



GeForce RTX 4090 Laptopとベンチマーク比較
GeForce RTX 5090 Laptop搭載ゲーミングノートPC、Razer Blade 16 (2025)で内なる平穏を得る
2025年03月27日 22時00分更新
RTX 5090 LT搭載ノートPCはAI処理も得意
今VRAM搭載量が多くてうれしい用途の筆頭に挙がるものと言えばAI利用だろう。そこで、「UL Procyon」を利用し、AI系のテストを2つ実行してみた。
まずはStable Diffusion XLを利用する「AI Image Generation Benchmark」を試す。1024ドット四方の画像を16枚生成する処理からスコアーを算出するテストだ。APIはデフォルトのTensor RTを使用した。
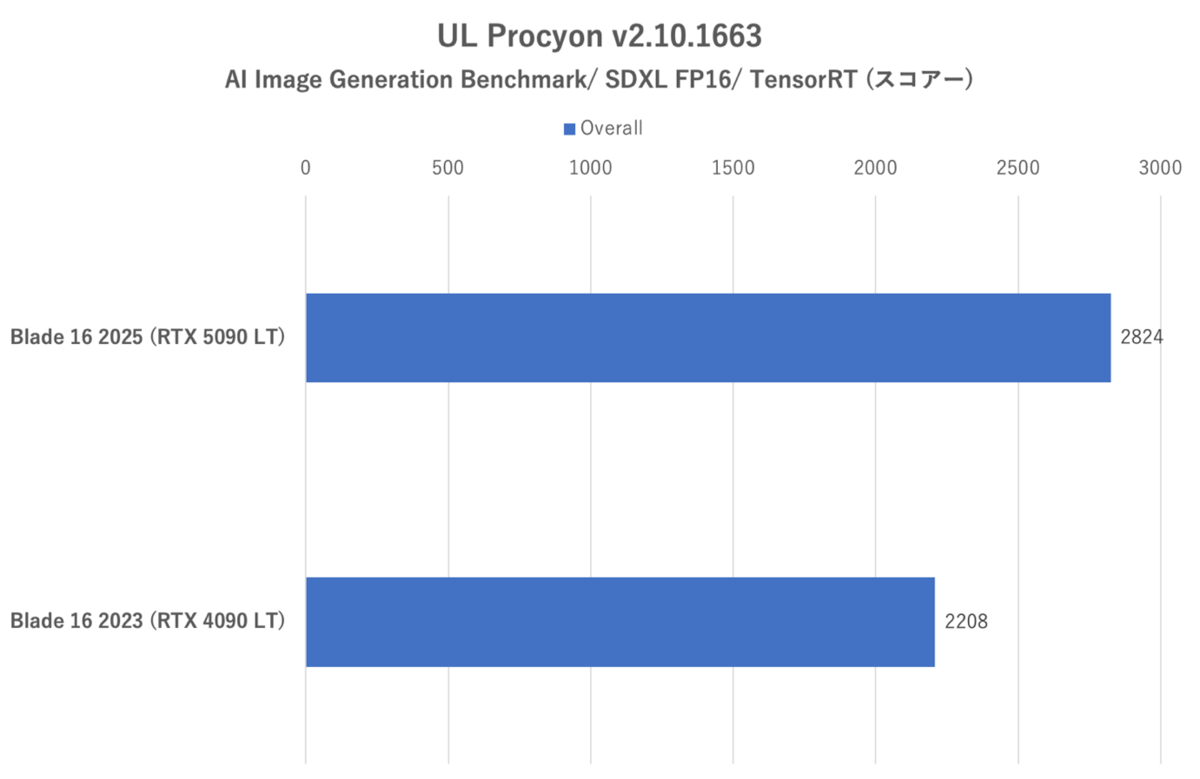
UL Procyon:AI Image Generation Benchmarkのスコアー
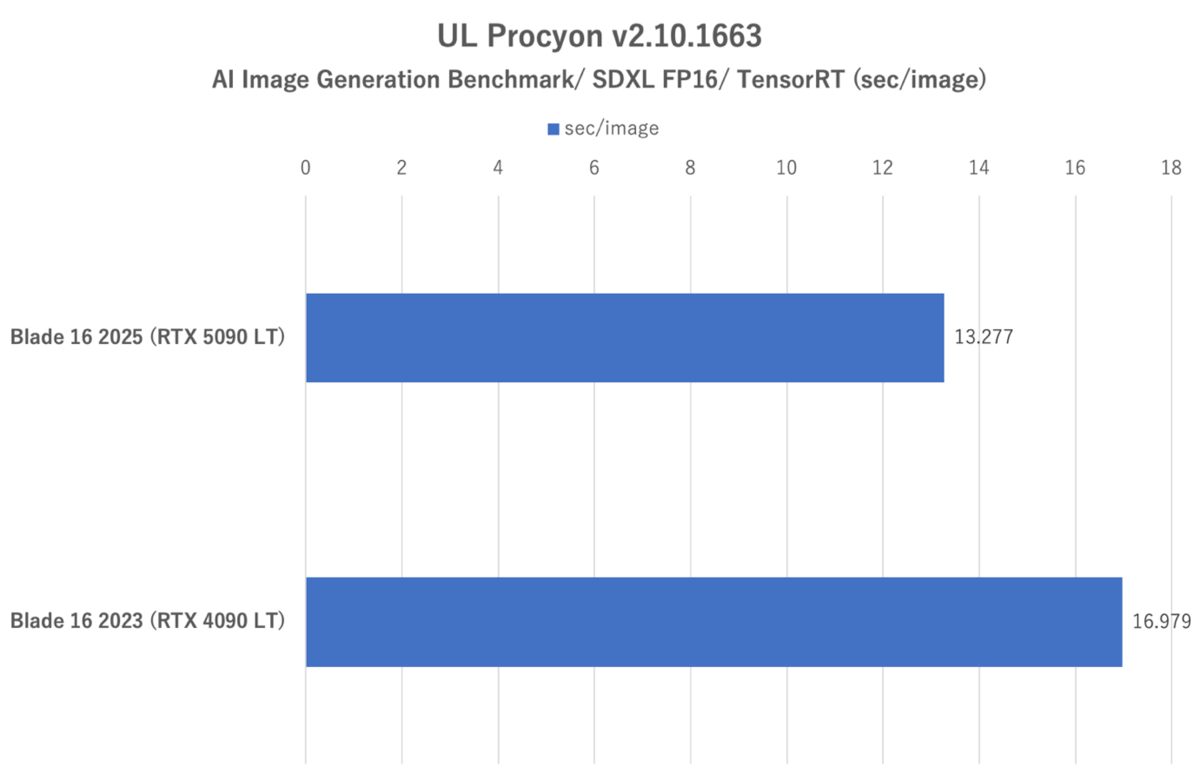
UL Procyon:AI Image Generation Benchmarkにおける画像1枚あたりの処理時間
スコアーはRazer Blade 16 (2023)に比べ、約28%向上。画像1枚あたりの処理時間も相応に短縮されている。こちらも順当に性能が向上していると言える。
画像生成の次はテキスト生成の「AI Text Generation Benchmark」だ。大小4つの学習モデルを用い、それぞれに7つのテキスト生成タスクを課し、その際のトークン生成スピードおよび最初のトークンまでの待ち時間からスコアーを導き出す。
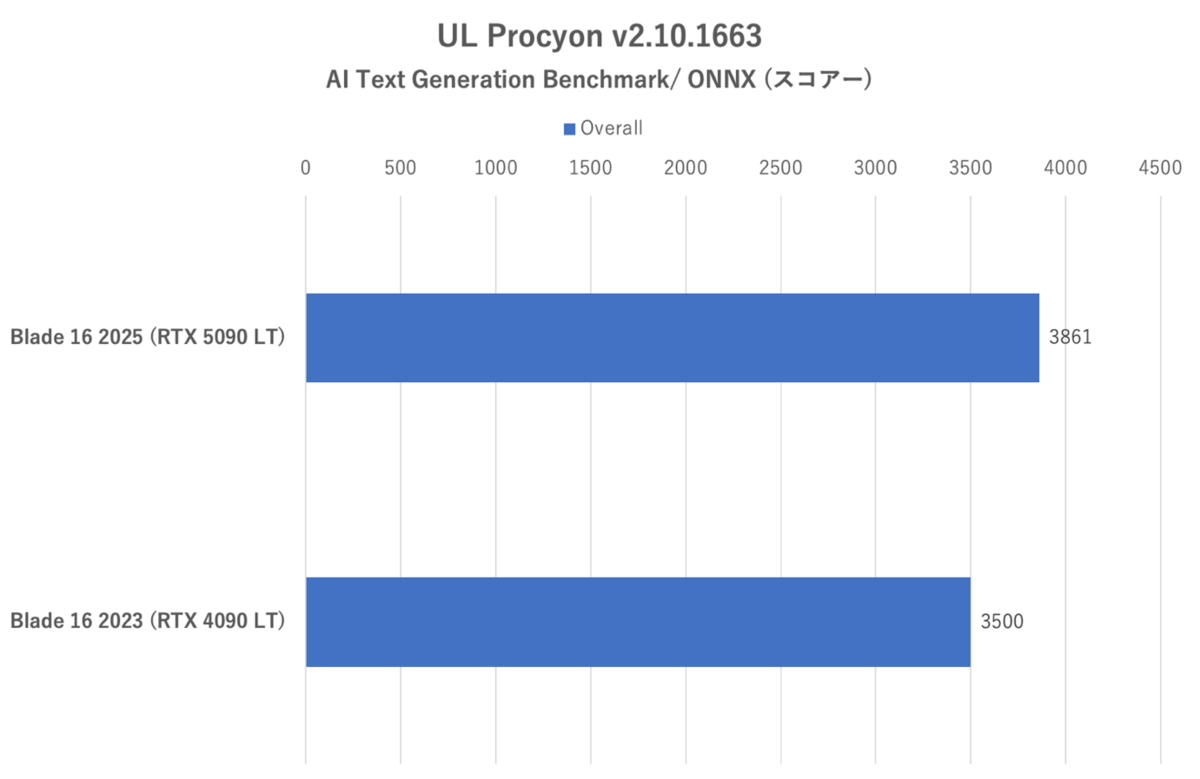
UL Procyon:AI Text Generation Benchmarkのスコアー。学習モデルの重さはPhi-3.5-mini-instructが最も軽く、LLama-2-13Bが最も重い
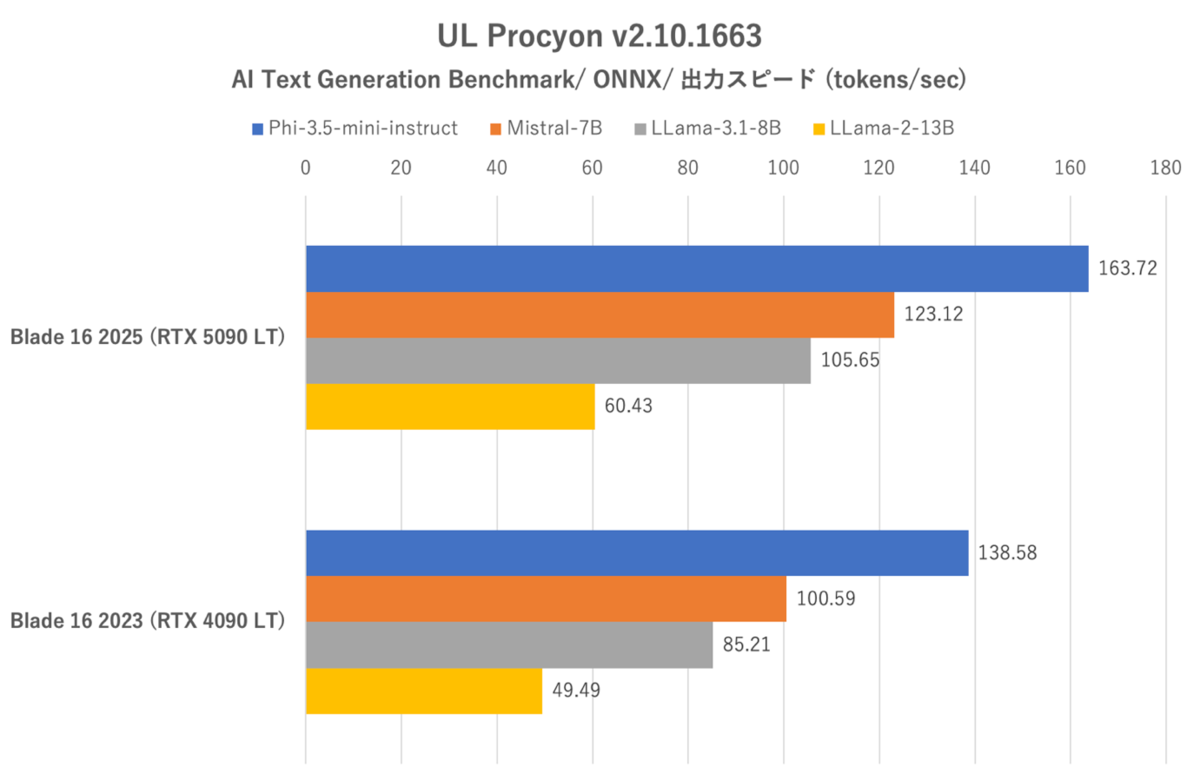
UL Procyon:AI Text Generation Benchmarkにおけるトークン生成スピード。テスト毎に平均値で集計している
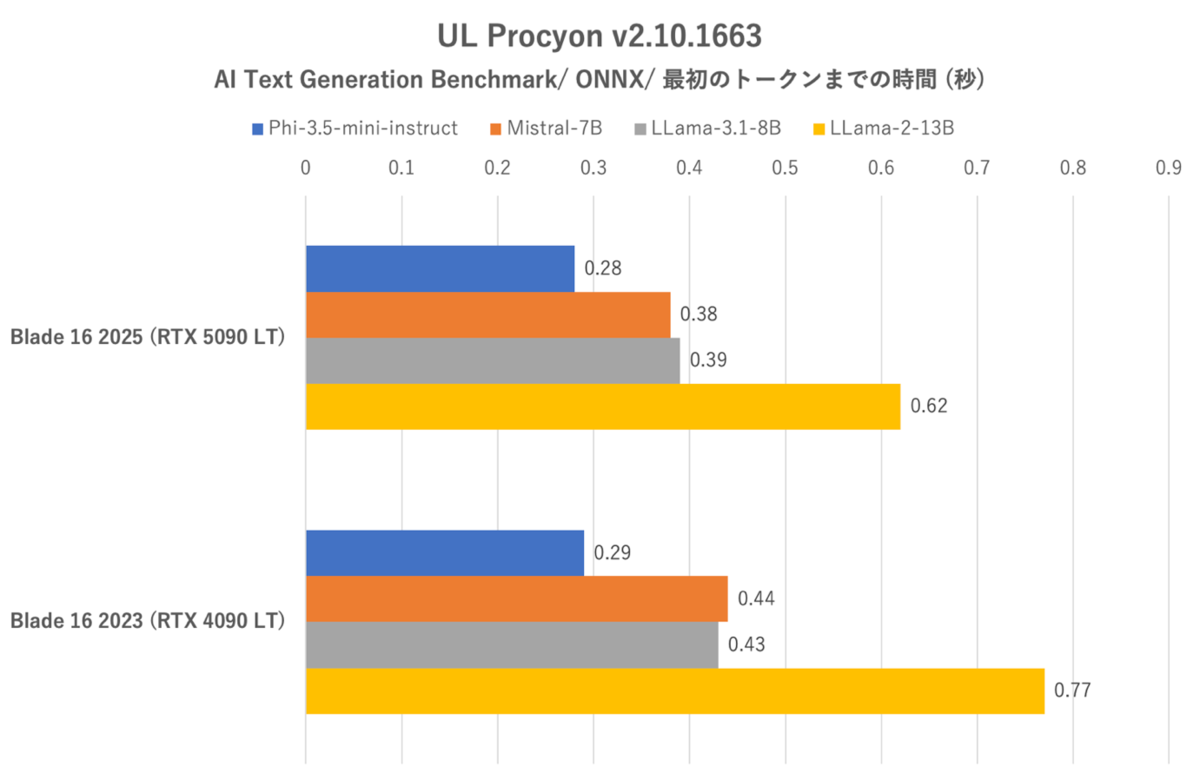
UL Procyon:AI Text Generation Benchmarkにおける最初のトークンまでの時間
確かにRazer Blade 16 (2025)はLLMにおいても前世代をしっかりと上回っている。特にトークン生成スピードにおいては最も軽いモデル(Phi-3.5-mini-instruct)を除けば23%前後向上しているし、最初のトークンまでの時間においてはLlama-2-13Bにおいて顕著な短縮を確認できた。とはいえ、総合スコアーでは10%の伸びに止まっている点は残念だ。
ただし、このテストはVRAMが16GBもあれば余裕で収まってしまうようなテストだ。そのため、もっと大きな学習モデルを利用して負荷をかけないとRTX 5090 LTの本領は発揮できないと考えられる。そこで「LM Studio」を利用してみた。
今回は学習モデルに「Gemma 3 27B instruct」を選択。量子化の度合いが異なる「Q3_K_L」および「Q4_K」の2バージョンで比較する。各学習モデルのサイズはQ3_K_Lが14.34GBで、Q6_Kが21.4GBだ。そのため、VRAM 16GBのRTX 4090 LTではQ6_Kは手に余ることになる。
テストは以下のように、“消えた1ドルの謎”を解説させるプロンプトを入力した。シードは固定し、GPUオフロードは最大(GPUを最大限利用する)に設定。1回回答を得るたびにモデルをロードしなおし、3回の平均値で比較する。
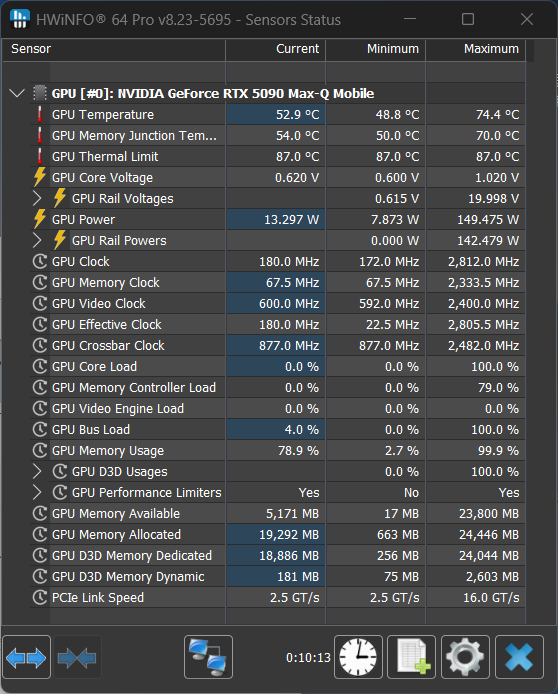
Gemma 3 27B instruct Q3_K_Kを読み込んだ直後のRTX 5090 LTの状態を「HWiNFO64 Pro」で観測した。実際に使用されているVRAMの容量を示唆する「GPU D3D Memory Dedicated」を見る限り、19GB近くは使われていると考えてよい。VRAM 16GBのRTX 4090 LTでは足りないことは明白だが、一応動かすことはできる
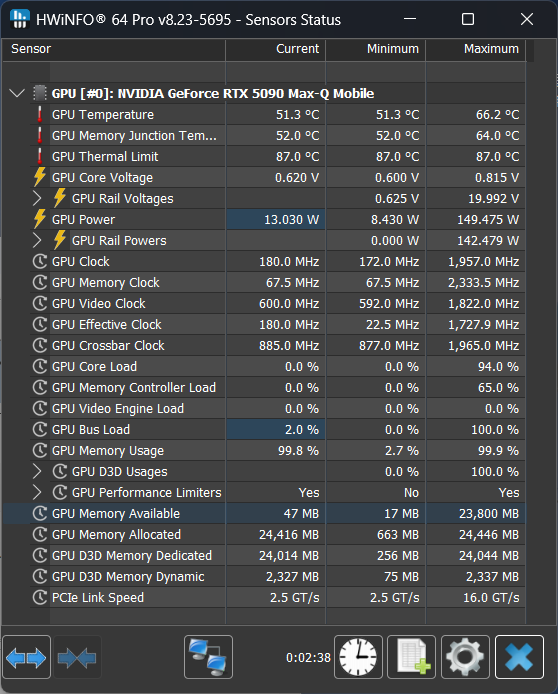
Gemma 3 27B instruct Q6_Kを読み込んだ直後のRTX 5090 LTの状態。こちらは24GBのVRAMのほぼすべてが使われている。ここまで使用量が多いとRTX 4090 LTではどうにもならない
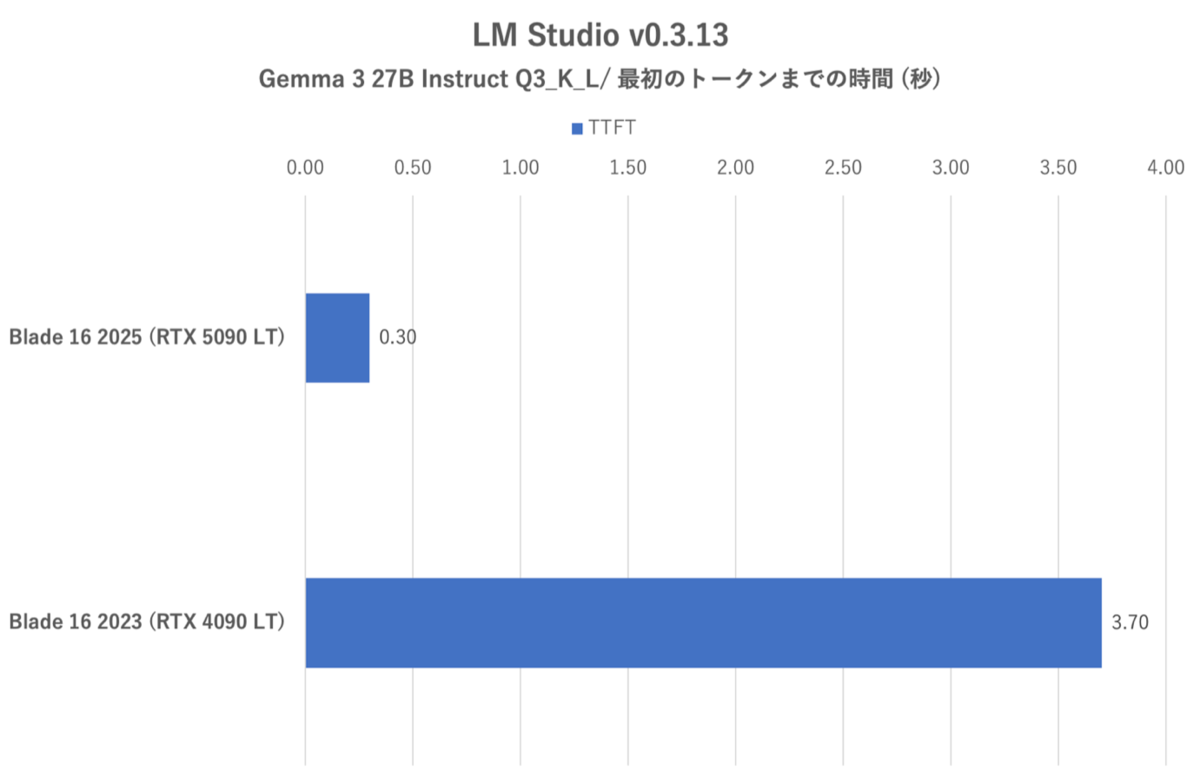
LM Studio:Gemma 3 27B instruct Q3_K_Lにおける最初のトークンまでの時間(TTFT:Time to First Token)
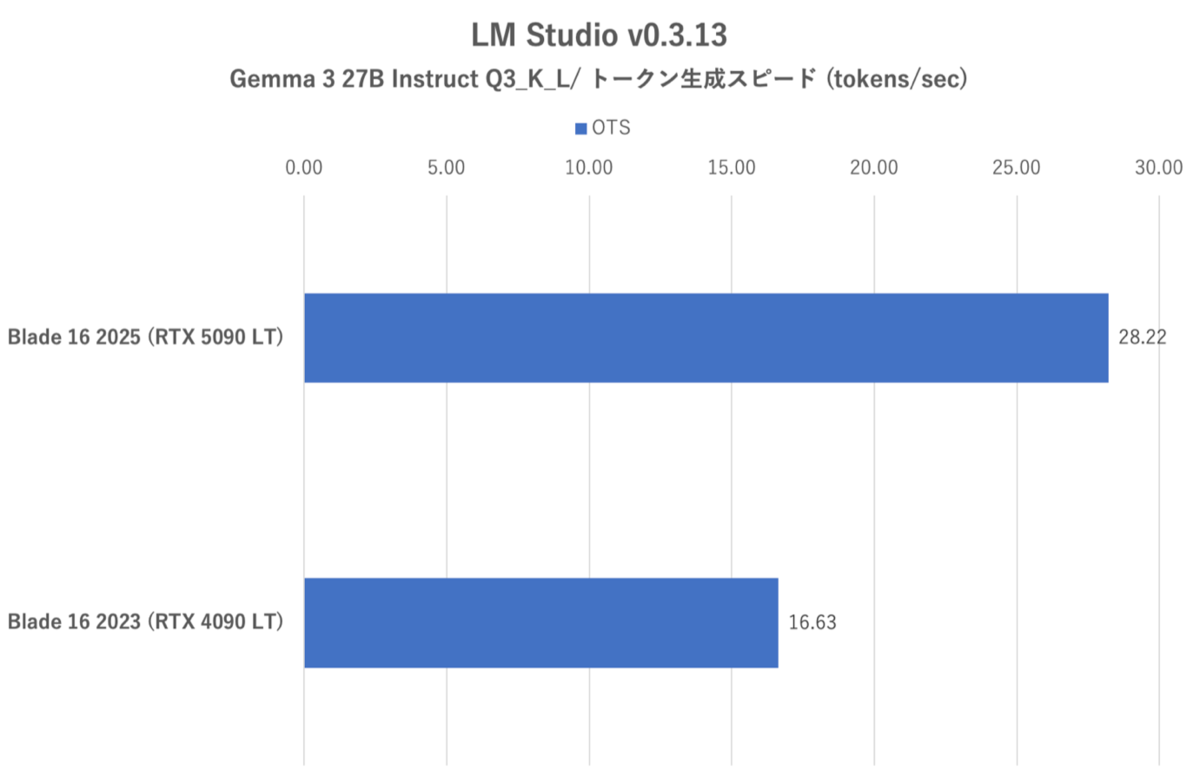
LM Studio:Gemma 3 27B instruct Q3_K_Lにおけるトークン生成スピード(OTS:Output Token Speed)

LM Studio:Gemma 3 27B instruct Q6_Kにおける最初のトークンまでの時間(TTFT:Time to First Token)
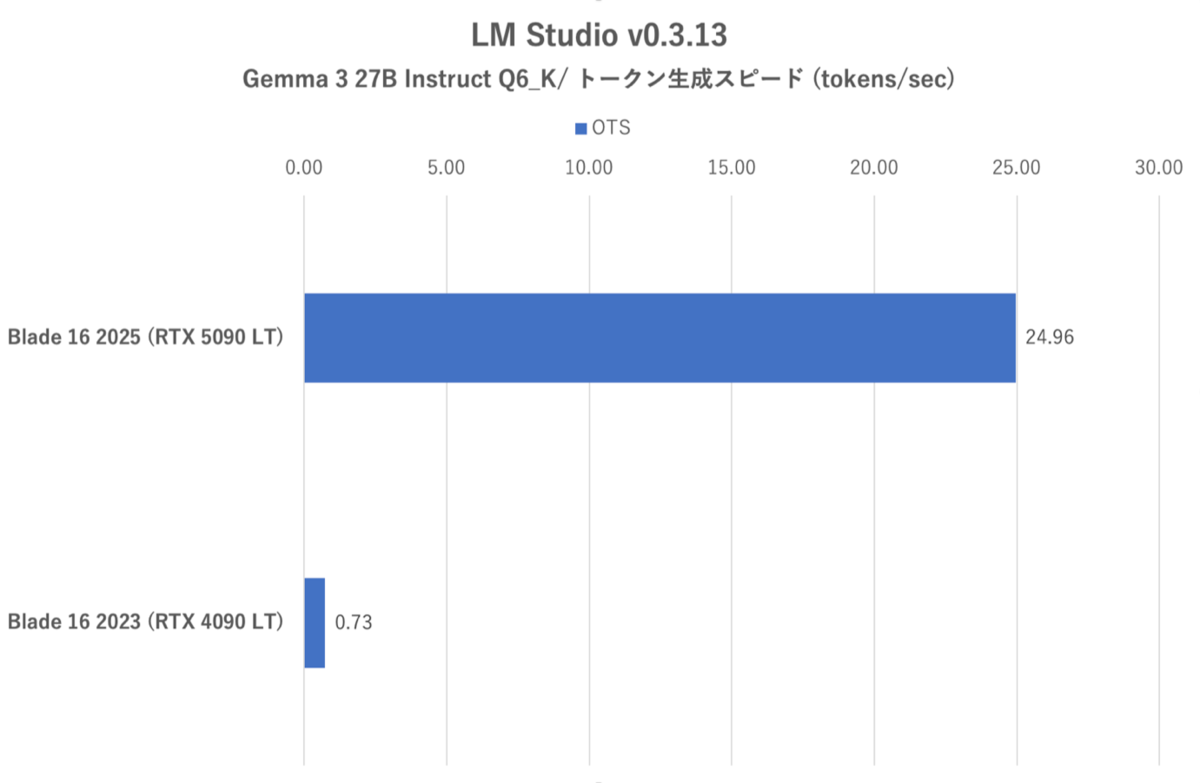
LM Studio:Gemma 3 27B instruct Q6_Kにおけるトークン生成スピード(OTS:Output Token Speed)
今回のテスト条件では、RTX 4090 LTを搭載したRazer Blade 16 (2023)でもQ3_K_Lを利用できた。しかし、それでも応答速度やトークン生成スピードにおいては、RTX 5090 LTを搭載したRazer Blade 16 (2025)が確実に速かった。RTX 4090 LTでは応答に4秒近くかかるが、RTX 5090 LTでは一瞬だった。
そして、Q6_KではRazer Blade 16 (2023)ではVRAMが足りず、1秒あたり1トークンの生成すら危うくなる。GPUオフロードの設定値を中間(最大62中の31)まで下げてCPUも併用すれば、Razer Blade 16 (2023)でもトークン生成スピードを稼げるが、CPU使用率は60%以上になる。トークン生成スピードは3Tokens/secが関の山である。
このようにデータ量の多い学習モデルをローカルで扱いたいという人にとって、VRAM 24GBのRTX 5090 LTは非常に強力な武器となることは言うまでもない。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります