



ローカルでのAI学習に最適化されたギガバイトのデスクトップPC「AI TOP」。RAGの専門家であるメタデータの野村直之氏とともに、AI TOPのポテンシャルを探ってきた。初期コストとチューニングのしやすさという2つのハードルを越え、ローカルLLMを現実解にできるのか? 両者の邂逅を見届けてもらいたい。

今の生成AIの時代を予見したRAG博士 ナレッジマネジメントにAIの力を
昨年6月に発表されたギガバイトの「AI TOP」は、AI開発に最適なデスクトップPC。6種類のマザーボード、4種類のビデオカード、2種類のSSDが用意され、ユーザーのニーズに合わせて最適な組み合わせでシステムを構築できる。「AI TOP Utility」というAI学習ツールが用意されており、ローカルにおけるAI開発を効率的に行なえる。
そんなAI TOPに興味を持ってくれたのは、「RAG博士」とも言われるメタデータ代表取締役社長の野村直之氏だ。研究者、エンジニア、著者、講師、そして経営者と多彩な顔を持つ野村氏の経歴をざっとおさらいしよう。

メタデータ代表取締役社長 野村直之氏
1984年に東京大学工学部を卒業した野村氏は、2002年に理学博士号を取得。NEC、MIT(マサチューセッツ工科大学)、ジャストシステム、リコーなどでの勤務経験を経て、2005年にメタデータを設立し、AIの研究開発を続けている。著書も数多く、2018年に執筆した「AIに勝つ!」では、「大規模言語モデルが人間の代わりに大量の情報を読みこなして、対話的に要点を教えてくれる」という今の生成AIの隆盛を予言。現在ではAIプロダクトの開発、生成AIについての講演、ビジネス現場での活用支援などを行なっている。
そんな野村氏が長らく注力しているのがナレッジマネジメントの分野だ。多くの企業では事業の急拡大や新規事業の立ち上げ、転職者の増加など、企業では高度なナレッジマネジメントが求められている。しかし、マニュアルは膨大なだけで、内容が古かったり、記述があいまいなことも多い。社内知識がないと読めないことも多く、図表の該当箇所を探すのも大変だったりする。この課題を解決するのがナレッジマネジメントだ。
マニュアルや社内情報・ルールなどから、業務知識やノウハウを抽出するナレッジマネジメントは、生成AIの登場で大きく変化を遂げている。特に検索拡張生成と言われるRAG(Retrieval Augmented Generation)の進化により、ローカルのデータセットと生成AIを組み合わせることで、精度の高い回答を生成できるようになっている。
野村氏のメタデータが開発したRAG向けのチャットボットである「ChatBrid」では、日本語の自然言語処理、データ構造の調整、プロンプトの最適化などを施すことで、ナレッジが大規模化しても、適切な回答を生成できる。チューニングはユーザー自身で行なうことができ、SlackやTeamsなど汎用のチャットから、精度の高い回答を一発で得ることができるという。
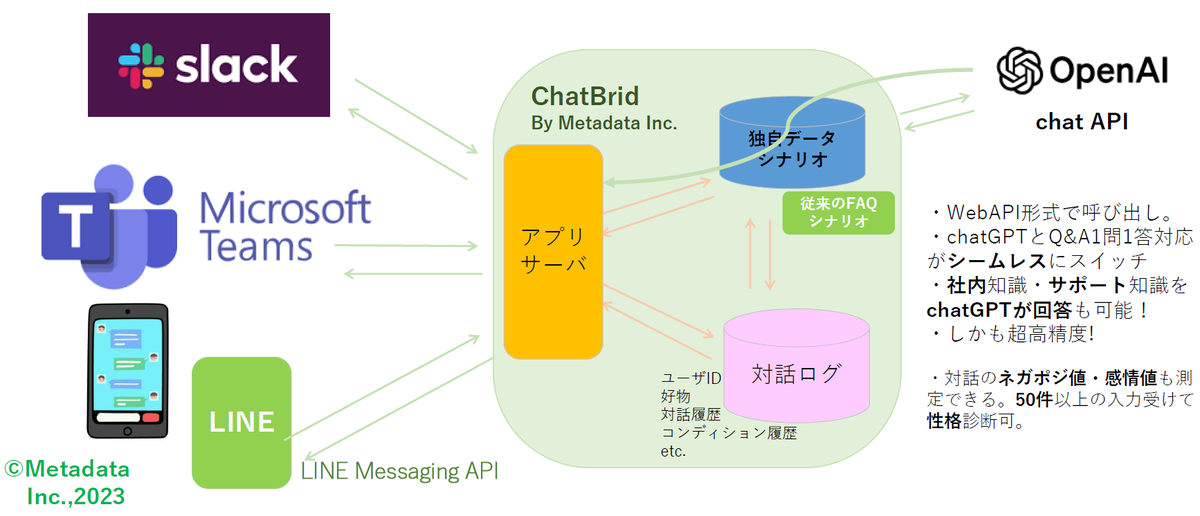
ChatBridのアーキテクチャ
ローカルLLMのメリットはセキュリティだけじゃない
今回、なぜ野村氏がAI TOPに興味を持ったのかというと、オンプレミスでLLMを動かすためのマシンとして利用できないかと考えたからだという。
メタデータのChatBridは初リリースの2023年以来、オンプレミスで動作している。データセットはすべてローカルに溜め、外部のLLMをAPI経由で利用するという形でRAGを構築していたが、現在はオープンなLLMをダウンロードし、オンプレミスで生成AIを動作させている。RAGでの検索対象となるデータセットの格納だけでなく、LLMまでオンプレミスで動作するのがローカルLLM。公開されているローカルLLMの事例としては、都内にある心身障害児総合医療療育センターが業務手順書やヒヤリハットの事例集を、院内のオンプレミスのRAGに取り込んでいるという。
こうしたローカルLLMの構築には、オープンソースのLLMをダウンロードして利用する。OpenAIやClaudeなどのベンダー独自LLMに対し、商用フリーのオープンLLMの代表格がMetaのLlama。最大規模の405B(4050億パラメーター)のほか、中規模な70B(700億パラメーター)、小規模な8B(80億パラメーター)などが用意されており、日本語を追加学習したモデルも用意されている。Llamaを代表とするオープンなLLMは昨今急速に精度が向上されており、利用が現実的になっている。
クローズドな環境でオープンなLLMを利用できるローカルLLMの最大のメリットは、社内情報が外に出ないというセキュリティ面が大きい。病院、官公庁、知財や個人情報を扱う会社の場合、クラウドが利用できず、いまだにオンプレミスでの運用は多い。ローカルLLMでも、データを外に出さず、生成AIのメリットを享受することができる。
また、APIを利用しないため、ランニングコストも安くなる(もちろんマシンの電気代はかかる)。当然、APIを提供する事業者の都合に振り回されることもない。ライセンス条件やポリシーの変更、LLMのバージョンアップや更新、値上げなどのリスクも回避できる。他ユーザーの利用で性能が大幅に低下することもない。「事実として2023年の6月~11月にGPT3.5 Turboは約1/60に速度低下しました。2秒でレスポンスが返ってくるはずが、2分かかってしまう。これじゃあ商品になりませんよね。質問下手な日本人の曖昧な、意図不明な質問を大量に浴びて精度が低下したきらいもありました」と野村氏は語る。
さらに、応答速度や精度をチューニングできる余地も大きい。これはAI TOPの利用に関わってくるのだが、オープンLLMであれば、パラメーター数、モデルの構造、バッチサイズ、モデルやパイプラインの並列化など、さまざまな領域でチューニングを施すことができる。ユーザーに最適なLLMを構築し、安定した性能で運用し、改善を続けていけるわけだ。
こうしたローカルLLMを実現するためのマシンとして、果たしてAI TOPは十分なコストパフォーマンスを持っているのか。そして、AI TOP Utilityでのチューニングは果たして使いやすいのか? 前置きが長くなったが、野村氏とASCIIの大谷が日本の全AI開発者の代表として、本国から来たAI TOPの関係者が待ち受けるギガバイトオフィスに出向いて、製品の説明を聞くことになった。
週刊アスキーの最新情報を購読しよう