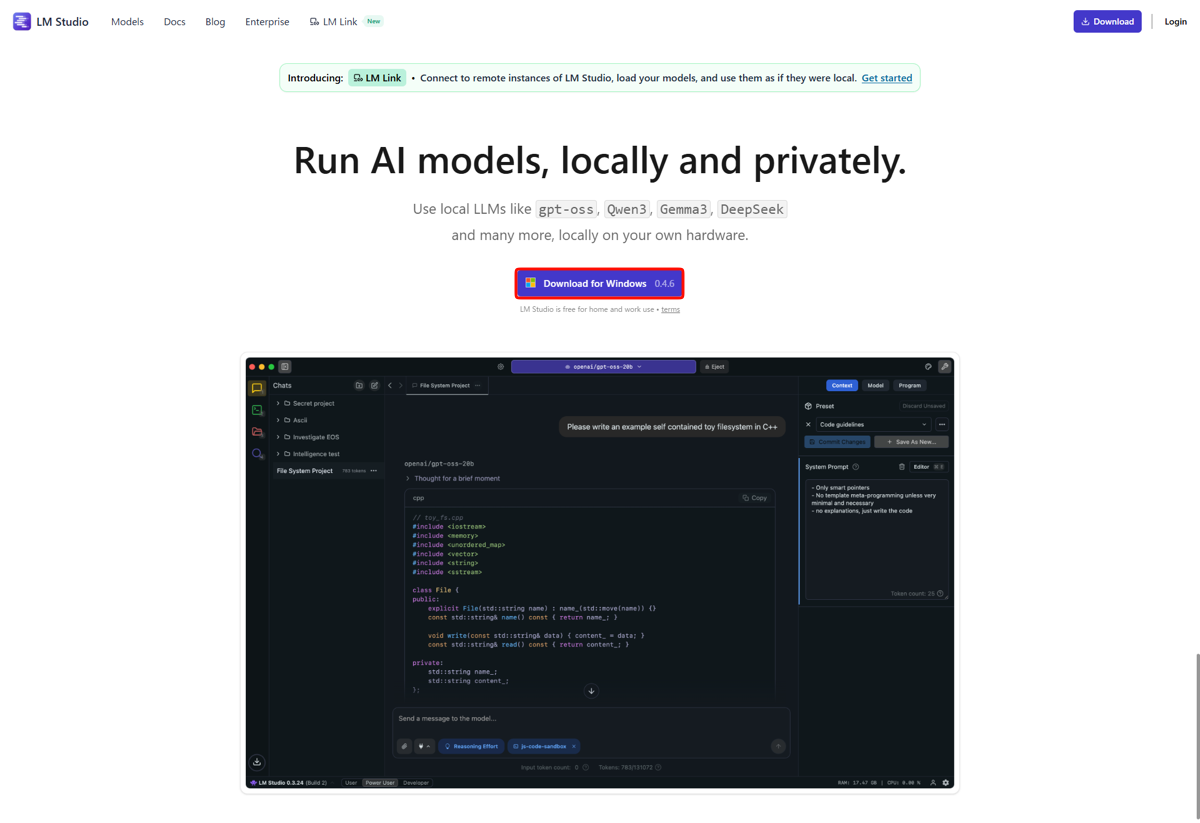
LM Studioを起動したら、左サイドバーの検索アイコンをクリック。モデル検索ウィンドウが表示される。トップに「Qwen3.5 9B」が表示されている。
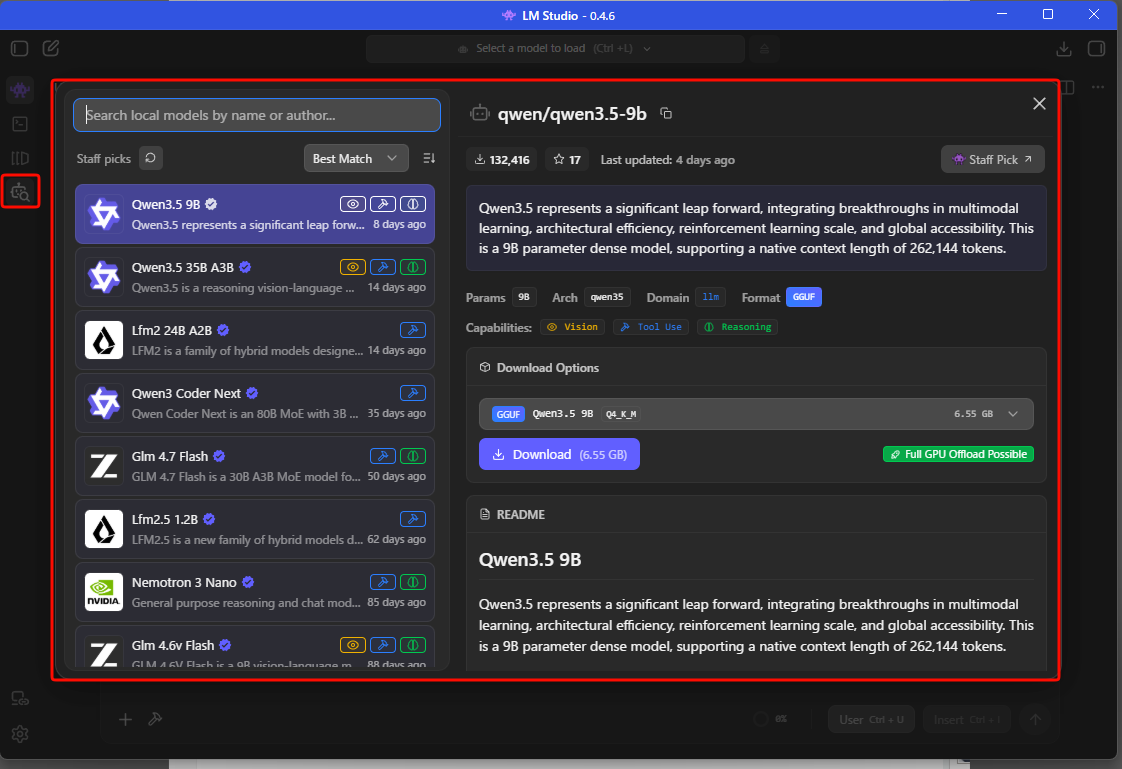
ただし、デフォルトで表示されているのは無圧縮のベースモデル(約18GB)で、VRAM 12GBのRTX 4070には収まらない。量子化済みモデルを検索しよう。
量子化とは、モデルの重みデータを圧縮してファイルサイズとメモリ使用量を削減する技術だ。精度をわずかに犠牲にする代わりに、一般的なPCで動かせるサイズに収まる。量子化レベルが高いほど精度は上がるが、その分ファイルサイズと必要メモリも増える。一般的なPCではQ4_K_M前後が実用的なバランスとされている。主な選択肢は以下の通りだ。
| 量子化 | ファイルサイズ | 特徴 |
|---|---|---|
| Q4_K_M | 約5〜6GB | 定番。品質と軽さのバランスが良く、迷ったらこれ |
| Unsloth UD-Q4_K_XL | 約6GB台 | 重要度の高い重みを優先して高精度で保持する量子化方式。均一量子化より精度劣化が少ない |
| Q3_K_S | 約4GB | 8GBメモリ環境向け。品質はやや落ちる |
| Q5_K_M〜Q8 | 約6〜9GB | VRAMやRAMに余裕があるなら高品質版 |
16GBのMacやRTX 4070環境なら、Q4_K_MまたはUnsloth UD-Q4_K_XLを選んでおけば問題ない。検索欄に「Qwen3.5-9B」と入力して検索、出てきた候補の中から一番上、lmstudio-communityのものを選んで「Download」ボタンを押す。「GGUF」、「Q4_K_M」と表示があるのを確認しよう。
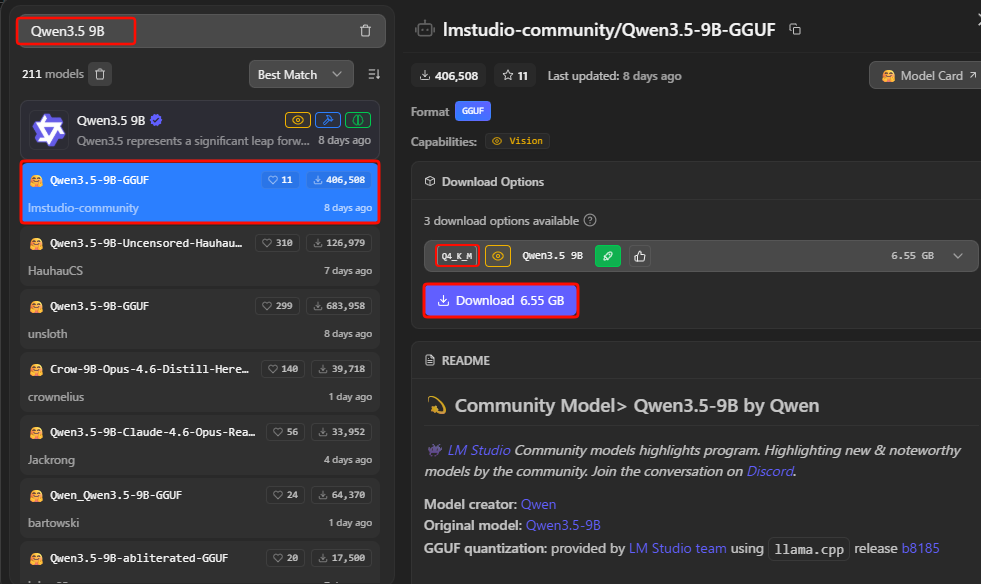
ダウンロードが完了したら「Use in New Chat」をクリック。
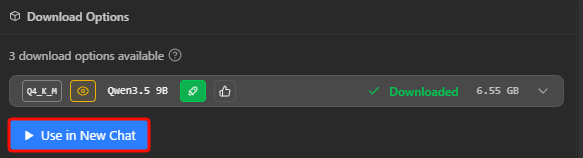
ここでモデルの様々な設定ができるが、とりあえずデフォルトのまま「Load Model」をクリック。
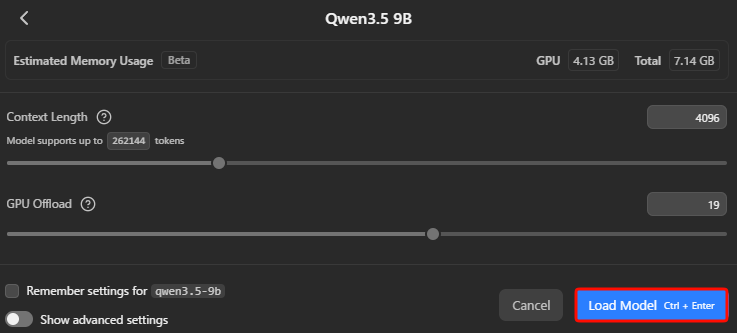
モデルがロードされると画面上部にモデル名が表示される。次に画面左下の「歯車」をクリックして設定ウィンドウを開く。
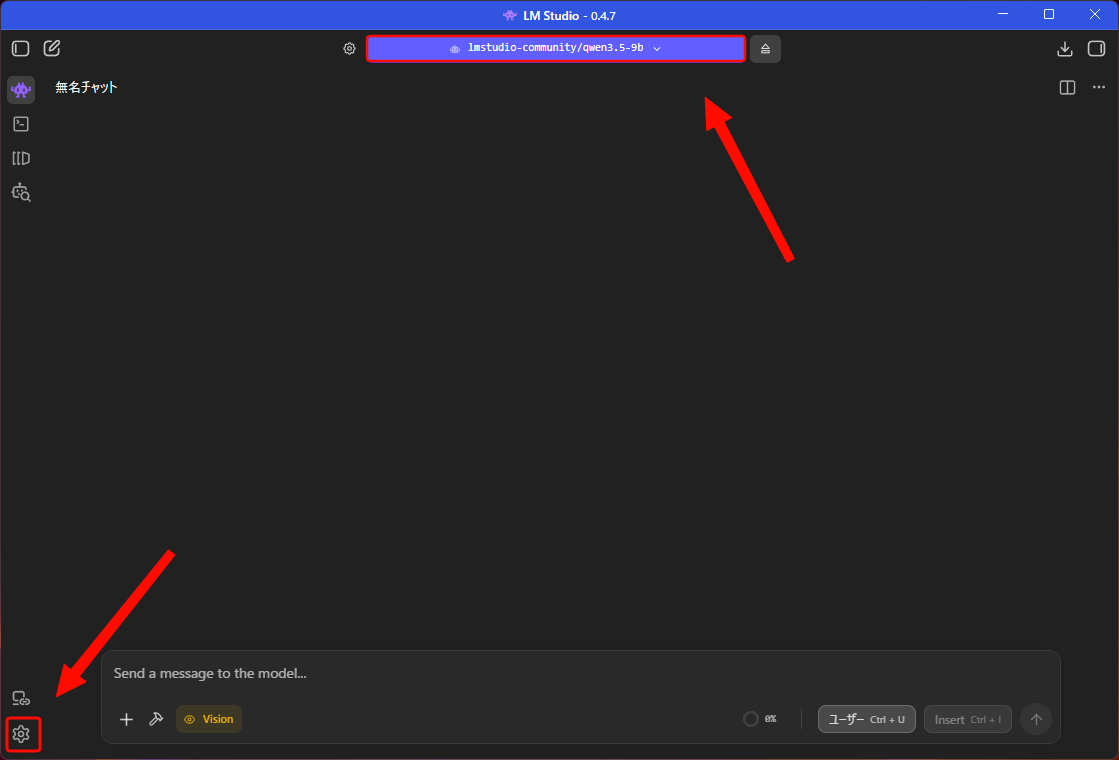
設定ウィンドウ左側のメニューから「Chat」を選び、「チャットサイドバーにプロンプトテンプレートを常に表示」にチェックを入れる。
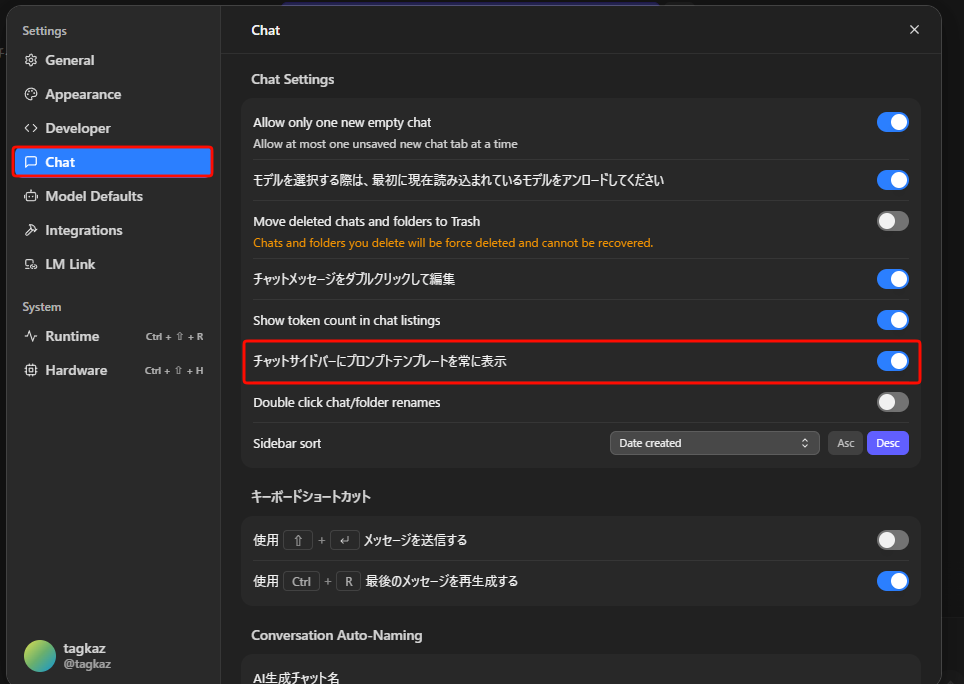
設定ウィンドウを閉じ、画面右上のサイドバー表示ボタンをクリック。
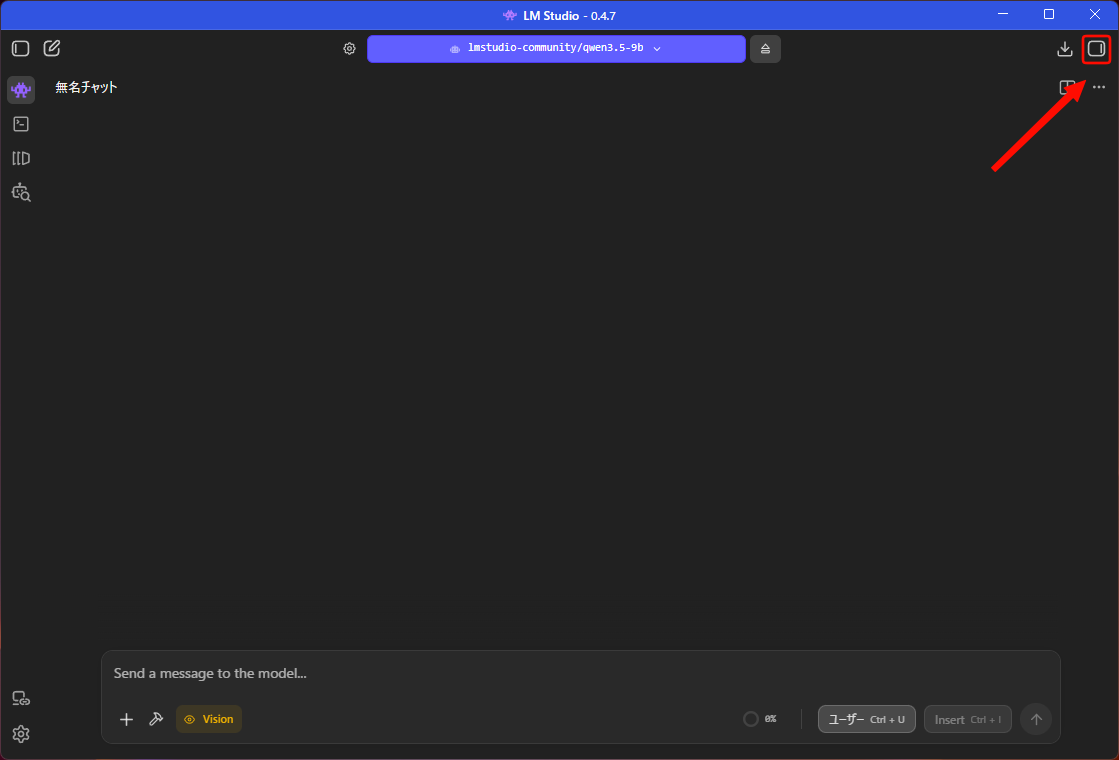
サイドバーが開くので一番下の「プロンプトテンプレート」をクリックして展開する。
デフォルトでは「テンプレート(Jinja)」が選択されている。ここを「手動」に切り替えると、チャットテンプレートを自分で選択できるようになる。
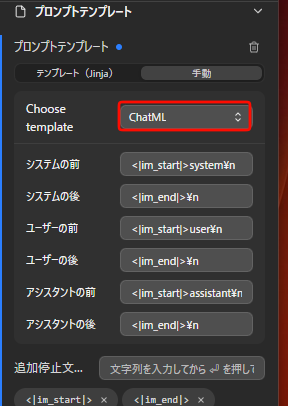
Qwen3.5-9Bではテンプレート設定によって、思考過程(CoT)だけが表示されて回答が生成されない場合がある。その場合は右側の設定パネルの「プロンプトテンプレート」を開き、「Choose Template」を「ChatML」に変更すると正常に応答することが多い。
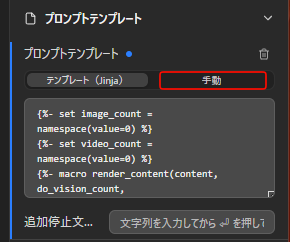
「手動」をクリック
「Choose Template」の欄に「ChatML」テンプレートを選択。
これで準備完了だ。通常のチャットアプリ同様、画面下部の入力欄にプロンプトを入力して利用することになる。もちろんインターネット接続は不要だ。すべてローカルで完結する。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります