



AVX-512を使っていない時は256bit分の電源を落とすことで省電力化
FPUについておさらいだが、AMDはZen 4でAVX-512のサポートを追加した。ただし内部にあるSIMDエンジンのデータパスは256bitのままで、2つのFPUを連携させて1サイクルあたり1個のAVX-512命令を実行可能だった。
これがZen 5世代になると内部のデータパスが512bit化されたことで、1サイクルあたり2つのAVX-512命令を実行可能になった。それはいいのだが、そのZen 5のFPU内部のデータパスが下の画像である。
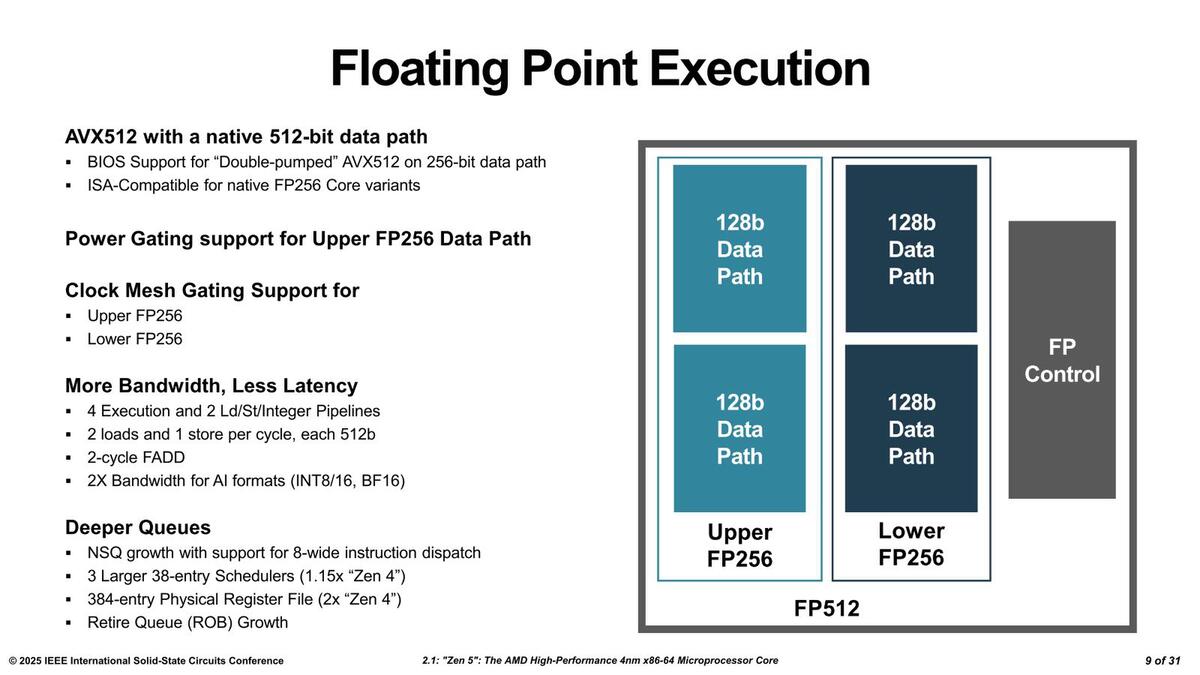
FPUはZen 3世代からADD×2、MUL×2、ロード/ストアー×2という構成になっており、そのあたりはZen 4/Zen 5でも変わらないが、レイテンシーの削減などが細かく行なわれている
今もFPUのデータパスの基本は128bitのままであり、その128bitデータパスを2つずつまとめてUpper FP256とLower FP256として、これをさらに合わせて512bitとしている、ここでおもしろいのは以下の格好になっていることだ。
- Clock GatingはUpper/Lower FP256に対して行なう
- Power GatingはUpper FP256だけ独立に可能(Lower FP256はFPU全体のPower Gatingに従う)
これはどういうことかというと、FPU全体を512bit化してしまったが、その512bitのデータパスを使うのはAVX-512命令を実行しているときだけで、x87 FPUなら原則64bit、SSEでは128bit、AVX-256なら256bitあればいい。したがってAVX-512を使っていない時は256bit分(Upper FP256)はPower Gatingで電源そのものを落とすことで省電力化を図ろうというわけだ。
「だったら64/128bitでもPower Gatingできるようにすればさらに節約できるのでは?」といえばその通りなのだが、Power GatingのためにはPower Planeを分離する必要があるし、Power Gatingのための回路も大きくなる。
そのあたりを勘案すると、AVX-512を利用するときだけ512bitのデータパスを有効にし、それ以外の場合は256bit相当で動作させるというのはバランスがいい選択だったのだろう。Clock Gatingはもっと細かな単位で稼働させられるため、そこである程度の省電力効果は期待できるので、それで良しと判断したものと思われる。
パイプラインのパラメーターが判明
Execute Unitを増量
下の画像はパイプラインのパラメーターで、ここまでそろった形で示されたのは今回が初めてのはず。個々の数字はともかくとして興味深いのは右のグラフである。これはSpecInt 2017をAMDのAOCC Compiler Suiteを実行したときの性能というかIPCを比較した場合の、性能改善の割合を示したものである。

例えばRAS(Return Address Stack)の数が32→52に増やされたという数字はこれまで開示されてこなかったと記憶している。あとOp CacheのAssociativityも初公開のはず(そのわりにOp Cacheの容量はないが)
IC/BP、つまりInstruction Cache/Branch Predictionでも1割強、DE/OC/DI(Decode/Op Cache/Dispatch)で2割強、EX/SC(Scheduler/Execute Unit)で4割弱、LS/DC/L2(Load-Store/D-Cache/L2)で3割弱といったところで、一番効果的なのはExecute Unitを大幅に増やしたことだ。
逆に言えばDE/OC/DIの改善比率がそこまで大きくないというのは、まだDecode/Dispatch段よりも、その後のSchedule/Executeの方がボトルネックになっている可能性が高いことを示している。もっとも無暗にExecute Unitを増やしてもどこまで並列に処理できるのか? はよくわからないわけで、このあたりはうまくバランスを取った結果と考えていい。
週刊アスキーの最新情報を購読しよう