



最新の画像生成AIは“編集”がすごい! Nano Banana、Adobe、Canva、ローカルAIの違いを比べた
2026年01月09日 13時00分更新

Stable DiffusionやMidjourneyの登場以降、画像生成AIの世界では、テキストを入力すれば画像が生成されるT2I(Text to Image)という仕組みが中心的な役割を担ってきた。いかにしてAIから理想の一枚を引き出すか。そのための言葉選びを研ぎ澄ます「プロンプトエンジニアリング」は、新たな職人芸としてこの数年でもてはやされてきた技術だ。
だが、こうした「呪文」の探求も、すでに一巡した感がある。テキストから画像を生成できること自体はもはや当たり前となっており、いま注目されているのは、プロンプトの巧拙で一発勝負をかけることではない。一度生成した画像をどう扱い、どう意図どおりに作り替えていくかという「編集」のフェーズだ。
その流れの中で、マスク作成や細かなパラメータ調整を意識せず、自然言語の指示だけで画像を編集できるAIが、現実的な選択肢として浮上してきた。生成結果をどう制御するかに悩まされ、プロンプトの限界を感じてきた立場から見ると、この変化はかなり大きい。
「描画」から「修正」へ
本記事で扱う「編集系」生成AIとは、新しく画像を描くためのAIではなく、既存の画像を入力として受け取り、それを編集して出力することに主眼を置いたAIを指す。
ただし近年は、生成と編集の境界が曖昧になり、生成直後の画像をそのまま編集対象として扱うタイプも登場している。本記事では、そうした広義の編集系AIも含めて扱う。
従来の画像生成AIは、白紙のキャンバスに対してテキストから画像を生成するT2I(テキストtoイメージ)が中心だった。一方で編集系AIは、すでに存在する画像を前提とし、不要な要素の削除や差し替え、背景の拡張、文字の書き換えといった処理をする。
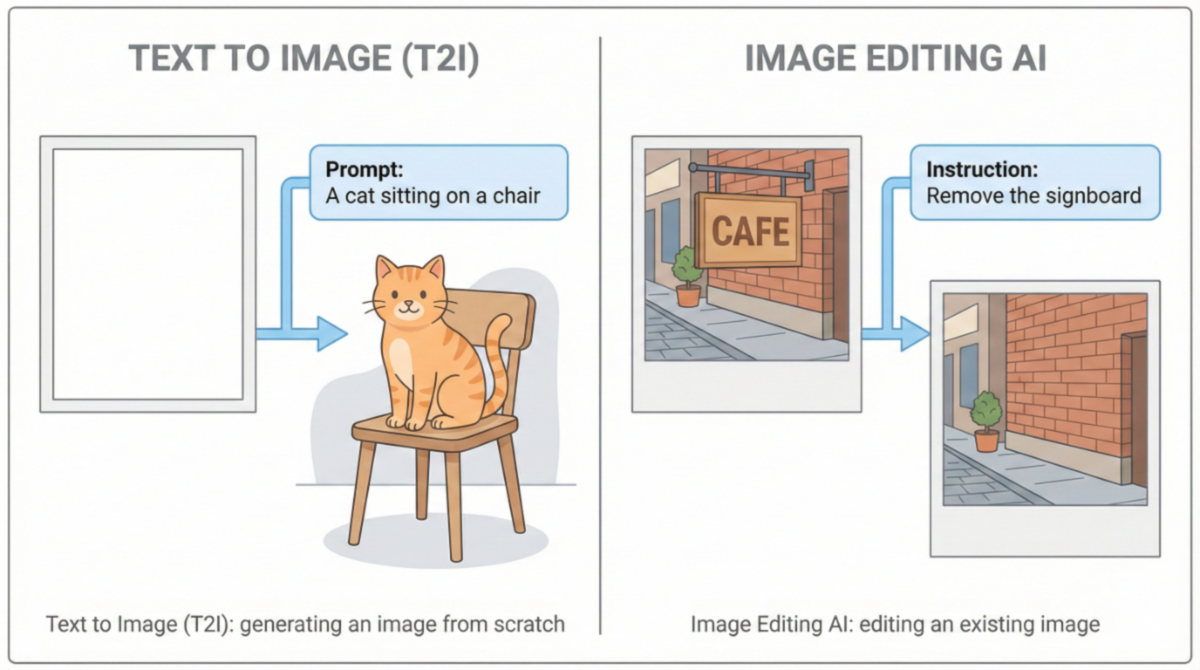
「T2I」と「編集系AI」の違い
編集系AIで重視されるのは、単に見た目を変えることではない。元の画像が持つ構図や文脈、照明条件、被写体同士の関係性を保ったまま、必要な部分だけに手を加えられるかどうかが問われる。
たとえば「人物を消す」「看板の文字を書き換える」「背景だけを差し替える」といった編集では、削除された部分の背後にあったはずの情報を補完したり、全体のトーンに違和感が出ないよう調整したりする必要がある。編集系AIは、こうした処理を人間の手作業に頼らず実行する。

看板を削除する例
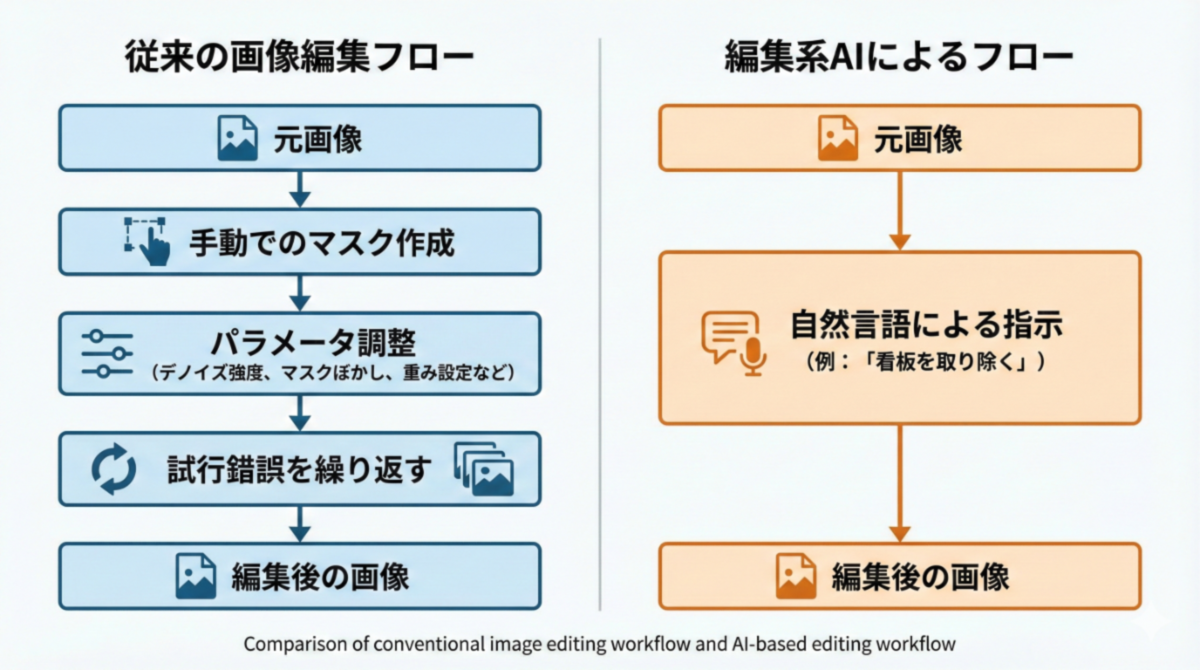
もう一つの特徴が、操作の単純化だ。従来はマスクの作成や強度調整など、複数の工程を経る必要があった編集作業が、自然言語による指示だけで完結するケースが増えている。
この変化により、画像生成AIは「どう描かせるか」を試行錯誤するツールから、「どう直すか」を指示するツールへと性格を変えつつある。
なぜ言葉だけで直せるのか?
ここ数年で大きく変わったのが、LLM(大規模言語モデル)とVLM(視覚言語モデル)の統合だ。従来のVLMが画像を生成するだけでなく、LLMが画像の内容を理解し、指示の意図を汲み取ったうえで処理を進める仕組みが整ってきたのだ。
これまでの画像編集では、どこを編集するかを人間が細かく指定する必要があった。対象を選び、マスクを切り、強度や境界を調整し、結果を見ながら微修正を重ねる。一定の品質を出すには経験と手間が必要だった。
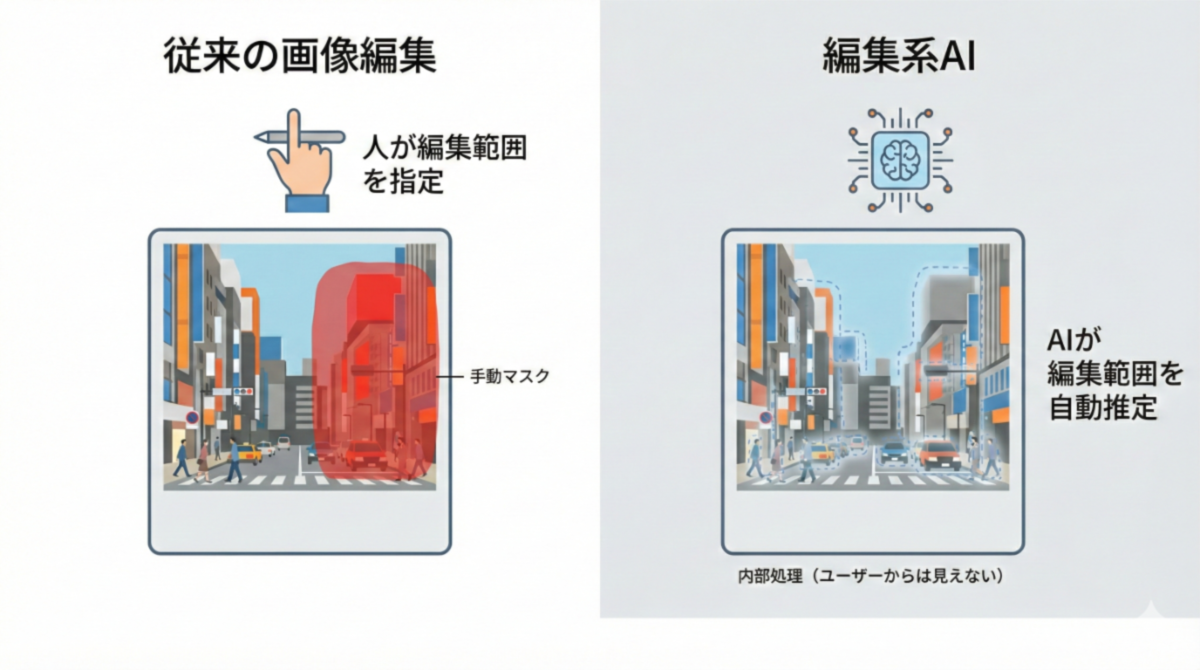
AIが自動でマスク処理
編集系AIでも、内部では編集対象となる領域を判定している。概念的にはマスクと同じ役割を果たす処理だ。ただし、その作業はユーザーの手を離れ、AI側で自動的に実行されるようになった。
LLMとVLMが組み合わせられることで、曖昧な指示は具体的な編集内容へと変換され、画像の中から対象を検出し、必要な範囲を推定したうえで編集処理まで一気通貫で実行される。ユーザーがマスクを意識する場面はほとんどない。
その結果、「背景を夕焼けにして」といった自然言語の指示が、そのまま実用的な編集につながるようになった。編集が楽になった理由は、工程が消えたからではない。編集範囲を指定する役割そのものが、人からAIへと移ったためだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります