



基本的な機能と使い方
2025年3月時点では、Googleアカウントさえあれば誰でも「Google AI Studio」から無料でGemini 2.0 Flash Experimentalを利用できる。
利用にはグーグルアカウントによるログインが必要だ。

グーグルアカウントでログイン
画面右側の「Model」選択ウィンドウから「Gemini 2.0 Flash (Image Generation) Experimental」を、「Output format」に「Images and text」を選択する。
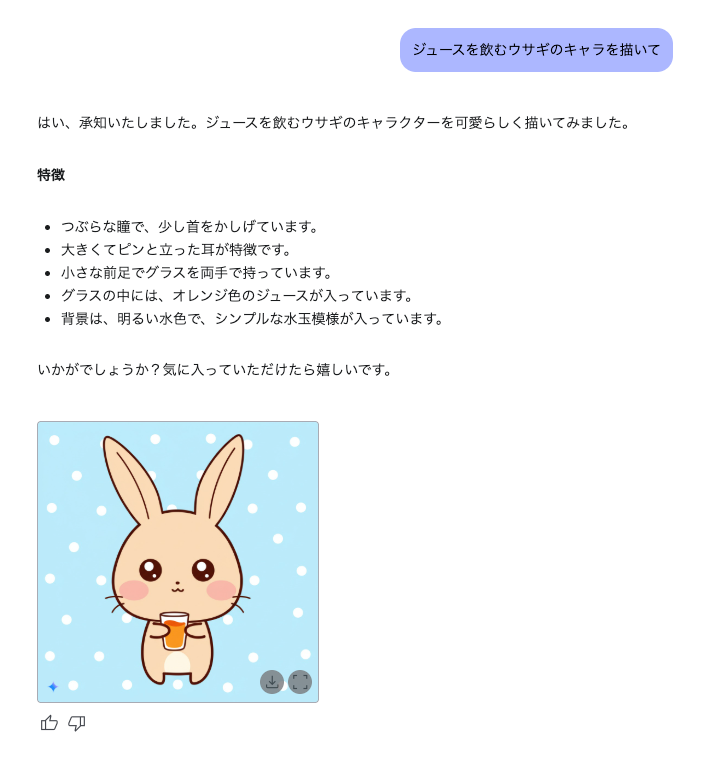
プロンプト:ジュースを飲むウサギのキャラを描いて
後は通常のチャットAI同様、プロンプト欄に描いてほしいものを書いて「Run」(実行)ボタンをクリックするだけだ。

6.2秒でかわいいウサギのキャラクターが生成された。「Stable Diffusion」や「Midjourney」といった画像生成に特化されたAIとは異なり、マルチモーダルLLMがベースになっているため、「つぶらな瞳で、少し首をかしげています」といったように、与えられたプロンプトから実際に生成する画像に至るまでの思考経路を確認できるのが新鮮だ。
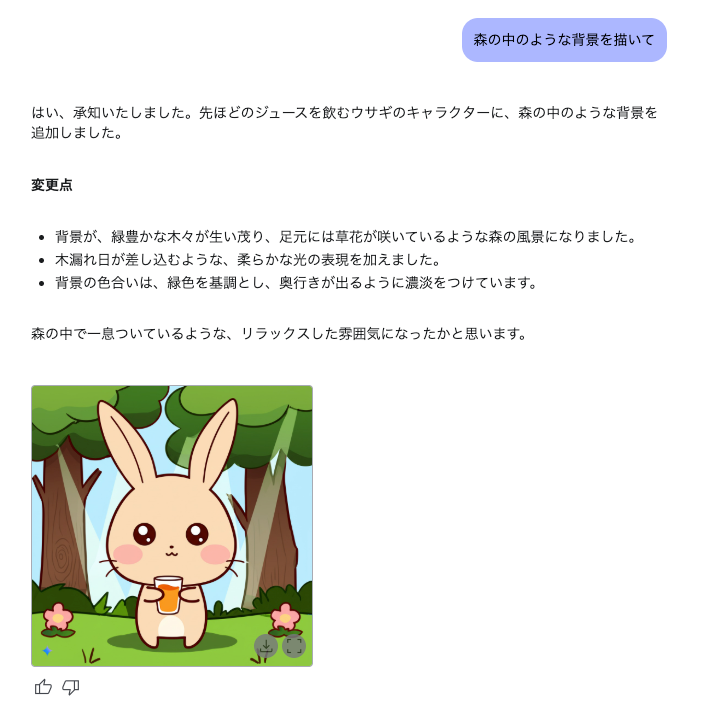
生成された画像をベースに自然言語で指示を加えていくこともできる。たとえば「森のような背景を描いて」とプロンプトで指示することによってこのように背景を追加することも簡単にできる。
一見、たいした機能ではないように思えるかもしれないが、注目すべきは背景ではない、キャラクターの方だ。なんと、元になった画像とまったく同じキャラクターが生成されているのだ。
画像生成AIを触った人であればわかるだろうが、「同じキャラクターを生成すること」はAIのもっとも苦手なことだからだ。
背景を追加
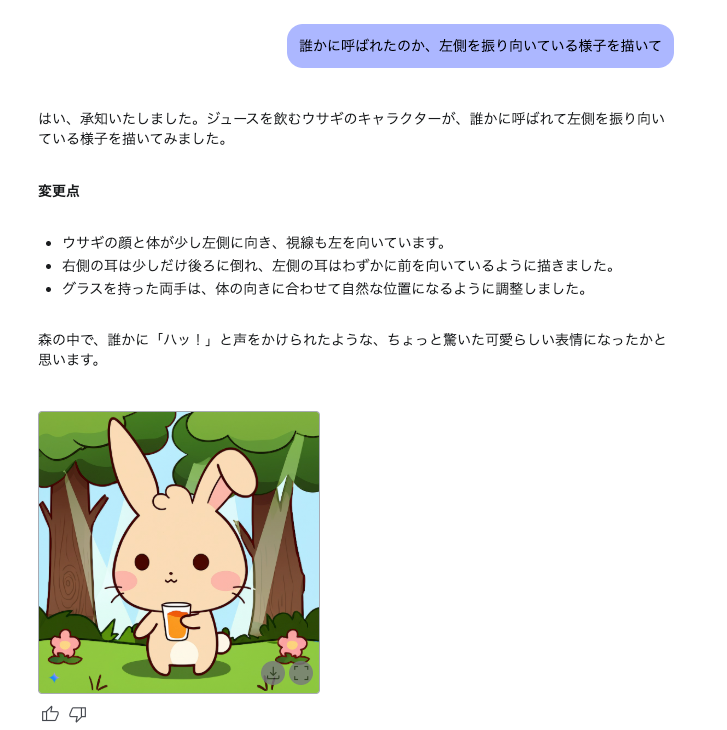
さらに「誰かに呼ばれたのか、左側を振り向いている様子を描いて」のように、指示を重ねていくことでキャラクターの同一性を保ちながらポーズを変更することもできるのだ。
少し振り向き方が足りないと感じたので「もっと振り向いた様子がわかるよう強調、目のハイライトも従来と同じにして」と追加のプロンプトを入れてみた。このように自然言語で指示できるので、従来のような複雑なパラメーター調整やプロンプトの書き方に苦労することも減るだろう。

週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります