



チップレットがもたらす圧倒的な経済性
歩留まり改善による「原価半減」の衝撃
さて話はチップレットに移る。チップレットのメリットとして一番大きいのが経済性である。同じウェハーからとれるダイサイズを小さくすると、それだけ歩留まりが改善する。これはそのままコスト削減につながる。
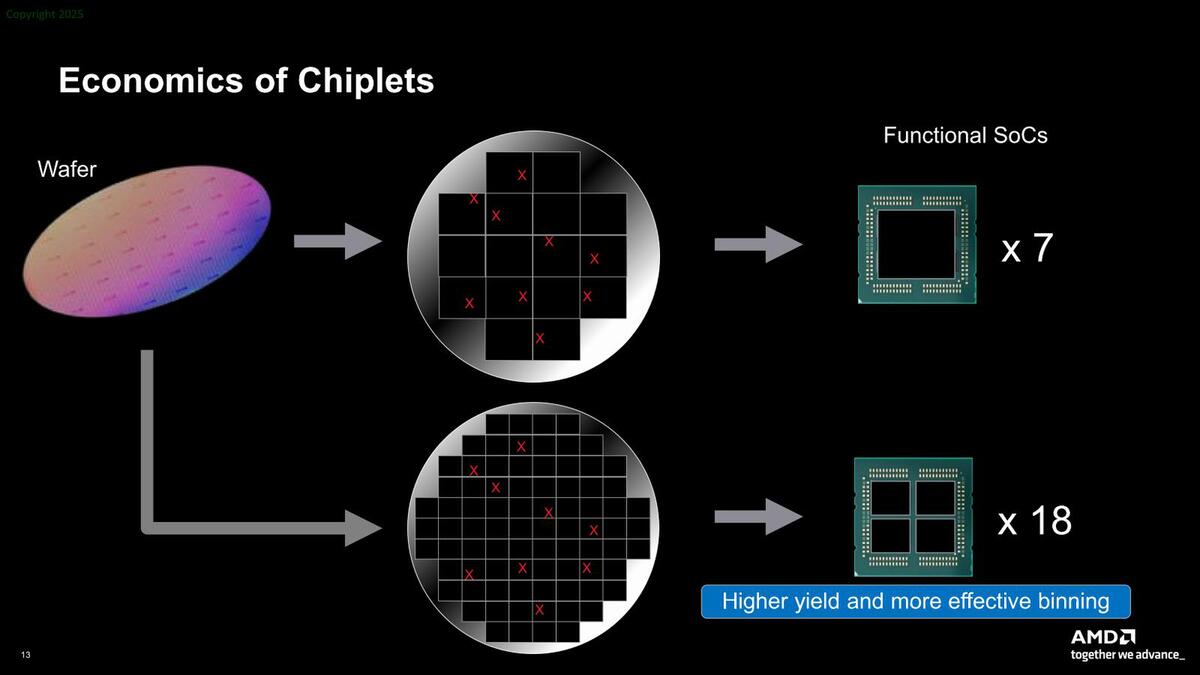
これはあくまで模式図である。この寸法では、上側のダイサイズは54.5×50mmほどで2700mm2を超えるダイが作れるように見えるが、もちろんこんな巨大なダイはReticle Limit(一度の処理で作成可能な物理的な上限)に引っかかるため製造できない
2025年末の話で言えば、TSMCのN3のウェハーコストはおおよそ2万ドルとされている。この2万ドルのウェハーから大きなダイを作るとダイが7つしか取れないから、チップ原価は2800ドルを超える。ところがこれを縦横半分のサイズのダイに分割して、それを4つ搭載するチップレット構造にした場合、73個のダイが取れるので、これを4つづつ組み合わせても18個分のプロセッサーが製造できる。
ダイ1個当たりの原価は274ドルほど。4つで1096ドル。実際にはインターポーザーなどの分が加味されるが、それでも1200ドル程度であって、大きなダイの場合の半額未満で構成できることになる。
次のメリットがヘテロ構成だ。上の画像は大きなダイを均等に分割する構成(Sapphire Rapidsなどがこの好例だろう)を考えているが、下の画像は機能分割した例である。
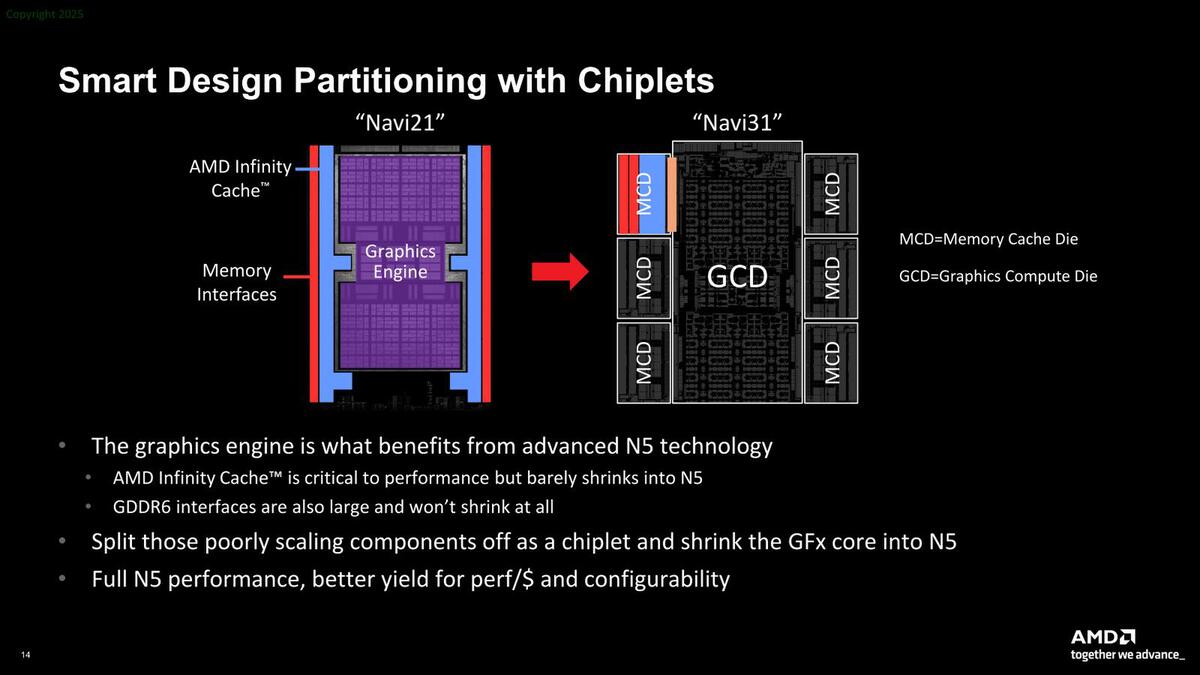
Navi31場合、GPUのコアそのもの(GCD)は5nmで、インフィニティ・キャッシュ+メモリーコントローラー(MCD)は6nmにすることで、全部5nmで製造するよりも歩留まりを引き上げ、原価を下げている
モノリシックなダイは当然ながら製造プロセスは均一である。「CPUコア部は5nmで、PHYは7nmで」というわけにはいかないので、5nmなら5nmでダイ全体を製造する必要がある。ところがCPUやGPUのコア部分に比べると、キャッシュやメモリコントローラー/PHYは、プロセス微細化の貢献を受けにくい。
キャッシュはプロセスを微細化してもそれほど密度が上がらない(配線幅の方が密度に支配的)し、PHYなどはプロセスを微細化しても小型化しない(できない)。こうしたものは先端プロセスよりやや大きめのプロセスでも機能や性能に支障はなく、それでいてその分価格が安くなる。そこで機能に応じて分割する方式がこれで、ほかにもRyzenやEPYCのIODもこれに該当する。
3つ目のメリットは、モノリシックでは製造不可能なサイズのチップが作れることだ。下の画像は第2世代EPYCを例にとったものだが、そもそも64コアの製品は仮にモノリシックで製造しようとするとReticle Limitに引っかかって製造できなかった。巨大なダイを作れる、ということもメリットである。
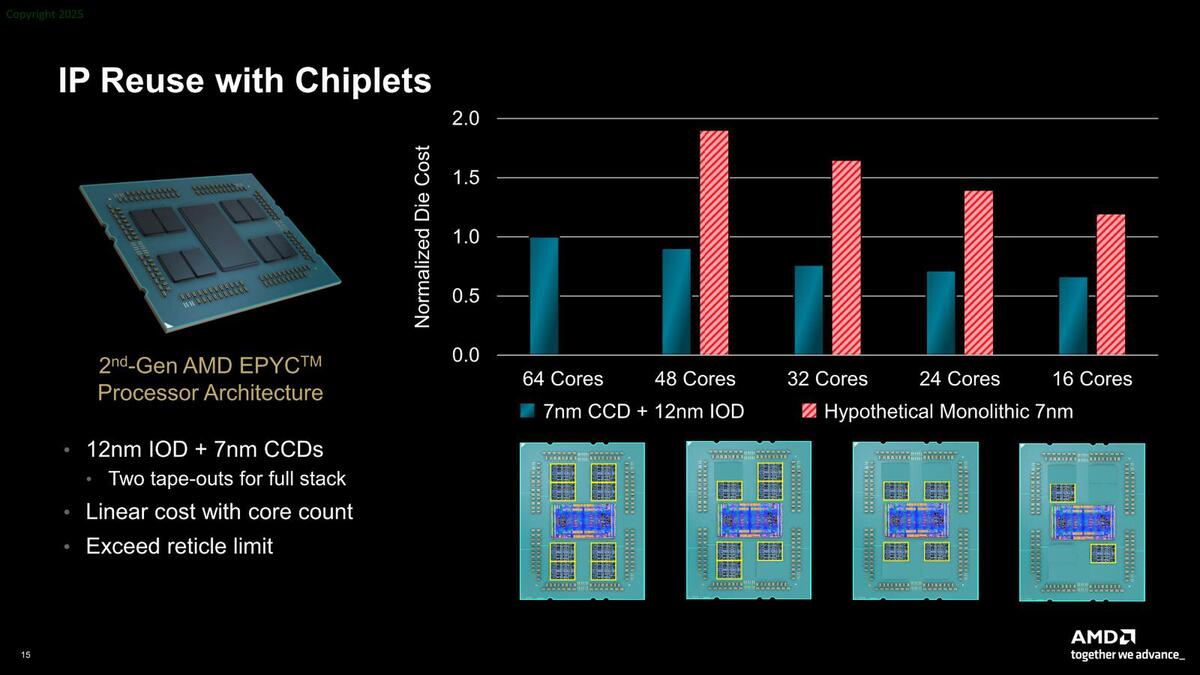
赤棒が7nmのモノリシックで製造した場合のダイのコストである。48コアではチップレットを使う場合の2倍ながらなんとか製造できるが、64コアは製造できない
もちろんメリットだけではなくデメリットもある。まずは物理的に、チップレット構成にすることでダイが大型化する。要するに2つのチップレットを接続するためのPHYや、場合によってはコントローラーも追加する必要がある。またチップレット同士をどう接続するかも問題である。

チップレットはダイが大型化する。Instinct MI300シリーズでもIODはMirrorとRotateの2種類を併用しており、IoDはMirrorで2種類存在する
うまく点対称になっていれば、180度回転させてつなげばいいわけだが、それこそSapphire Rapidsのような構造では左右対称のダイも用意しないといけなくなる。この分の設計およびダイ上のエリアのオーバーヘッドが一定量存在する。
また性能面でのオーバーヘッドも存在する。下の画像はIoDを使わない、初代EPYCのケースであるが、ここではインフィニティ・ファブリックで4つのダイを相互接続する(この通信が51ナノ秒ほど発生する)関係で、ローカルのメモリーコントローラーのレイテンシーが90ナノ秒なのに対し、リモートでは141ナノ秒ほどになる。
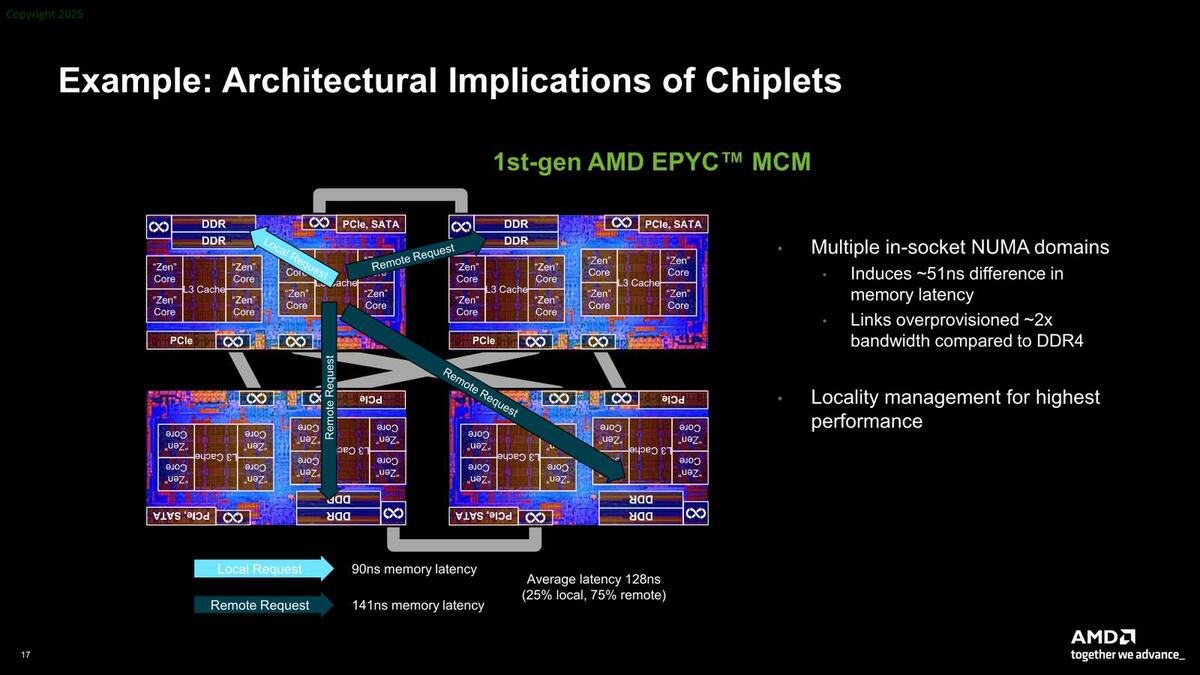
IoDを使わない初代EPYCのケース。説明はないが、このインフィニティ・ファブリック経由の通信が2~3pJ/bit程度の消費電力を要したはずで、これによる消費電力増加も欠点である
全体として128ナノ秒ほどのレイテンシーになる計算で、これは当然性能に若干のインパクトが出る。作り方の問題でもあって、メモリーコントローラーをIoDで別に設けることで、レイテンシーを20ナノ秒程度まで短縮可能になっている。
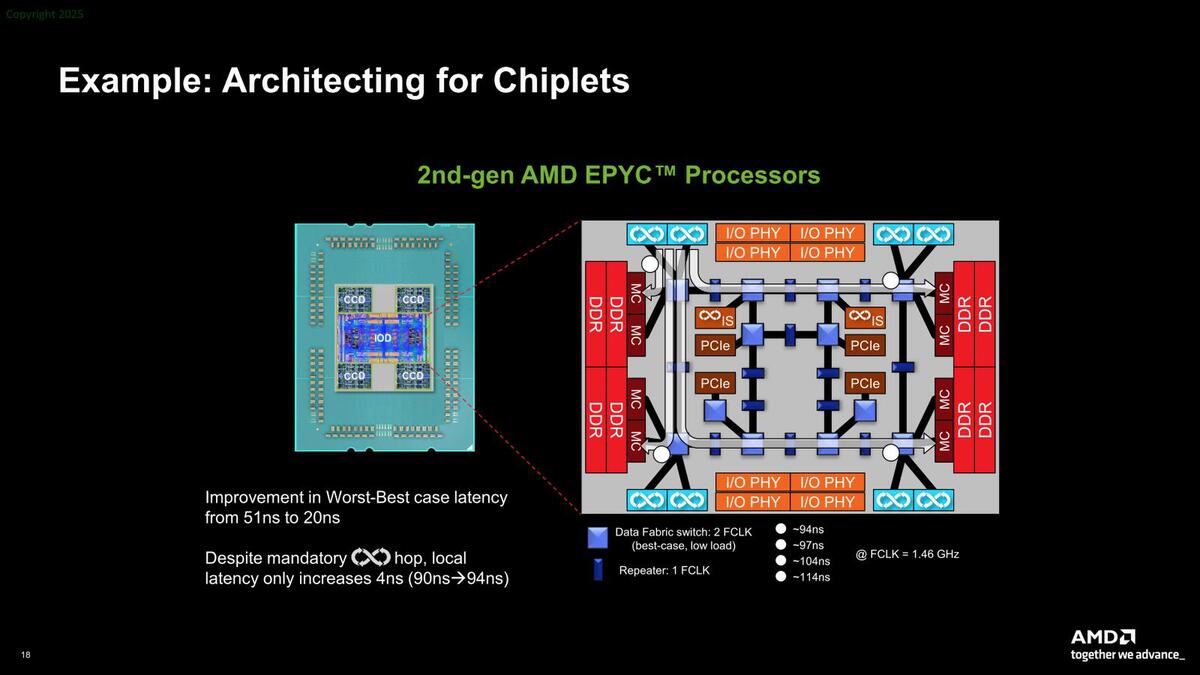
第2世代EPYCのケース。ローカルのメモリーアクセスという概念がなくなるので、メモリーアクセスのレイテンシーの最小値は若干増えることになる。これを良しとするかどうかも問題だ
次がパッケージの選択である。下の画像はパッケージ構成ごとの効率である。つまり1bitを伝送するのに何J必要かを相対値で示したものである。
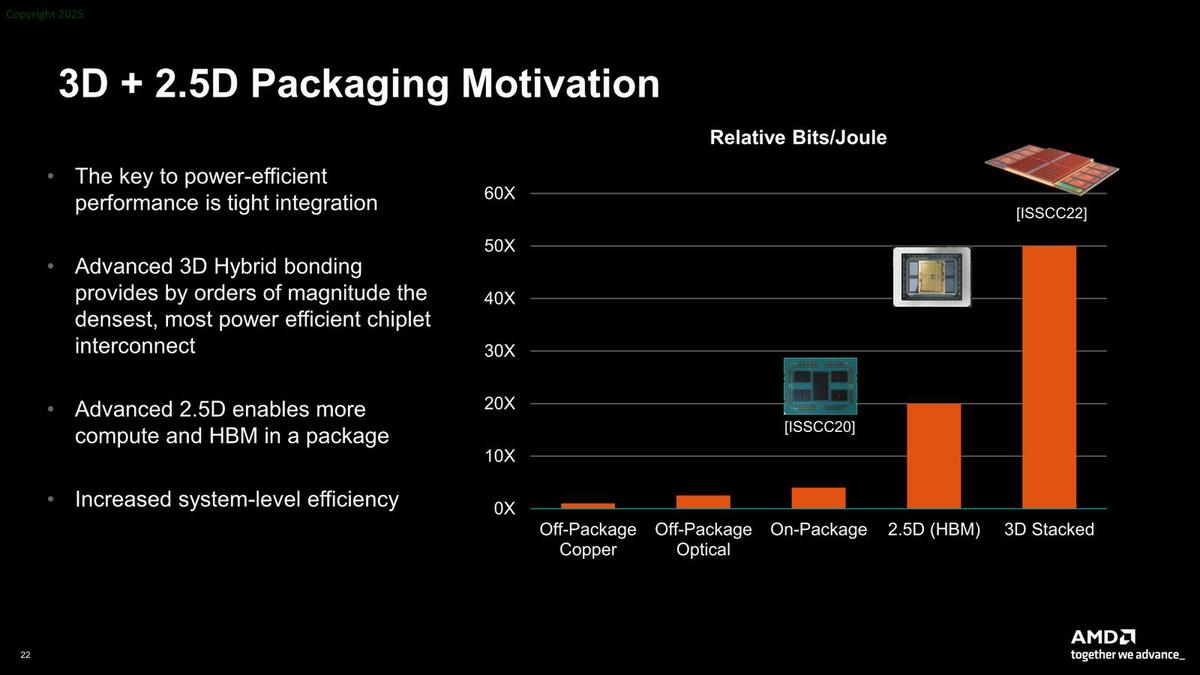
パッケージ構成ごとの効率。HBMはシリコン・インターポーザーが前提なので2.5D扱いになっているが、別にHBMを使わなくてもこの効率向上が得られる
Off-Package Copperというのは、例えば昔のCPUとチップセットの間がDMIでつながっているような構成であり、これをOn-Packageにするだけで5倍ほど効率があがる。これをシリコン・インターポーザーにすることで20倍ほどになり、3D積層では60倍まで効率が向上する。
こうした進化により、チップレットに付き物である消費電力増加の影響を最小限に抑えられる。AMDはこれを自社製品に順次取り入れている。実際に商用製品に取り入れたという意味ではAMDは他社を圧倒しているし、現在もそれなりに先行していると考えられる。
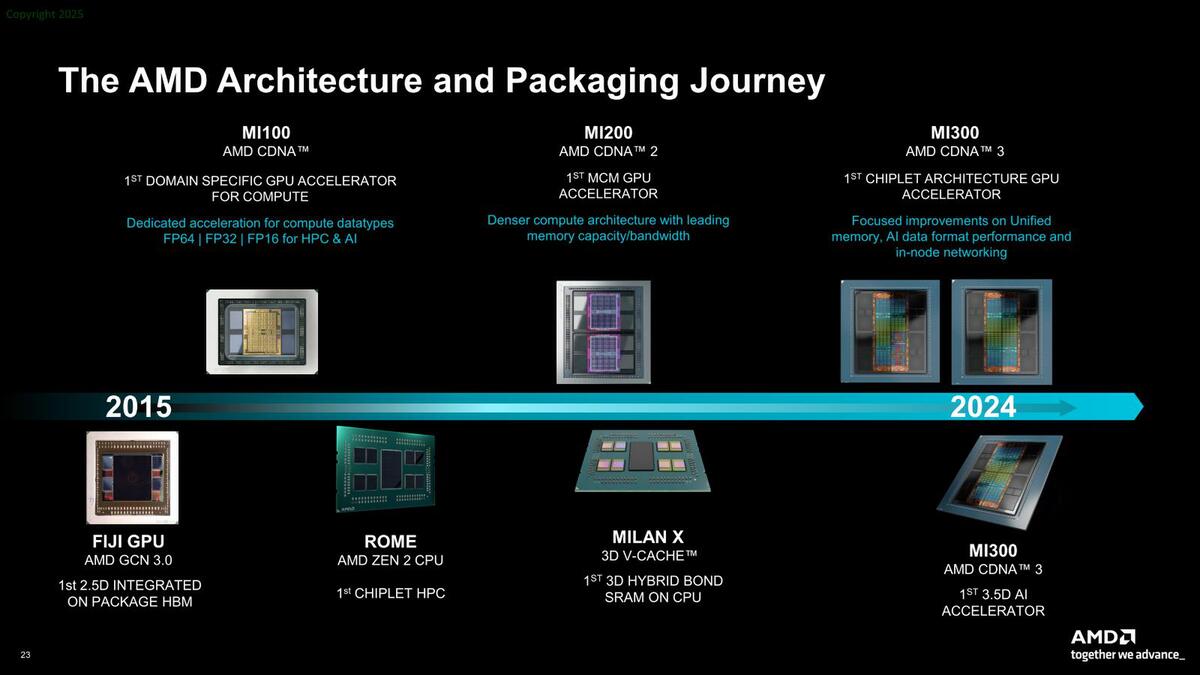
パッケージ技術の進化。FijiやInstinct MI100のHBMは単にインターポーザーを使っただけでチップレットではないとは思うのだが……
純粋に技術的な話でいえば、2020年に3D実装となるLakefieldを市場投入したインテルが先行した、と言えなくもない部分もあるが、それが市場で成功を収めたかというとそれはまた別の話である。
AMDが3D V-CacheとしてSoICをベースに3次キャッシュを3D実装し、それがゲームのフレームレートの上振れに大きく貢献し、市場シェアを伸ばしたといった実績に相当するものを、ついにLakefieldは手に入れられなかった。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります