



リングバスの環状線そのものは複線だが
煩雑に乗降が発生するRDU/DDR/HBMの間を複々線化
SN40Lの内部構造が下の画像である。この図そのものは連載792回で説明したものと同じであるが、ここで言うDie-to-Dieは要するにTLN(Top Level Network)同士を接続するためのものである。TLNの構成図は連載792回にも出ていたが、今回はもう少しわかりやすい形で示された。

SN40Lの内部構造。元の論文が間違ってるのだが、図の正確さを保つためには上か下のどちらかのPCIeブロックは左に寄せるべきだったと思う
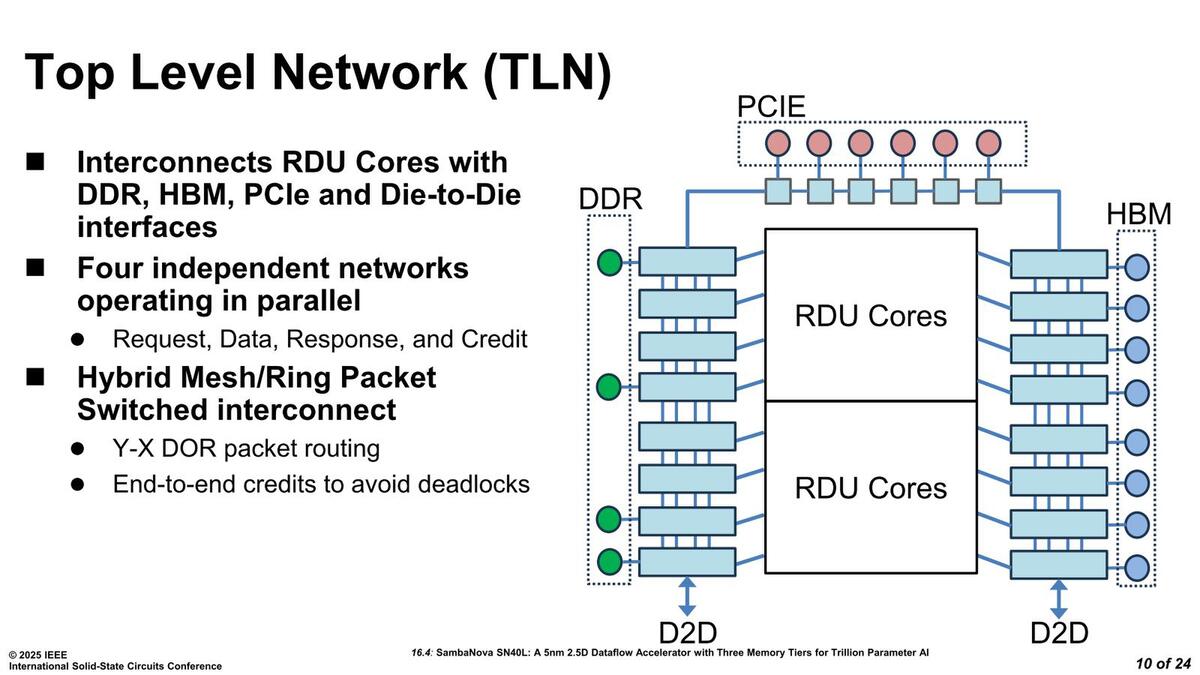
この図では左下もDDR I/Fにつながっているようにみえるが数が合わない。で、連載792回の図では左下は別の接続になっているあたり、おそらくこれはこの図のミスと思われる。DOR(後述)については連載792回の図の方がわかりやすい。RDUコアを貫くように横方向のネットワークが用意される
1つのチップはリングバスの半分が実装されており、ここにトータルで22ヵ所のリングストップが設けられている。うち左右に8つづつあるリングストップは、それぞれがRDUコアにつながっているほか、HBM側は全部がHBMに接続、一方DDR5側はI/Fが3chということで3ヵ所でリングストップと接続している格好だ。
一方PCIeは専用のリングストップに6ヵ所で接続される。ただリングの構造そのものは連載792回の図の方がわかりやすい。端的にには以下のようになっており、さらに上の画像の左右のリングストップ同士が直接接続される構造になっている。
- 全体をカバーするリングは一対(おそらく双方向1本)
- RDU Core/DDR/HBMを接続する部分は二対(おそらく双方向2本)
言ってみれば全体をカバーする環状線そのものは複線だが、煩雑に乗降が発生するRDU/DDR/HBMの間だけ複々線化されているというところか。さらに横方向にショートカットとなる配線が8本用意されている。これはDOR(Dimension-Ordered Routing)と同社では呼んでいる。
このリングバス+DORはハードウェアでルーティング制御されるが、ソフトウェアからこれを上書きする形で制御可能となっている。このネットワーク、構造こそリング+DORで、いわばリングバスに横串を刺した構造になるわけだが、それぞれは完全に独立で動作するほか、内部はRequest/Data/Response/Creditの4種類のパケットでやり取りする方式となっている。
こう見ると4本のバスがそれぞれRequest/Data/Response/Creditに割り当てられているように見えるがそういうわけではなく、それぞれのネットワーク上に4種類のパケットの形でトラフィックを流す構造になっており、そのネットワークが物理的に4つあるという格好だ。
ちなみに資料を見てもcreditの話が出てこないが、End-to-End creditという書き方からして、これはPCI Expressと同じcreditベースのFlow制御(データ転送にあたり、送信側はまず受信側からCreditを取得する。このCreditは「受信側が確実に受け取れる」ことを意味しており、例えば10個分のキューがあるなら受信側はCreditを10個まで発行できる。送信側はCreditを取得したら送信して、これが完了したら受信側にCreditを返す)により、受信側がオーバーフローして受け取れない、というデッドロックを事前に防止できる。
で、上の画像でわかるように複々線状態のバス同士を接続する形で2つのチップを接続してSN40Lは構築される。ということは2チップあわせてリングストップが44ヵ所もある、かなり長大なリング構成になるわけだ。さすがにこれは大きすぎるので、RDUなりHBM/DDRと接続する部分のリングストップ同士を複々線構成にするとともに、DORを構築してショートカットを構築することで、レイテンシーを少なめに保とうとする工夫が見て取れる。
PCU(Pattern Compute Unit)やPMU(Pattern Memory Unit)の構造に関する説明は特に新しい話はない。ただネットワークおよびAGCU(Address Generation and Coalescing Unit)には若干の補足説明があった。

アドレス結合(Coalescing)に関しては論文にも詳細がなかったのだが、そもそもSRAMとHBM、DDRで別々のアドレスを割り当てるのも不便なので、このあたりの制御をするものではないかと想像される。これはHBMをキャッシュとして使う場合と、メモリーとして使う場合でアドレス割り当ての振る舞いが変わることに関係しているのではないか? というのが筆者の推察である
この説明はタイルに関わる部分で、構造は下の画像になる。おのおののRDUの中でPMUとPCUが対になって1040個存在するわけだが、これを囲むようにメッシュスイッチが存在する。
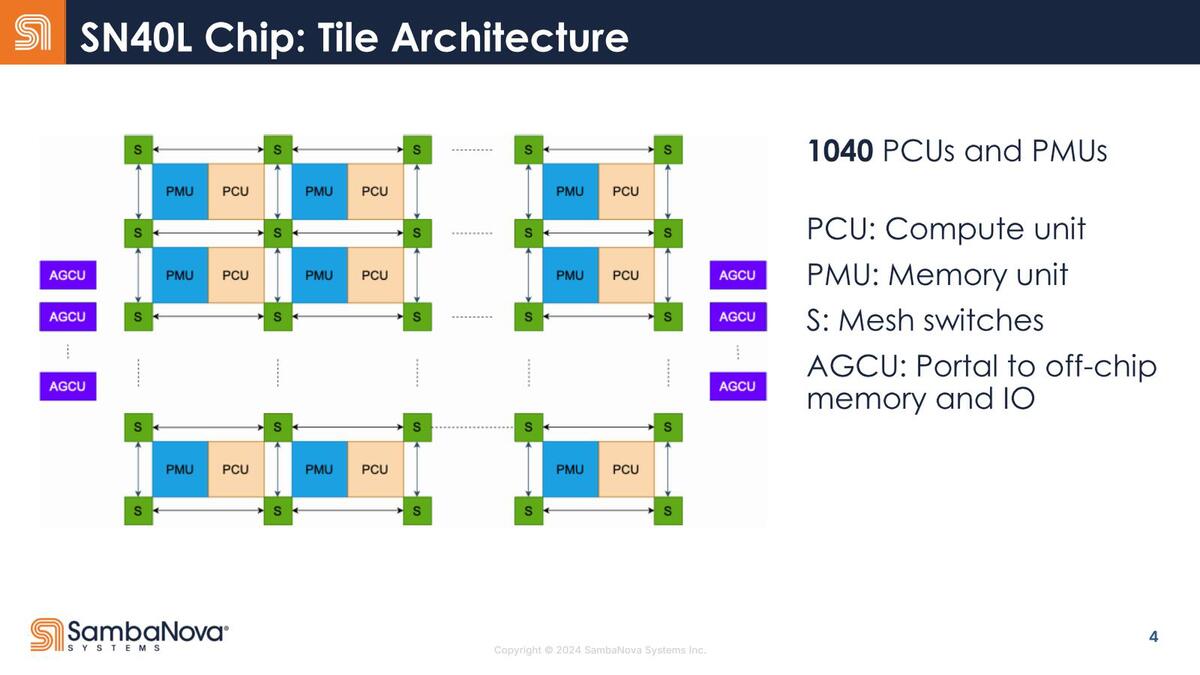
SN40Lは、PCUとPMUが一体化する形でメッシュを構成する
個々のPCUの演算に必要なデータはPMUが用意し、PCUでの処理結果はPCUの最後に置かれたFIFOに収められて次のステージに渡す形になるが、PMUが外部のDRAM(HBM or DDR)からPatternデータを読み出したり、逆に最後のPCUの結果を外部のDRAMに書き出す際にはアドレス指定が必要になる。このあたりを管理するのがAGCUであって、RDUをまたいでの通信やGraph実行の制御などもホストの介在なしにできる、としている。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります