



第838回
驚異のスループット! NVLink Fusionで最大900GB/秒を超えるデータ転送速度を実現する新世代AIインフラ
2025年08月25日 12時00分更新
今週から何回か、2025年8月21~22日に開催されたHot Interconnects 2025での話題を説明したい。
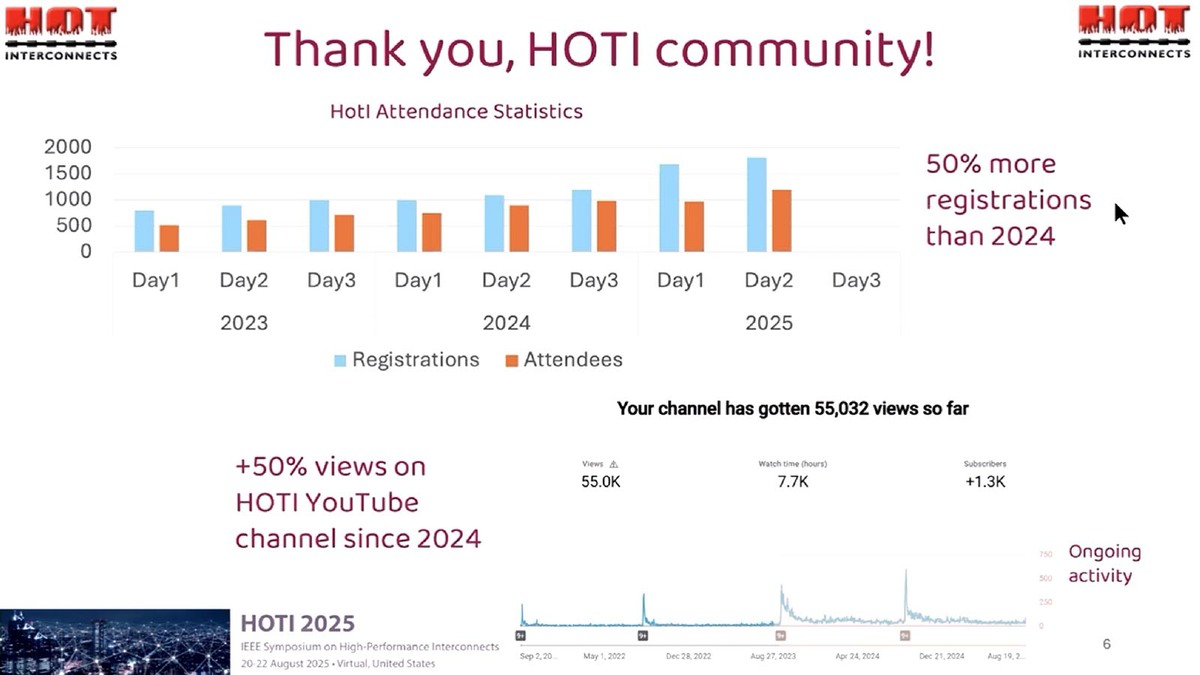
2日のクロージングの際のスライドより。Day 1・2が発表であり、Day 3はチュートリアルのみである。今年は大物が2日目に集中したので妥当な参加人数だろう。難点を上げると、日本からだと深夜1時からのスタートというあたり
Hot Interconnects絡みの記事は連載681回でSlingshot-11を取り上げた。今年もHot Interconnectsはネタの宝庫だったわけだが、無料で参加できる学会のわりに相変わらず参加人数は少ない。とはいえ今年の2日目は1000人を超える参加者があったので、だいぶ認知度は上がってきたのかもしれない。
ちなみに参加はZoom経由、質疑応答はSlack経由となっている。この仕組み、新型コロナウイルス感染症が流行した際に取り入れられた(それ以前は現地のみだった)ものだが好評だったようで、Hot Chipsはハイブリッド(現地参加とオンラインの同時進行)になったのに対し、Hot Interconnectsは引き続きオンラインのみで実施されている。
さてそのHot Interconnects 2025であるが、Day 2の午後のInvited Talk Session("Next Gen Interconnects")でNVIDIAが"Building Custom AI Infrastructure with NVLink Fusion"という講演をしたので、この内容を説明しよう。
複数枚のGPUを連携させる通信技術「NVLink」
まず最初に基本的な話を。NVLinkという名称はご存じの方が多いだろう。もともとはSLIという複数枚のGPU(最初は2枚だったが最終的に4枚まで増えた)を連携して動作させる際に利用されるインターコネクトだった。ただコンシューマー向けのGPUはもうNVLinkには「原則」未対応(例外はある)であり、むしろサーバー向けGPU同士の連携に使われるようになった。
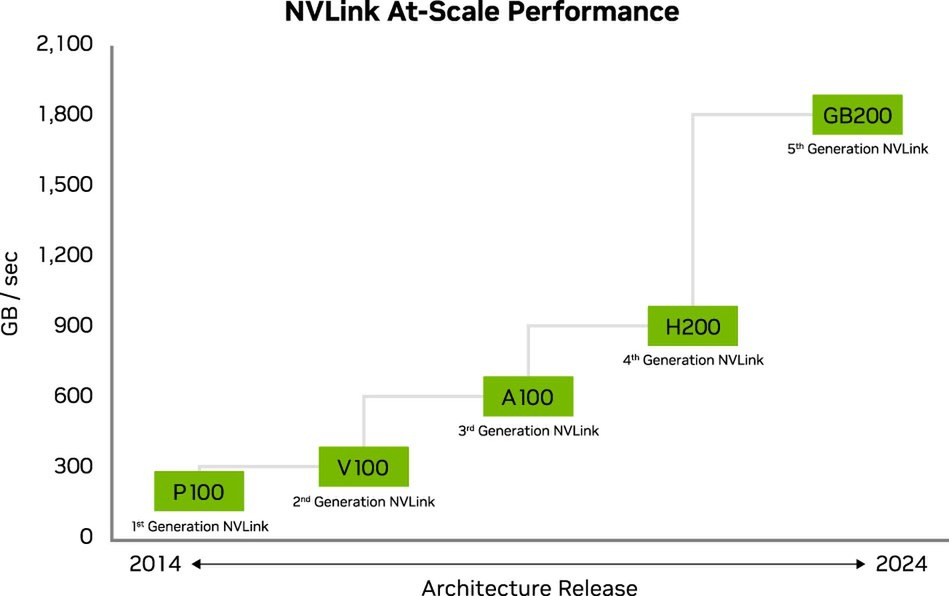
最初にNVLinkとして提供されたのはP100向けでこれが第1世代。以後V100/A100/H200/GB200と世代が変わるごとにNVLinkも進化しており、現在のGB200向けのものが第5世代となっている。
世代で変わるのは速度だけではない。下の画像はP100世代でのNVLinkを利用したGPU同士の相互接続の方法である。8枚のP100は4枚ずつでクラスターを組み、クラスター内は相互接続の形を取り、クラスター間はそれぞれのGPUから1本ずつ接続する形であった。
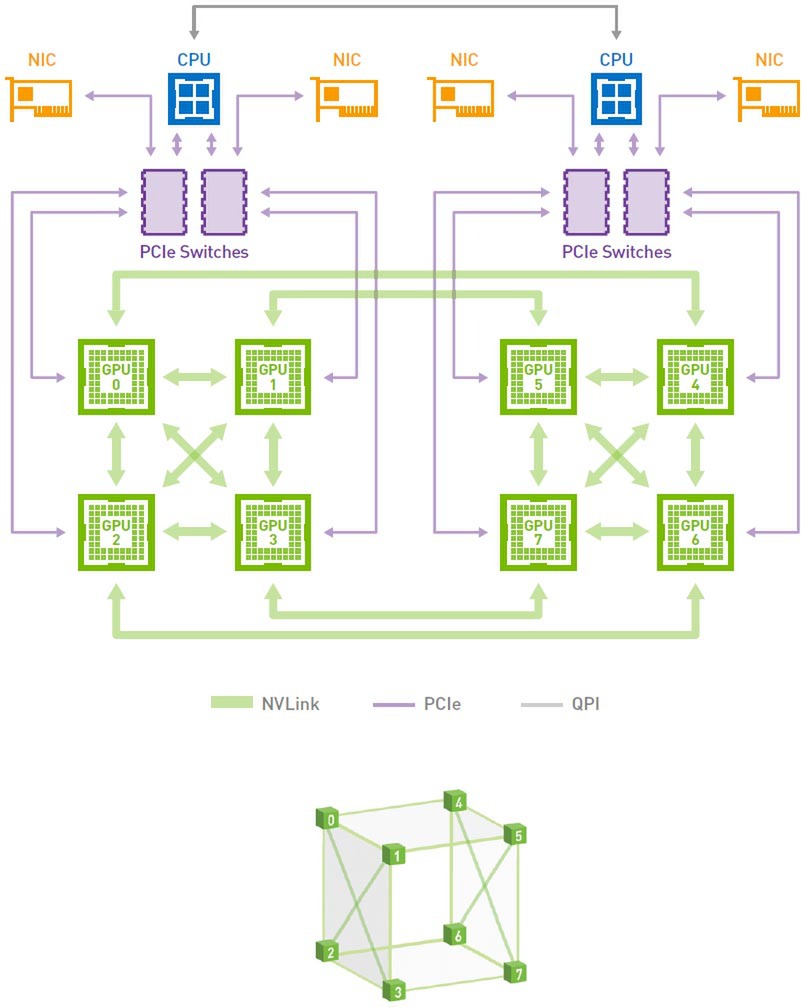
P100世代での相互接続の方法。下の立方体がGPU同士の接続のトポロジーを示している
画像の出典はNVIDIAのDGX-1 System Architecture White Paper
ところがV100の世代、つまり第2世代のNVLinkからは、NVSwitchと呼ばれるNVLink用のSwitchが提供されるようになり、GPUカード同士を直接接続するのではなく、GPUカードとNVSwitchをつなぐ方式に切り替わった。
ちなみにGPU8枚が1つの単位となっており、大規模なシステムの場合はNVSwitch同士を接続することになる。この構図はA100/H100の世代も違いはない。
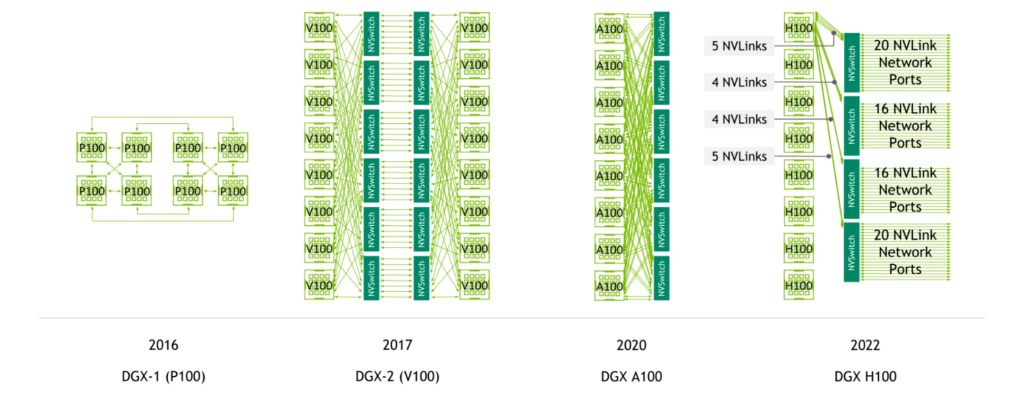
世代ごとにNVSwitchはポート数が増え、速度も向上している
そんなNVLinkとNVSwitchであるが、現在出荷しているハイエンドはGB300 NVL72で、こちらは72枚のGB300カードを18個のNVLink Switch Chipで相互接続する形になっている。なお、NVLink Switch Chip≒NVSwitchとも思うのだが、あくまでチップであってSwitchの筐体ではないのでこの表現なのだろう。
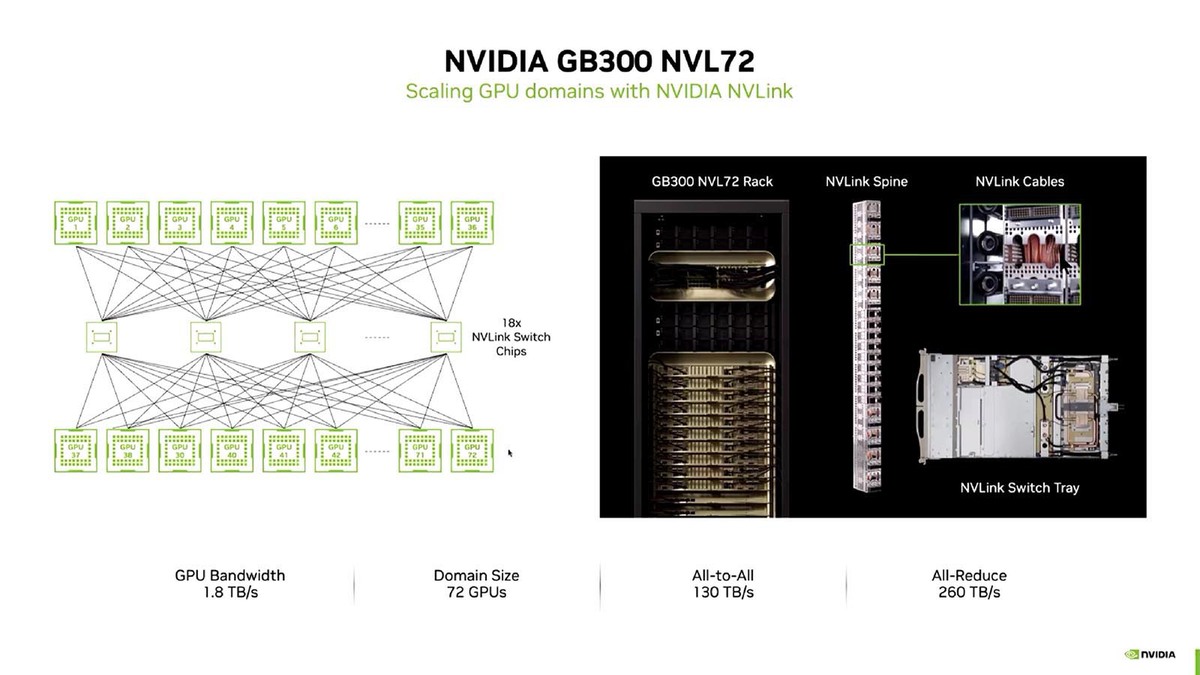
72枚のGPU同士の相互接続に18個ものSwitchというのは力業すぎる気もするのだが、性能を優先するとこうなってしまう、ということでもある
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります