



AIエージェントにディープダイブしたAWS re:Invent 2025基調講演レポート
教えて、ほめて、注意して AWSが考える「本番に強いAIエージェントの育て方」
2025年12月05日 07時00分更新
強化学習でファインチューニングを実現する
続いてシバスブラマイアン氏は、AIエージェントの効率性についてフォーカスする。さまざまなサービスの登場で、複雑なツールの利用、多段階での推論、予期せぬ状況への対処は可能になったが、本番運用においてはコスト、レイテンシ、規模、俊敏性などの問題に対応しなければならない。
「AIエージェントの大多数は、コードの実行、検索結果の分析、コンテンツの作成などの日常的な操作にほとんどの時間を費やしており、定義済みのワークフローを実行している。こうした内容を事前に知っていれば、専用のモデルをカスタマイズ可能できる。問題はモデルをカスタマイズすべきかではなく、どれだけ迅速に改修できるかだ」とシバスブラマイアン氏は語る。
シバスブラマイアン氏は「AIエージェントは、ジェネラリストではなく、スペシャリストとして教育すべき。かかりつけ医を診療専門医に変えるようなものだと考えてください」と述べ、ファインチューニングのテクニックについて具体的に説明した。
もっともシンプルなのは、事前学習されたLLMに新たな知識(ナレッジベース)を覚え込ませること。ただ、追加するデータが増えすぎると、本来モデルが持っていた精度や性能が失われてしまう。「大事なのは、量より質にある。世界トップクラスの外科医による手術の1万本の動画と、何百万ものYouTube動画のどちらから学ぶか。答えは明らかだ」とシバスブラマイアン氏は語る。
そこで注目されたのが、教師モデルから小型の生徒モデルを構築する「モデル蒸留」という手法だ。「熟練の職人から学び、半分の道具と時間で同じことを実現できる優秀な弟子を育成するようなもの」と語る。教師データのみならず、思考プロセスを模倣し、精度をほぼ維持しつつ、リソース消費の少ないモデルを作るわけだ。

教師モデルから生徒モデルを生成するモデル蒸留
ただし、精度の高い教師モデルから生徒モデルへの蒸留には膨大な計算資源が必要になる。ここでAWSが注目したのが、古典的ながら実績の高い「強化学習(Reinforcement Learning)」だ。強化学習はモデルのアクションを報酬とペナルティで評価し、アルゴリズムを改良していく方法だ。従来のファインチューニングは正解をラベル付きデータセットに学習させていたが、強化学習は結果をプログラミングで定義できない主観的なタスクで効果を発揮する。
強化学習での評価は今まで人間がやっていたが、現在はLLMが評価者の思考を学習し、AIエージェントに報酬とペナルティを与えることができる。「人の評価より、高速・低コストで、さらに人より一貫性がある。ステップごとに行なえるので、結果だけではなくプロセスも評価できる。まさにAIエージェントに必要な能力だ」とシバスブラマイアン氏は語る。
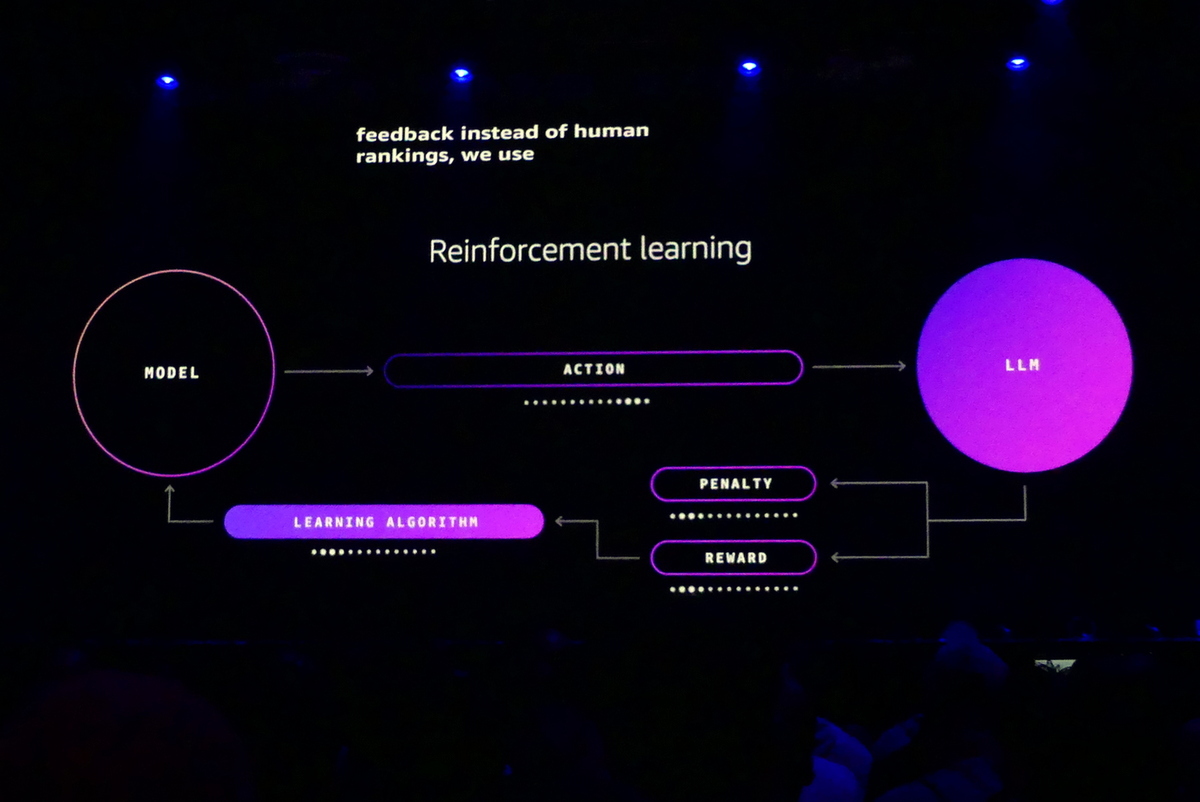
強化学習をモデルのファインチューニングに応用
こうしたAIによるAIエージェントの強化学習を実現するのが、新たに発表された「Reinforcement fine-tuning in Amazon Bedrock」になる。専門知識を駆使して報酬のモデリングとフィードバックの統合を行なわなければならないマネージドサービス化。ベースモデル、データセット、報酬関数を指定するだけ、学習を実行し、ベースモデル比で66%の精度の向上を実現できるという。
Amazon SageMaker AIにもサーバーレスモデルカスタマイズ機能が施され、インフラの管理や合成データの作成などを支援。必要事項を記述するとデータ合成から評価までをガイドしてくれるAIエージェント支援型と、カスタマイズ技術の選択やパラメータ調整まで可能なセルフガイド型が用意される。「今まで数ヶ月要した作業がAIエージェントのガイダンスの元、わずか数日で完了する」とシバスブラマイアン氏は語る。
信頼できるAIエージェントを実現する自動推論
AWSが進めている推論の自動化についても言及された。自動推論の専門家であるAWSのバイロン・クック氏は、「みなさんはどれだけAIエージェントを信頼してますか? お金を正しく送金していると思いますか? 地元の法律を遵守しているか?」という問いを聴衆に投げかける。

AWSのバイロン・クック氏
「AIエージェントにクレジットカードを渡すのは、ティーンエイジャーにインターネットを使っていいよと言うのと同じ」とクック氏は語る。ここでの課題は、LLMではハルシネーションが発生するという問題。複雑なルールや倫理に直面すると、AIはエラーを起す。AIエージェントをだまして、間違った相手に送金してしまうことも可能だ。
しかし、エージェントは自ら考えて、人間の作業を代替するという、その自律性にこそ意味がある。そのための解決策として挙げられるのは、AIエージェントのアクティビティに枠を設けること。その上で、数学的な理論を用いて、推論を自動化し、エージェントの指示やQ&Aのペア出力を検証し、言語モデルをトレーニングすることだという。
たとえば、LLMに「フランスの首都は?」と質問したとき、「ベルリン」と誤った出力が戻ってきた場合、頭文字の「P」をヒントとしてLLMに戻し、「パリ」という正しい出力を導く。AWSではこうした推論の検証ツールを社内で試行し続けているという。
エージェント指向の開発ツールであるKIROでは、自動推論を活用している。また、信頼できるエージェントを実現するためのポリシーを生成できるAmazon Bedrock AgentCoreのポリシーモジュールには、自然言語からCedarの制御ルールを生成する機能が盛り込まれている。
信頼性の高いUI操作の自動化を実現する「Amazon Nova Act」
続いてシバスブラマイアン氏がテーマとして掲げたのは、Webブラウザなどのユーザーインターフェイス操作における課題だ。
ユーザーのUI操作を代替することで、自動化を実現していたのがご存じRPAだ。システム自体に手を入れずに自動化を実現するRPAは多くの企業で利用されているが、複雑なワークフローに対応できず、画面や操作手順が変わると、それに追従できないという課題があり、柔軟性に欠けていた。
AIの登場で、複雑なワークフローへの対応やツールをまたいだ操作の自動化、画面や操作変更への対応能力は大きく変わった。ただ、これを実現するためには、ワークフローやプロンプト、ツールの複雑な連動が必要で、信頼性を確保するのが難しかった。
この課題に対して提供されるのが、WebブラウザのUIワークフローを自動化する「Amazon Nova Act」になる。AmazonのLLMであるAmazon Nova Liteモデルを利用し、自然言語とPythonコードを用いてワークフローを定義。複数のコンポーネントの連携により、信頼性の高いUI操作の自動化を実現する。「90%の信頼性を実現し、パフォーマンスもよくなる」とシバスブラマイアン氏はアピールする。

UI操作の自動化を実現するAmazon Nova Act
AIを用いた他の自動化とAmazon Nova Actはどこが違うのか? 複数のコンポーネントを用いたエンドツーエンドの自動化を実現するという特徴のほかに、トレーニング方法に強化学習が用いられているというところが大きい。「従来は模倣学習を使っていたが、人間の操作は模倣できるが、操作の因果関係を理解していなかった。そこでAmazon Nova Actでは強化学習により、ワークフローを学習できるようにした」とシバスブラマイアン氏。実際は業務のデジタルツインになる強化学習ジムを構築し、アクションに対する報酬とペナルティを受けながら、エージェントにワークフローを学習させるという。
さまざまな作業を人間の操作なしで自律的に行なうAIエージェントは、果たして人の仕事を奪うのか? これに対して、シバスブラマイアン氏がアピールしたのは「チームメイトとなったAIエージェント(Agentic Teammate)は、人間の能力を増幅する」というメッセージだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります