



第846回
Eコア288基の次世代Xeon「Clearwater Forest」に見る効率設計の極意 インテル CPUロードマップ
2025年10月20日 12時00分更新
コア数が多すぎてメモリー帯域が不足
3次キャッシュを搭載して帯域不足を緩和
おもしろいのはここからだ。Eコアは4つのコアで1つのモジュールを構成するというのはこれまでと同じなのだが、4つのコアが1つの2次キャッシュを共有することも、そのサイズが4MBなのもCrestmont世代と変わらない。
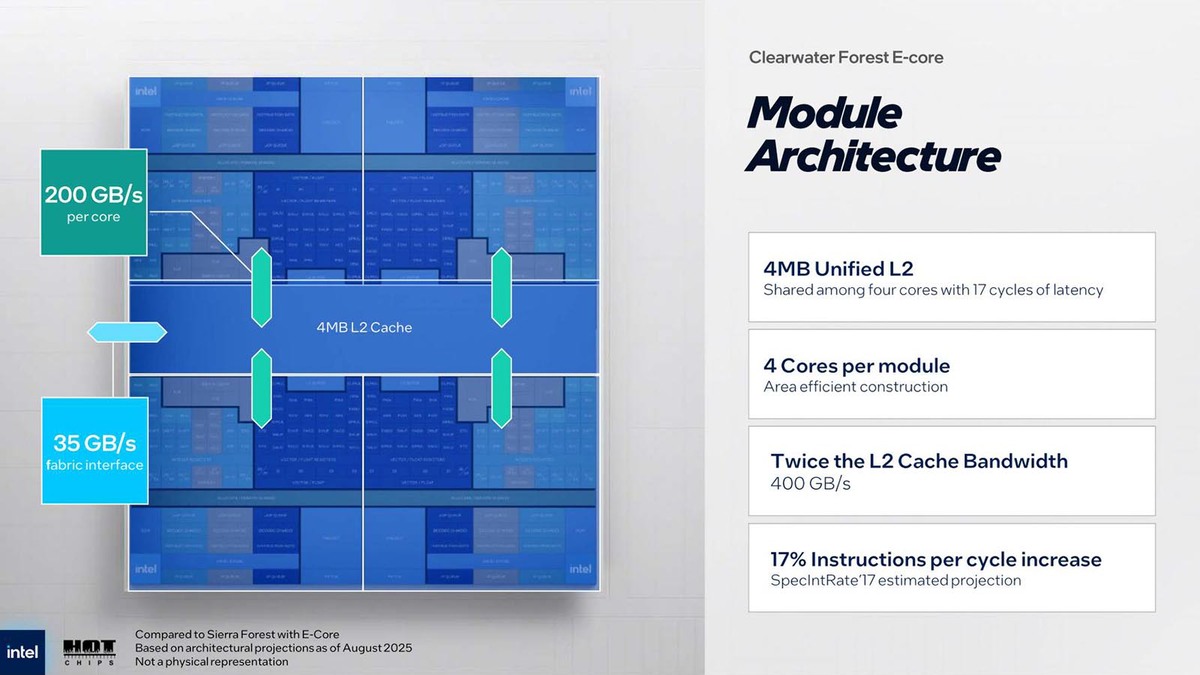
Hot Chipsでは「2次キャッシュと3次キャッシュが直接連携しているのか?」という質問が出たが、発表者のDon Soltis氏(Fellow, Xeon E-core Processor Architect)からの答えは「1つのソケットに8MBのスライスが72ある」であり、連携されている、いないの返事はなかった
ただ、コアと2次キャッシュの帯域が200GB/秒と高速なのに対し、ファブリックのI/Fが35GB/秒しかないというのはかなりギャップが大きい。なぜなら、後で説明するようにファブリックの先に3次キャッシュがあるからだ。
35GB/秒というのはファブリックへの帯域としてはそう悪い数字ではないが、2次/3次キャッシュの帯域としてはかなり厳しい数字である。逆に言えばこの35GB/秒というのは、CPUのパイプラインが3次キャッシュからのフェッチは全然考慮しておらず、外部のメモリーアクセスと同じ扱い、ということを示す。
当初は、これとは別になにかしら2次/3次キャッシュの間の接続があるのではないか? などといろいろ調べたのだが、そういうことは皆無であったし、そもそもAtom系列のアーキテクチャーは3次キャッシュを前提とした構成になっていない。
後述するが、Clearwater ForestはDDR5-8000メモリーを12ch装着できるので、合計帯域は768GB/秒に達するが、それを288コアで割るとコアあたり2.67GB/秒程度。モジュール単位でも17.8GB/秒でしかなく、DDR5-4400 1chの半分程度に留まる。
もうこれは純粋にコア数が多すぎてメモリー帯域が足りないのでどうしようもない。メモリー帯域を増やそうとするとチャンネル数を増やさないといけないが、それはプラットフォーム変更を意味するからだ。要するにこのメモリー帯域不足の状況緩和のために3次キャッシュが搭載されているものと思われる。Lunar Lakeのメモリーサイドキャッシュと同じような目的と考えるのが妥当だ。
話を戻すと、そのDarkmontとCrestmontの性能比較として示されたのが下の画像である。絶対性能で言えば最大1.9倍になる、とされるが比較対象は144コアのXeon 6780Eであり、コア数が倍かつIPCが30%向上しても、トータルでは最大1.9倍にしかならないと評したものか、それとも1.9倍になったと評したものか微妙ではある。

DarkmontとCrestmontの性能比較。製造プロセスも動作周波数もコア数も違うのでIPCの比較が難しいところ。Arrow LakeにおけるCrestmontとSkymontのIPCの比は、整数演算で平均1.38倍、浮動小数演算で平均1.68倍とされていた
ただ性能/消費電力比は23%の向上とあるので、絶対的な消費電力そのものは1.9÷1.23≒1.55で1.55倍ほどに増えている計算となる。Xeon 6780EがサーバーモードのTDPが330Wとされるので、そのまま掛け算すると511.5W。実際には500Wあたりを目指しているものと思われる。
というのはすでにPコアXeon 6ではTDP 500Wのモノがある(例えばXeon 6960P)からで、500Wに抑えればこのPコアXeon 6のプラットフォームがそのまま利用できるためである。
さて次はもう少し全体について。コンピュートタイルには6つのモジュールが搭載される。それぞれのモジュールには4MBの2次キャッシュが搭載されているから、タイル全体では24MBの2次キャッシュになる。このコンピュートタイルが全体で12個あるから、288MBの2次キャッシュになる計算だ。

左上のオレンジで囲まれたモジュールの中央横方向に走っているのが2次キャッシュで、その2次キャッシュを上下に2つずつのコアが配されるという、2つ上の画像そのままの配置なのがわかる。Foveros 3Dの接続は、6つのモジュールを囲む領域部分が使われるのだろうか? 35GB/秒/モジュール程度の帯域ならこれで十分という気もする
Intel 3プロセスで製造されるアクティブベースタイルの構造が下の画像だ。中央に4分割された3次キャッシュが配され、左右はEMIBによるチップレット接続用PHYが、上下にはDDR5メモリーコントローラー×4が配される。実のところなぜここにLLCを設けたかと言えば、1つにはメモリー帯域がコア数に対して圧倒的に足りないので、これを少しでも補う必要があるだろうが、もう1つは「もったいない」もあったはずだ。

アクティブベースタイルの構造。これを見る限り、やはりコンピュートタイルとの接続はコンピュートタイルの周辺部を利用しているものと思われる。LLCの中央に接続部があるようには見えないからだ
このベースタイル、縦の高さはEMIBのPHYで決まっているので縮小できないし、横の幅もDDR5のPHYがあるからこれ以上狭められない。なによりコンピュートタイルを載せるから、これ以上縮小するのは不可能である。ただ、EMIBとDDR5だけならIntel 7で製造しても良かったはずだ。その方が安価でもある。
もちろん、Intel 7ではLLCを構成した際に192MBの容量を確保するのは難しかったかもしれないが、その場合はすっぱりと諦めて電源供給用に徹するという案もあった。Meteor Lakeのベースタイルで採用されたPower Deliveryである。上の画像でLLCになっている部分を全部3Dキャパシタにして、コンピュートタイルへの電源供給を改善させるという案である。ただここで引っかかってしまうのが、コンピュートタイルはIntel 18Aを利用しているということだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります