



第814回
インテルがチップレット接続の標準化を画策、小さなチップレットを多数つなげて性能向上を目指す インテル CPUロードマップ
2025年03月10日 12時00分更新
コンピュートタイルはTSMC N16、メモリータイルはIntel 4
ベースタイルはUMCの130nmプロセスを利用
下の画像が実際のタイルの細かい構成である。コンピュートタイルのCPUコアとしてはTensilicaのXtensa LX7が、AIエンジンのコアにはXtensa VP6(Vision P6)がそれぞれ採用されている。メモリータイルはAI処理をさせることもあってか16MBのSRAMが搭載されている。

タイルの構成。メモリータイルはAI処理をするのにメモリーがそれなりに必要であり、それもあって16MBのSRAMを搭載している関係でメモリータイル呼ばわりされているが、本来はアクセラレータータイル扱いにすべきではないのだろうか?
おもしろいのはコンピュートタイルはTSMC N16で製造していることで、一方メモリータイルはIntel 4、そしてベースタイルはUMCの130nmプロセスを利用したものだ。ベースタイルは本当にパッシブタイルで純粋に配線だけがされているようだ。
コンピュートタイルとメモリータイルのもう少し詳細な内部構造が下の画像だ。コンピュートタイルにはPCI Express Gen4のコントローラに加えてPHYまで搭載されているとする。デバッグロジックを新規で開発したのは、複数のタイルで連動して動くような処理のデバッグは、Xtensa LX7に用意されている通常のデバッグ機能だけでは足りなかったのだろうと想像される。
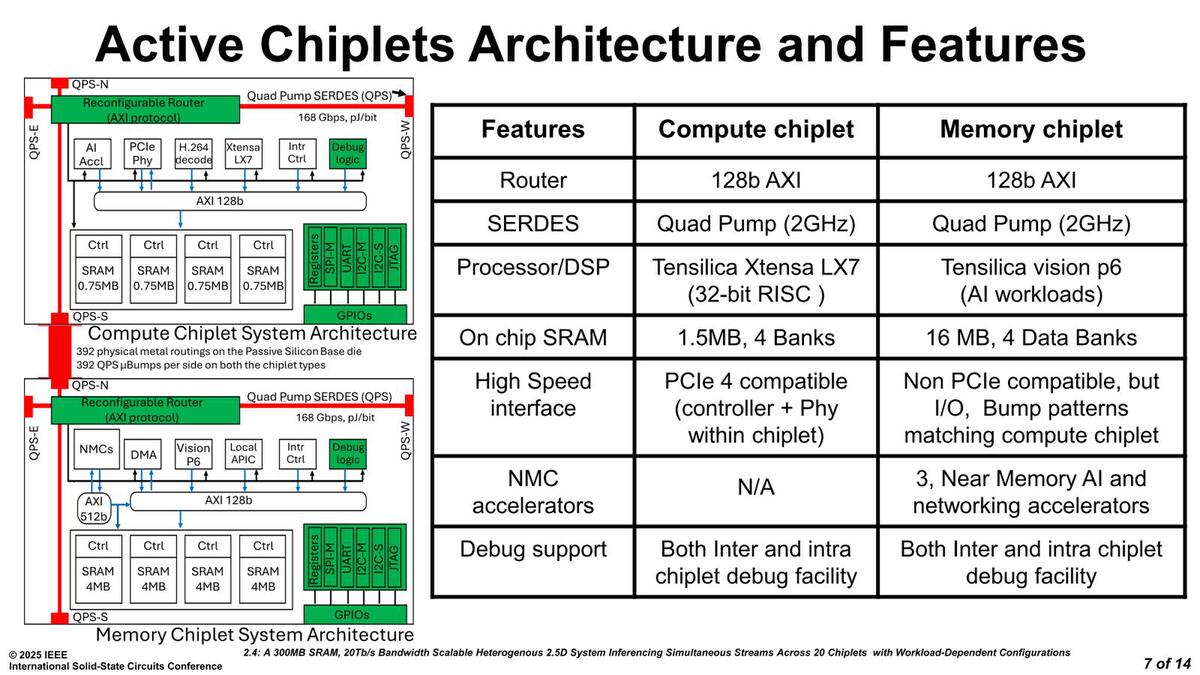
コンピュートタイルとメモリータイルの内部構造。白い部分はTensilicaのIPないしStandard IP(SRAM)を利用し、緑の部分が今回の実装にあたって開発した部分のようだ
またコンピュートタイルに搭載された3MBのSRAMはXtensa LX7 coreを含む128bit AXIの内部バスからのアクセスだけを想定しているが、メモリータイルに搭載されている方は外部のネットワーク経由で直接アクセスすることも想定しているのか、NMC(Near Memory Controller)と呼ばれるアクセラレーターを3基持ち、しかもそのNMCとメモリーの間が512bitのAXIバスでつながっているあたりが、使われ方の違いを表している。
下の画像が実際のプロトタイプの構成である。5×4で20個のタイルが搭載されるが、うちコンピュートタイルが16個、メモリータイルが4つである。
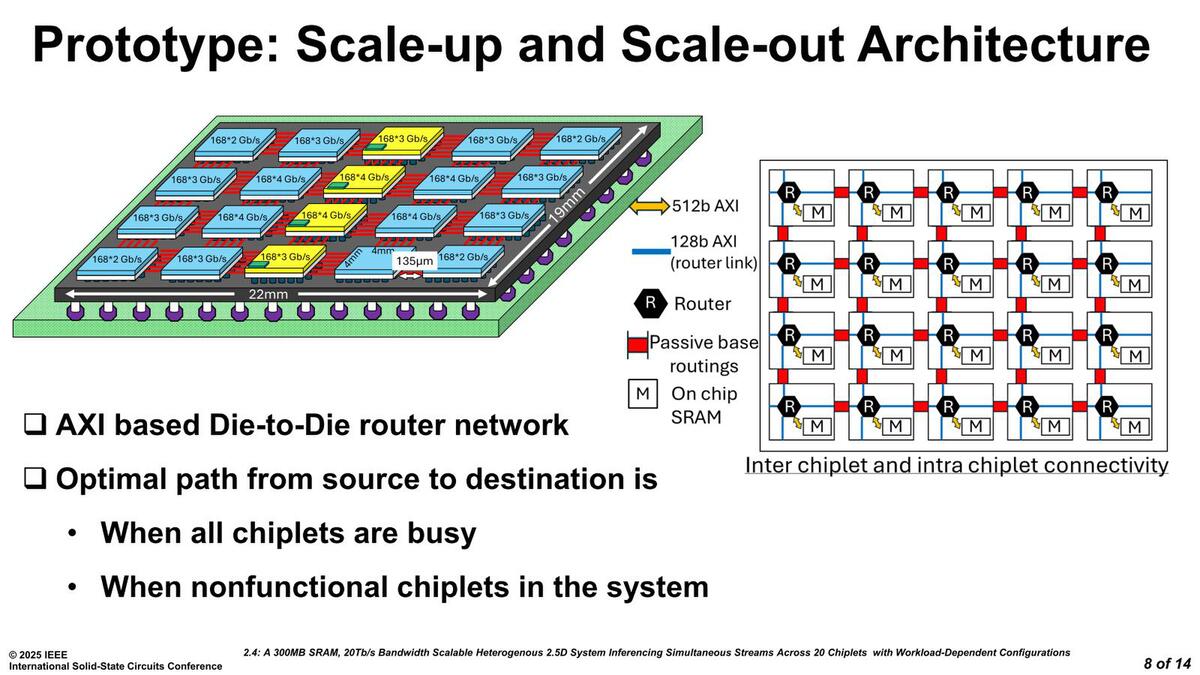
微妙に2つ上の写真とレイアウトが一致していない気がするのだが、これは2つ上の画像が間違っている(Memory ChipletとCompute Chipletが逆)のかもしれない
チップレット同士の間隔は135μmであるが、D2DのPHYは必ずしも4辺にあるわけでなく偏りが見られる。この関係で実際の配線長は、短いもので300μm、長いもので1200μmになる。この配線への制御は各タイルに置かれたルーターが制御する格好になり、チップ内部的には128bit AXIでこれをつないでいる格好らしい。
ところで上の画像の右側を見ると、すべてのタイルでSRAMとルーターが512bit AXIで接続されているようにみえるが、2つ上の内部構造画像では512bit AXIを持つのはメモリータイルだけになっている。
どちらかが間違ってるわけで、なんとなく2つ上の内部構造画像の方がSRAMの接続部に512bit AXIを書き忘れている気もしなくもないが、その512bit AXIの駆動にNMCが必要ということを考えると、上の画像の右図が間違っているようにも思える(2つ上の画像の表に、コンピュートタイルにはNMCアクセラレーターがない、と明記してあるあたりこれは間違いなさそうだ)。
それはともかくとして、このタイル間の接続は1方向あたり168Gbpsになっている。四隅のタイルは168Gbps×2、各辺に配されたタイルは168Gbps×3、そして中にあるタイルは168Gbps×4の帯域を持つことになり、これを合計すると168×(2×4+3×10+4×6)=168×62=10416Gbps。実際にはこれが双方向なので、トータルで20Tbpsとなり、これがタイトルの"20Tb/s Bandwidth"につながるわけだ。
メモリータイルの内部構造が下の画像である。実際には1MBのスライスが4つで1つのバンクを構成、これが4バンクで16MBとなる。
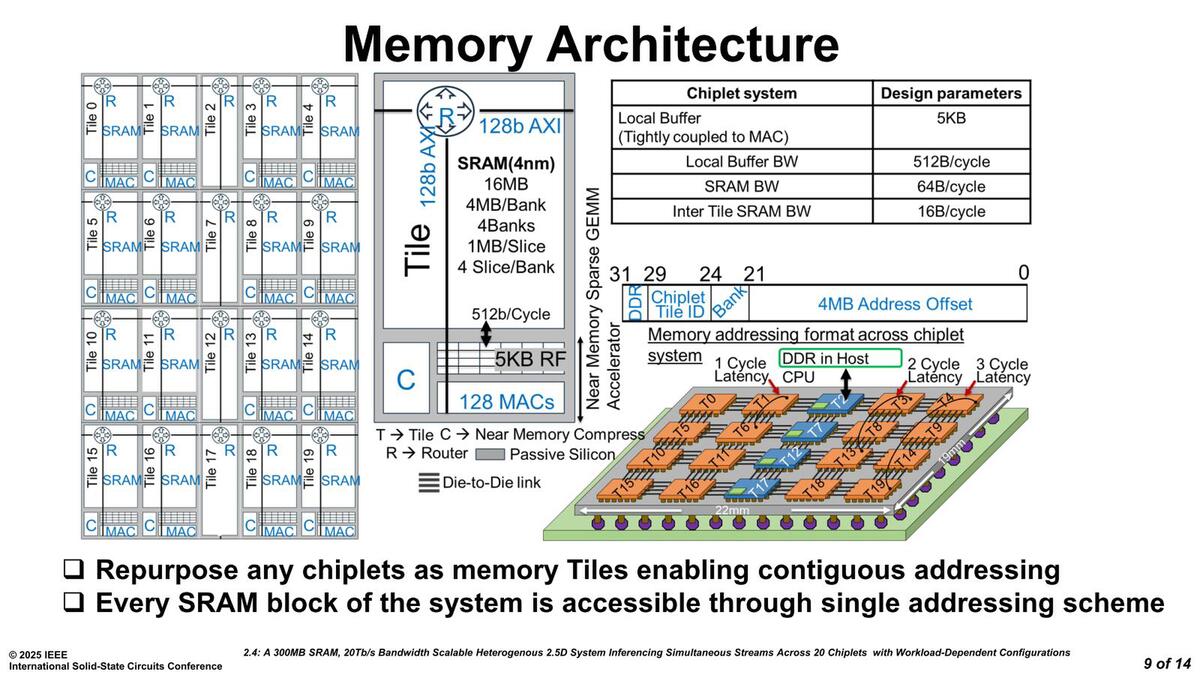
メモリータイルの内部構造。これはUnified Memoryの考え方でもあって、このクラスの規模なら問題ないのだろうが、今後さらにスケールさせようとすると難しいのでは? という気がする
AIエンジン用のレジスターファイルとは512bit/サイクルで接続され、128MACのAIエンジンはこのレジスターファイルを使って処理する。同時にこの16MBのSRAMにはグローバルアドレスが付加されておりこれを利用してXtensa LX7 coreからアクセスすることも可能という仕組みだ。
さすがにこれ単独で動作させるのは難しいので、アプリケーションを実際に走らせる際にはホストが必要になっている。その意味では、これ全体でアクセラレーターみたいなものである。
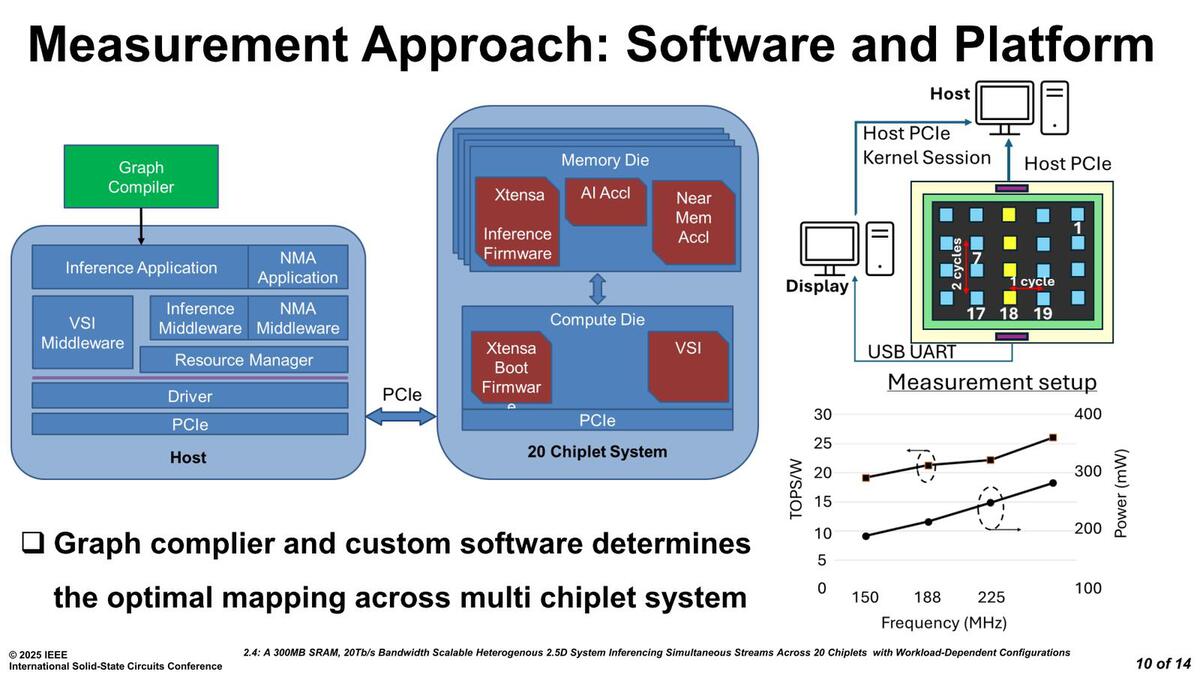
消費電力の縦軸がmWオーダーなことに注意。SerDesは2GHz動作だが、コアそのものは200MHz程度の動作なのでこの程度で収まっているという考え方もある
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります