




2026年2月から3月にかけ、Alibaba傘下のQwenチームがLLM「Qwen3.5」シリーズを順次公開した。2月16日にフラッグシップのQwen3.5-397B-A17B(397Bパラメータ、うちアクティブ17B)を皮切りに、2月24日にMediumシリーズ(27B dense、35B-A3B、122B-A10B)、3月2日にSmallシリーズ(0.8B、2B、4B、9B)と段階的に展開。全モデルがApache 2.0ライセンスで、商用利用も無償で可能だ。
今回フォーカスするのは、このSmallシリーズの頂点に立つ9Bモデルだ。「9Bごときで何ができる」と思うかもしれないが、ベンチマークでは120Bを超える既存モデルを複数の指標で上回っている。なぜ9Bなのにそれほど強いのだろうか。鍵はアーキテクチャの刷新にある。
Qwen3.5の技術的な新しさ
LLMのアーキテクチャといえば、長らく「Transformer一択」だった。その中核をなすのは、入力されたすべてのトークンが互いの関連度を計算するSoftmax Attentionという仕組みだ。精度は高いが、「全員が全員を参照する」方式はトークン数が増えると計算量とメモリが急激に膨らむ。ローカルLLMで長文処理が重くなるのは、主にこの構造が原因だった。
そこでQwen3.5が採用したのが、Gated DeltaNetハイブリッドアーキテクチャと呼ばれる設計だ。Transformerブロック4つのうち3つを新機構の「Gated DeltaNet」に置き換え、残り1つだけ従来のSoftmax Attentionを残している。つまり処理の大半を軽量な新方式で担わせつつ、精度に必要なAttentionは最小限だけ保持する構成だ。
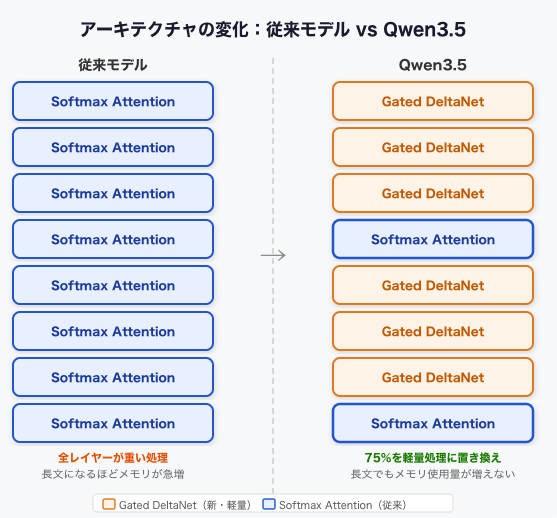
Gated DeltaNetを一言で言うと、「Attentionの計算を減らしながら長文処理を効率化する軽量な系列処理機構」だ。通常のAttentionは全トークン間の関係を毎回計算するため、文章が長くなるほどメモリを食い続けるが、Gated DeltaNetは処理する情報を固定サイズのメモリに圧縮・更新する方式を取る。直近の重要な情報だけを手元に残しながら会話を進める、というイメージに近い。つまり、メモリ使用量の増加を大幅に抑えられる。
この仕組みのおかげで、9Bという小型モデルでも262Kトークンのネイティブコンテキスト長を実現できている。262Kトークンはおおよそ文庫本2〜3冊分のテキストに相当する。長い論文を丸ごと読ませる、大量のコードベースを一度に渡す、といった用途が16GBのMacで現実的になる。大規模モデルでないと扱えなかった長文タスクが、ローカルで動く9Bに降りてきたのだ。
アーキテクチャ以外の仕様も確認しておこう。語彙サイズは約25万トークンで、201言語に対応する。日本語を含む多言語性能については次のベンチマーク節で触れる。推論時には思考過程を出力するThinkingモードと即答するNon-thinkingモードを切り替えられ、タスクに応じて速度と精度のバランスを調整できる。ただしローカル環境(特にGGUF版)では挙動が安定しないケースもある。
ベンチマーク比較:9Bの「異次元」な性能
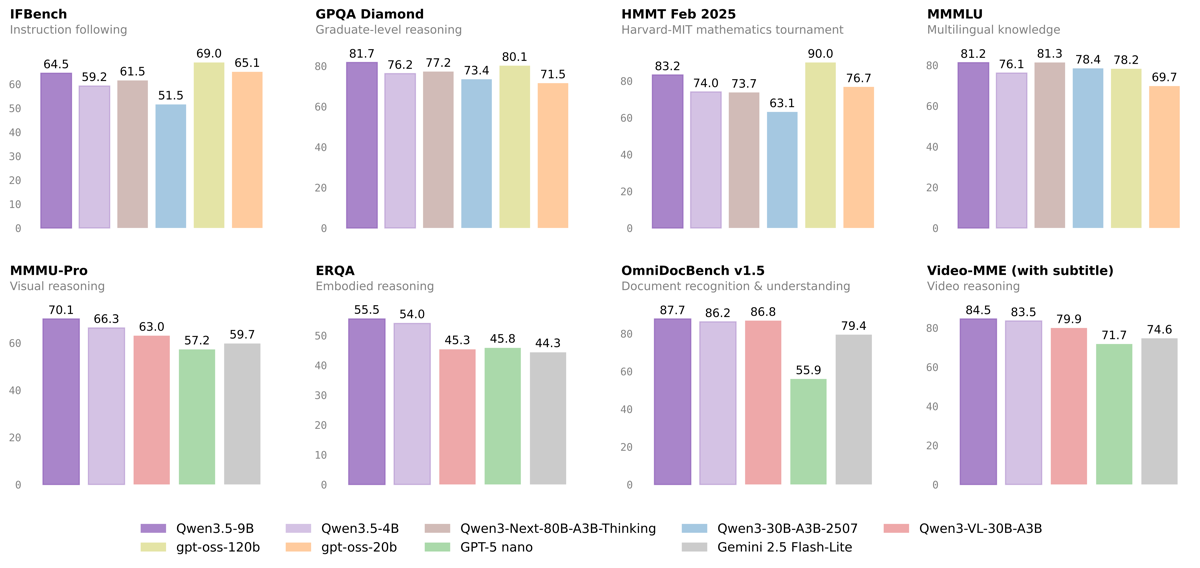
Qwen3.5-9B(紫)と主要モデルのベンチマーク比較。GPQA DiamondやMMMU-ProでGPT-OSS-120Bを上回る一方、HMMT Feb 25では及ばない項目もある。出典:Qwen公式GitHubモデルカード
結果は一様ではない。GPQA Diamond(大学院レベルの科学推論)では9BがGPT-OSS-120Bの80.1を上回る81.7を記録し、長文処理(LongBench v2)でも55.2対48.2と7ポイント差をつけた。指示追従(IFEval)とマルチモーダル推論(MMMU-Pro)でも9Bがトップだ。一方、数学コンテスト(HMMT Feb 25)ではGPT-OSS-120Bの90.0に対して83.2と届かない。得意・不得意はある。とはいえ、13倍以上のパラメータを持つモデルと互角以上に渡り合える9Bが、16GBのMacで動くという事実は変わらない。
実用面で注目したいのが指示追従(IFEval)の91.5だ。「箇条書きで答えよ」「100字以内で要約せよ」といった制約を正確に守れるかを測る指標で、チャットボットやエージェント用途での信頼性に直結する。比較モデルがいずれも88〜89点台に収まる中、9Bだけが91点台に乗っている。
ビジョン性能も見逃せない。マルチモーダル推論を測るMMMU-ProでGPT-OSS-120Bの57.2を大きく引き離す70.1を記録している。Qwen3.5は前世代と異なりビジョン機能をモデルに統合した設計のため、テキストと画像を同列に扱える。9Bというサイズながら、マルチモーダルAIとしても十分な水準に達している。
ただし、ベンチマークはあくまで特定タスクの指標だ。実際の使用感がどう出るかは、ダウンロードして確かめてみよう。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります