



第849回
d-MatrixのAIプロセッサーCorsairはNVIDIA GB200に匹敵する性能を600Wの消費電力で実現
2025年11月10日 12時00分更新
SRAMでカバーしきれない分は
外付けのLPDDR5でカバー
下の画像の左側がDIMCの内部、右側がSIMDとDIMCの連動の様子を示したものである。WeightはDual Bit-Serialの形で、64bitのWeight Bufferに入力されるのだが、その各bit毎に乗算器と加算器のペアが構成されている。
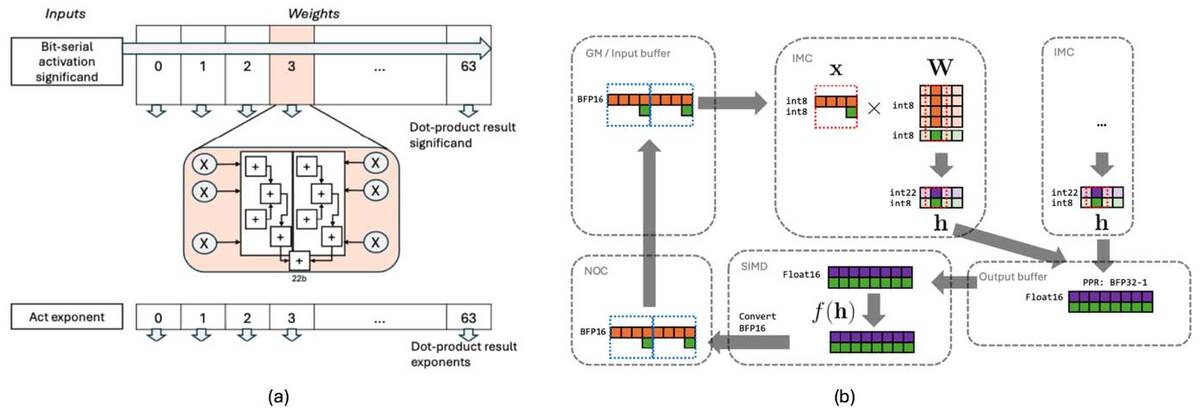
Vector SIMDに関しては、さすがにバッファは別に用意されている。これは、すべてのDIMCの出力が同時にVector SIMD稼働時に用意されるわけではなく、またデータの並び替え、あるいは変換が入るため、別にバッファを用意した方が便利と判断されたのだろう
このペアは4bit/8bitのすべての演算をサポートしている。加えてPPR(Partial Product Reduction:部分積縮小)エンジンも用意されており、これと組み合わせることでx1/2/4/8構成のDIMCに対してPPRを実行できるというものだ。
ここでポイントになるのは、要するにSRAMベースといっているメモリーとは、実際には乗算器/加算器のラッチとして実装されているということだ。
つまりSRAMに重みなりデータなりを格納し、それを演算器が持ってきて処理をするのではなく、SRAMに重みなりデータなりを格納したその時点ですでに演算が始まっていることになる。これが同社の言うところのDigital In-Memory Computingという仕組みなわけだ。
ちなみにVector SIMDの方は? というと、右図のようにむしろ演算というよりもデータ変換のために利用されているのがわかる。ほかにもアクティベーションなどが搭載されており、同社の説明によれば「計算集約的な三角関数・超越関数・縮約演算を含む線形/非線形活性化関数の高速化向けにカスタム設計されている」とある。逆に言えば、通常のSIMDに期待されている数値演算的なものは最初から考慮されていないようだ。
Apollo Coreを2つ搭載するスライスであるが、4つのスライスは相互に接続できるようになっている。これをつかさどるのがNOC(Network On Chip)機能で、これでスライス同士の通信のみならず、スライスに用意されているRISC-Vコア+Dispatch Engineとの接続もこのNOCがつかさどっているように見える。
さらに言うと、このスライスを4つまとめたクワッド同士の接続もNOCが担っているが、このクワッドの中のNOCとクワッド同士のNOCは同じもの、つまり階層分けされていないようだ。
話を戻すとクワッドに設けられたRISC-VコアとDispatch Engineの用途分けは明確には示されていない。おそらくはクワッドで行なうべきプログラムの処理解釈そのものはRISC-Vコアが行ない、ここでDIMCが行なうべき処理を切り出したうえでDispatch Engineに発行。Dispatch EngineはそれぞれのDIMCに対する命令を生成してNOC経由で送り出す、という形になっているものと思われる。
構造から言えば1つのApollo Coreに対しては同時に1つの命令しか発行されず、8つのDIMCはこれを解釈して同時に処理する、一種のSIMD的な動作になるはずだ。
したがって、1つのスライスには16個のDIMCコアがあり、クワッドには64個。チップレット全体では256個になる。Corsairカード全体では8チップレットなので、2048個のDIMCコアとなる。1サイクルあたり2048×64×2=256KOps/サイクルとなる計算だ。
もっともこれはMXINT8を使った場合の話で、MXINT4では64×128のMatrix Opsが可能とあるので、その場合は512KOps/サイクルとなる。なお、ここで言うOPS(Operations Per Second)は、演算回数を表す一般的な指標である。

データ型はOCPのMXフォーマットに準拠している。Block FPもサポートされる
チップレットの動作周波数は1.167GHzとなっており、チップレットあたり300TOPS(INT8)ないし600TOPS(INT4)であり、8つ搭載されるCorsairカードでは2400ないし4800TOPSという計算になる。ちなみに筆者はOPSと書いたが、データはMXINTでも係数はMXFPなので、結果として演算は浮動小数点になるため、FLOPSと書いた方が正確なのだろう。
SRAMとしては、一番高速なメモリーはDIMCそのものであるが、これとは別にStashあたり6MBのWeight Bufferと4MBのGlobal Memoryが搭載される。よってスライスあたり16MB、クワッドで64MB、チップレット全体では256MBとなる。

チップレット全体では256MBとなる。他にRISC-Vコア用のメモリーもあるはずだが、これは勘定に入っていない。LPDDR5だけで動作するとも思えない
ほかにStashあたり64KBのInput Bufferと128KBのOutput Bufferがあり、これも計算に入れると総計で約262MBとなる。AIチップとしてはそう多いSRAMメモリー量とも思えないが、これでカバーしきれない分は外付けのLPDDR5でカバーする形だ。LPDDR5はチップあたり32GB品を利用しており、カード全体では8チップで256GBとなる。
ちなみに性能/消費電力の関係だが、同社によれば800MHz近辺まで下げると、消費電力はほぼ半減するとされている。
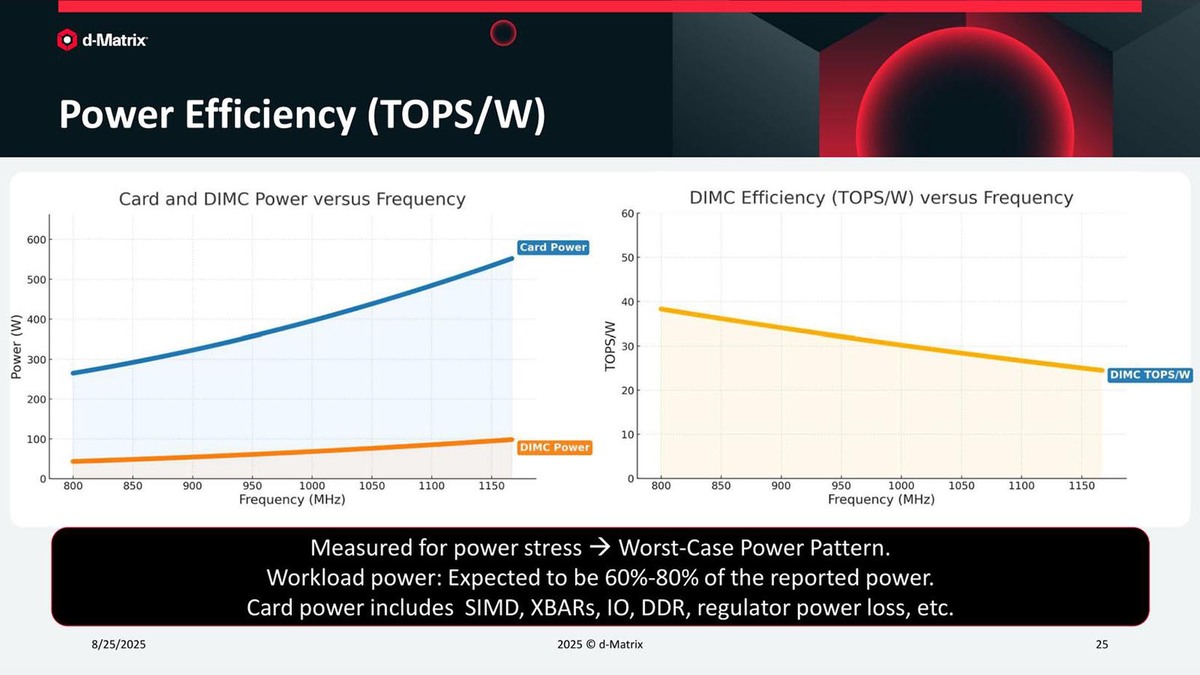
性能/消費電力の関係。左グラフのDIMC Powerは、チップレットあたりのPeak Powerらしい。下の脚注にも"実際のワークロードでの消費電力は図の60~80%"との注意書きがある
IEEE Microに収録予定の"Corsair: An In-memory Computing Chiplet Architecture for Inference-time Compute Acceleration"によれば、チップレットの消費電力は800MHz駆動時に24W、1167MHz駆動で48Wと報告されている。発表では競合製品との比較はなかったが、論文の方ではLLMとしてLLama3-70BをCorsair Card×8とH100×8で実施した場合の比較が以下のように示されている。
- レイテンシーはCorsairがH100の9.7倍低い
- 性能/消費電力比はCorsairが1.8倍良い。ただH100は700W、Corsairは600Wであり、これを加味すると2.2倍まで向上する
- そのほかのテストを行なった平均ではCorsairはH100の6.9倍高速
悪い数字ではないが、もう少し性能/消費電力比の改善が期待されるが、製造プロセスがTSMCのN6(実質的には7nm世代)というのも多少は影響しているのだろう。これを微細化できれば、もう少し性能/消費電力比は改善するだろう。
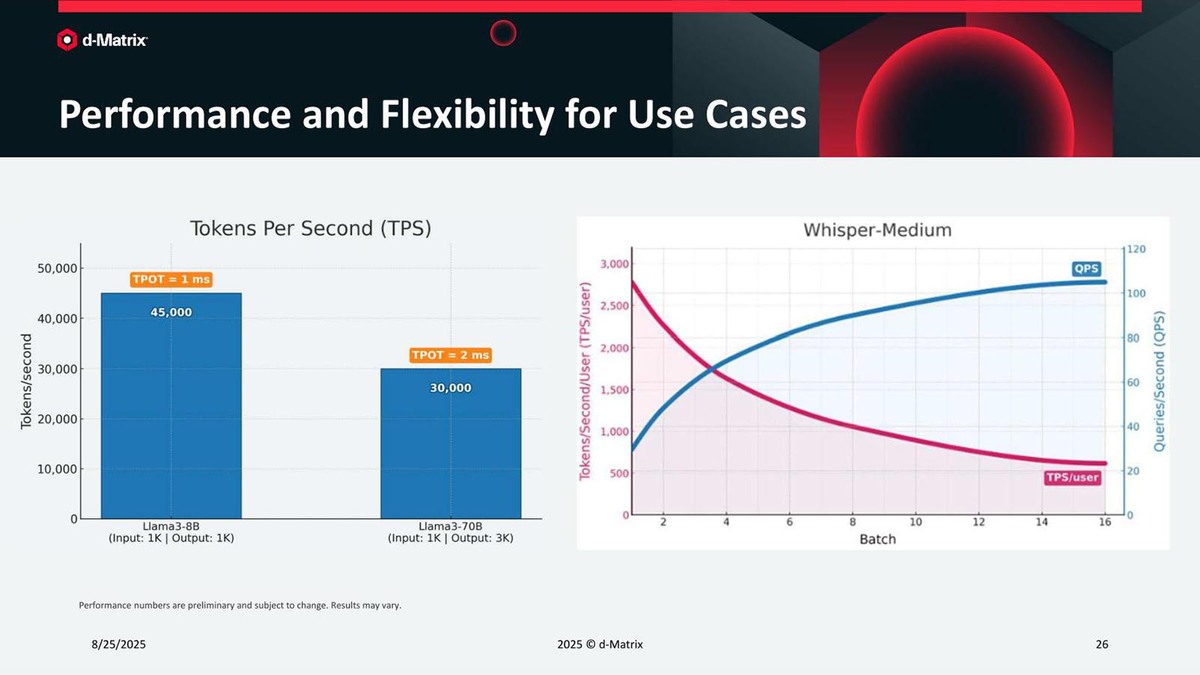
これはあくまでCorsair単体での性能。Llama3-8Bが4万5000 Tokens/秒は悪い数字ではない
d-MatrixはこのCorsairの販売をもう開始している。さて、どの程度顧客を集められるだろうか?
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります