



3D実装の完成形へ
MI300シリーズが体現する「チップレットの最適解」
3D実装、特にInstinct MI300シリーズはCPU+GPU+インフィニティ・キャッシュを3D実装するという形で、製品ラインナップの拡充とそれぞれの用途に応じた製品の作り分けという、チップレットのメリットをフルに生かしたものになった。

これはMI300Aの構成。IoDはXCD×2とCCD×3のどちらを載せることも可能な設計になっている。設計するのは大変だったと思うのだが、それをやったからこそ構成の自由度が生まれた格好だ
MI300Xの場合、8つのXCD(それぞれ40個のCUを実装)がSoICの形でIoDと接続され、インフィニティ・キャッシュと最小限のレイテンシーで接続される。このIoDにはPCI ExpressとHBM3EのI/Fも搭載され、インターポーザー経由でHBM3Eと接続される。

内容はともかく、左側の図は初出な気がする。IoD同士の接続はここには記載されていない
この断面を示したのが下の画像であるが、SoICの構造が3D V-Cacheと異なっていること、それとインターポーザーの配線の詳細が出てきたことが新しい。
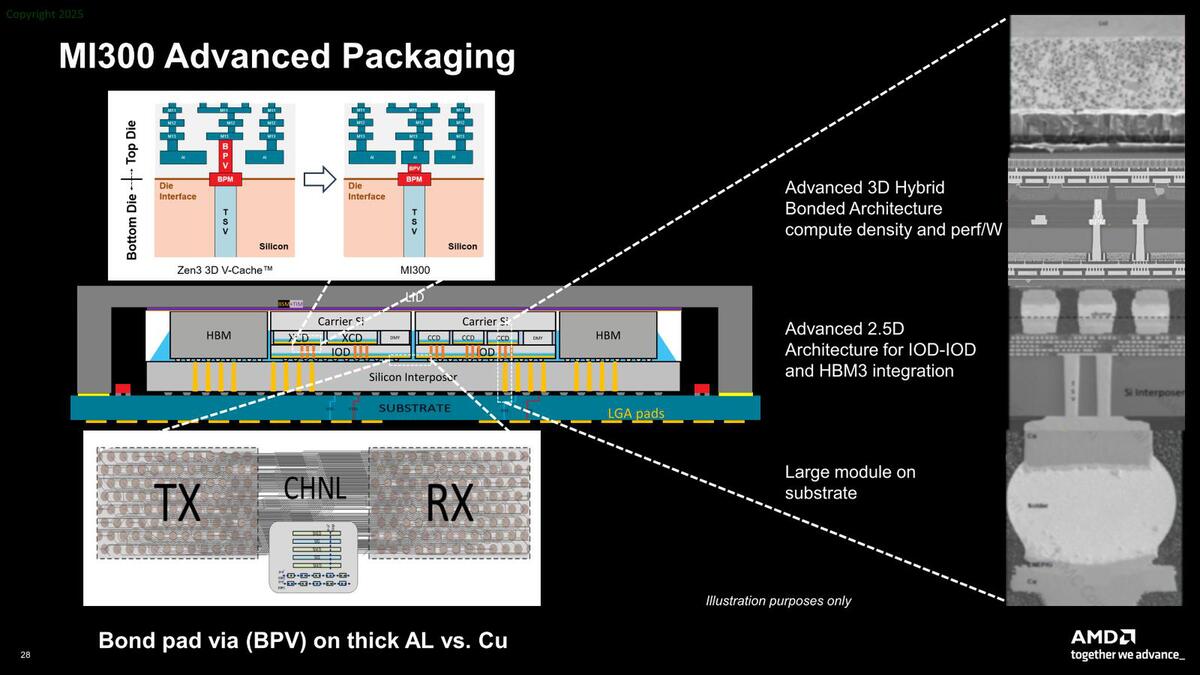
トップダイでのVIAの構築方法が変わっており、より多くのVIAが出せるようになっている。CCDは設計当時、IoDの上にSoICで実装することを想定していたかどうか怪しい。既存のパッケージをそのままSoICで載せられる工程を後工程で追加した可能性もある
このインターポーザーの詳細、左下だがやや潰れてしまっていてわかりにくいのだが、オリジナルには信号の配線がSHILD(Shield)とSIG(Signal)が交互に並んでいる様が示されている。つまりDifferentialではなくSingle Endedの信号であるものと思われる。
ということは、実はこの2つのIoDの間の接続はPHYを介しておらず、3D V-Cacheと同じく直接(といってもESD防止用のClampは入っていると思われるが)信号が流れている可能性がある。
これはインターポーザー間の消費電力削減やエリアサイズ削減、さらに言えばレイテンシー削減にも効果的と思われる。ちなみAMDはインターポーザー間の接続にPHYを介さない、SoW(Sea of Wires)なる方式を使っているという報道が少し前にあったが、MI300のIoD間の接続はまさしくその表現にふさわしい構造ではあるとは思う(報道が正確かどうかは筆者は判断できない)。
動作中のIoD+XCD(or CCD)のヒートマップも示された。最後の行に説明があるが、XCDの場合もCCDの場合も、フルの消費電力で稼働させることが可能であり、そのためにはTSVの配置やパワーマップの構成を注意深く設計する必要があるとされている。
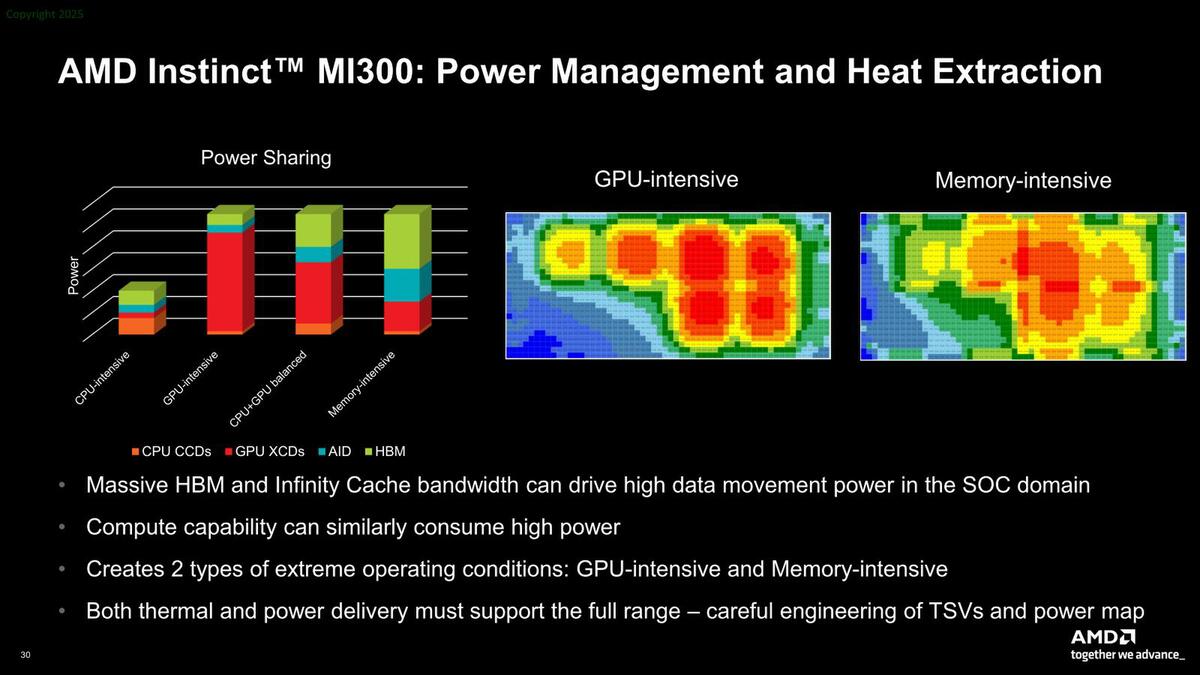
IoD+XCD(or CCD)のヒートマップ。一番消費電力が少ないのはCPU Intensiveの場合であり、Memory IntensiveではIoDがフルに稼働しているように見える
一見単にSoICを使えば簡単に3D実装できるように見えるが、実際にはそこでフルの性能を発揮させるために、相当苦労したものと思われる。説明ではMI350の説明もあったが、この図そのものは以前も公開されていた話である。MI350については次回取り上げたい。

IoDの数が2つにまとまったことは明らかにされた
最後に今後のチップレットの方向性に関する説明も行なわれた。現在AMDが実現しているのは真ん中のMacro on Macroである。
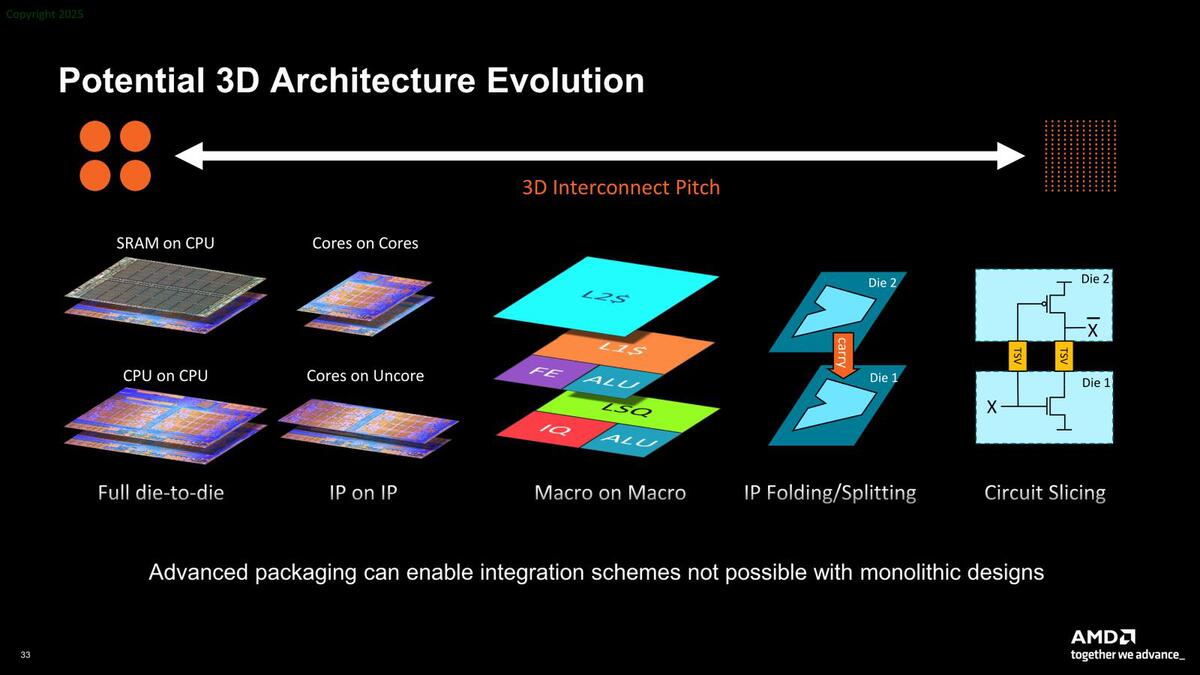
3D V-Cacheの場合、CCD内のL3はそれ単体で動作するが、そのL3から垂直方向に信号線が出て、3D V-CacheのL3と接続される構造である。したがってSRAMセルそのものは独立しているが、L3キャッシュというくくりで見れば物理的に分割されている。Circuit Slicingは端的に言えばSRAMセルそのもののレベルでも分割できるが、今のところそこまでやるメリットは薄いだろう
Ryzenの3D V-CacheやMI300/350シリーズのCCD/GCDとIoDの接続はまさしくこんな関係である。これに続くのはIP Folding/Splitting、その先にはCircuit Slicingであるが、実は3D V-Cacheは電気配線的にはすでにCircuit Slicingに近い(同じではない)。今後は他のベンダーもこれに追従していくものと思われる。
また、3Dメモリー積層に関しても今後は利用されることを示している。外部の長距離接続は、今後光通信が積極的に使われるとしており、またインターポーザーも今後はPLP(Panel Level Package)に推移するとした。

3Dメモリー積層。筆者の個人的な感想としては「WideIOが10数年の時を経て蘇った」である
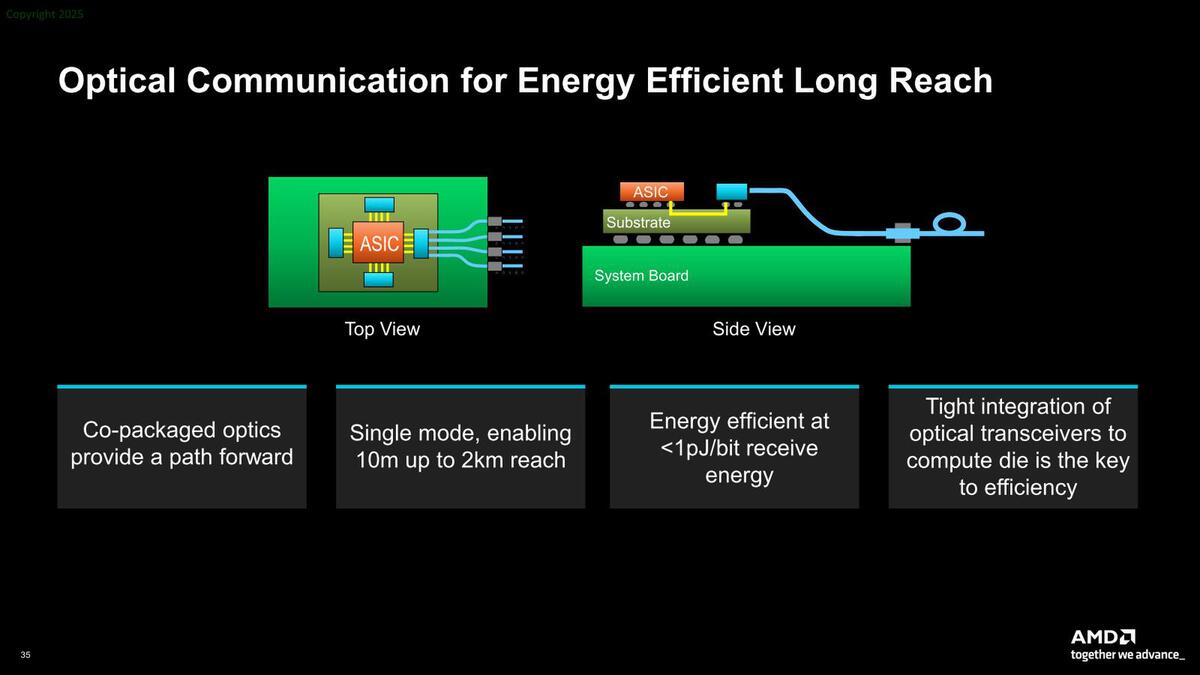
長距離接続は光ベースになるが、逆に言えば数mのオーダーは引き続き電気信号ベースになる、としている
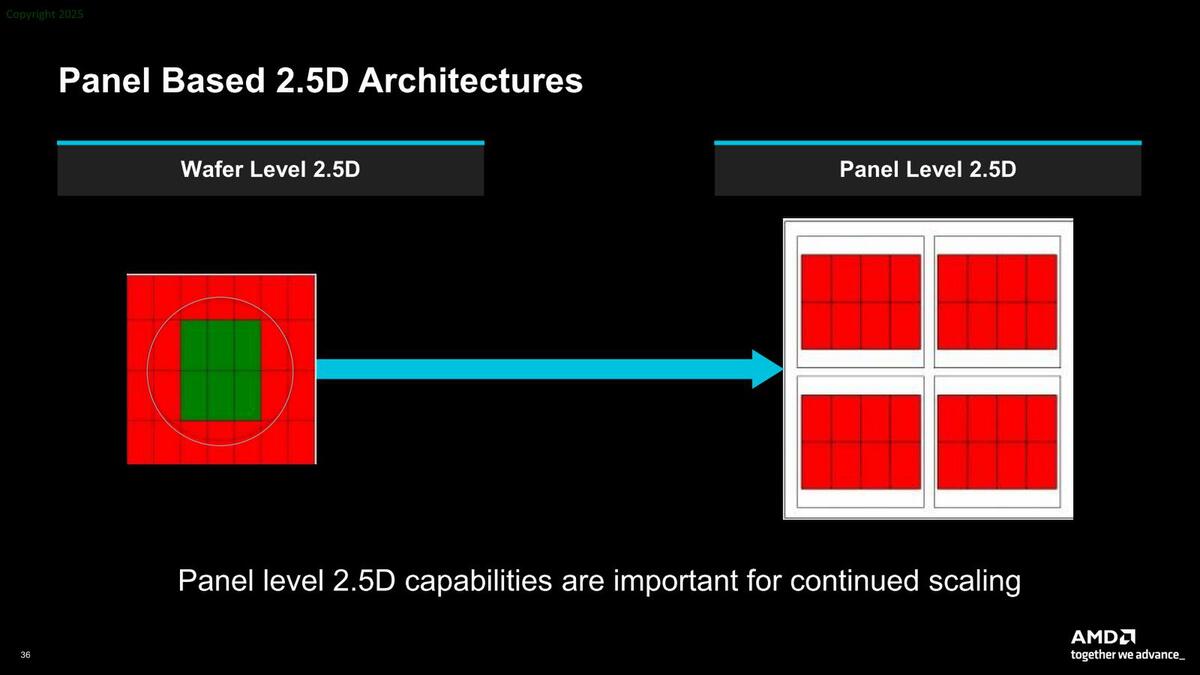
インターポーザーはPLPに推移する。もっともPLPで現在のシリコン・インターポーザーと同じ精度の高密度配線が可能か? というと現状は無理。パネルの精度や物理特性などまだ問題は結構ある
アーキテクチャー的にも、すでにデータフローは広範にAIプロセッサーで使われているが、より一層の性能消費電力比改善にはPIM(Processor in Memory)の方向性に進むとしている。
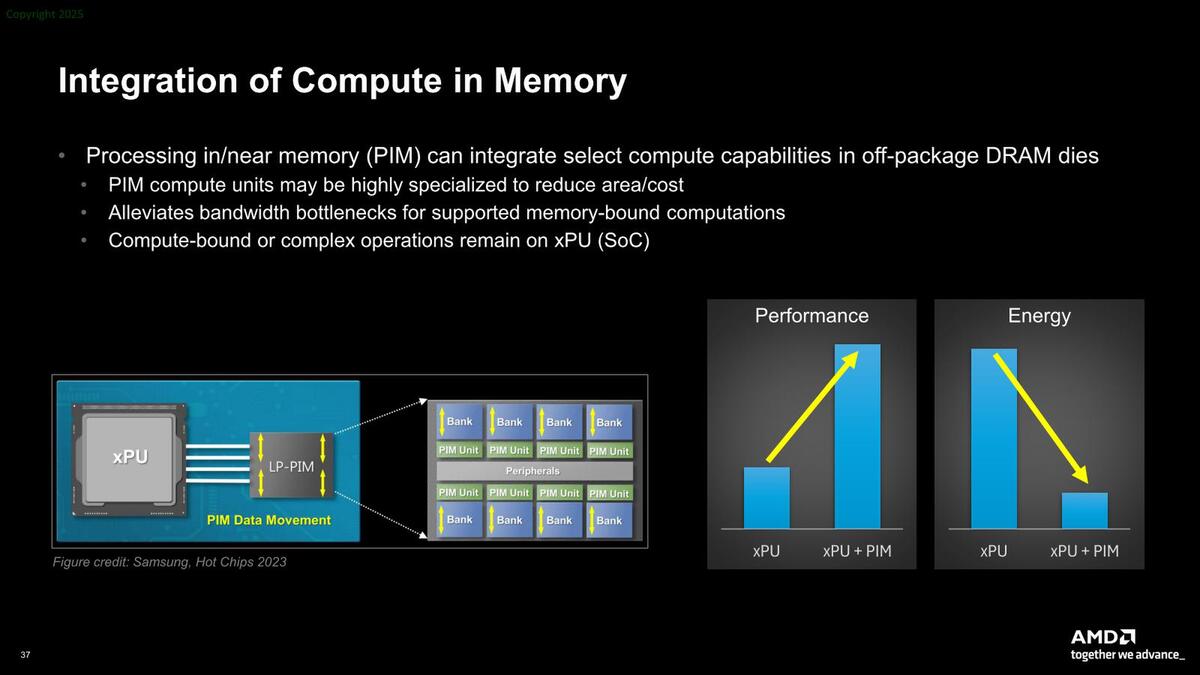
現状のPIMはEdgeの推論程度には十分だが、LLMや大規模なものに関して言えば、結局煩雑にWeightの入れ替えが発生してしまい、それほど効率的とは言えない。こちらももう少し進化させないと厳しいだろう
さてAMDの説明ということもあってMI300などを中心に説明したが、なぜこれを今回取り上げたかというと、今年のISSCCでAMDがInstinct MI350の詳細を説明したためである。そこで今回の内容を下敷きに、次回はそのISSCCでの内容を解説したい。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります